In [1]: import pandas as pd
In [2]: import matplotlib.pyplot as plt
-
大気質データ
In [3]: air_quality = pd.read_csv("data/air_quality_no2_long.csv") In [4]: air_quality = air_quality.rename(columns={"date.utc": "datetime"}) In [5]: air_quality.head() Out[5]: city country datetime location parameter value unit 0 Paris FR 2019-06-21 00:00:00+00:00 FR04014 no2 20.0 µg/m³ 1 Paris FR 2019-06-20 23:00:00+00:00 FR04014 no2 21.8 µg/m³ 2 Paris FR 2019-06-20 22:00:00+00:00 FR04014 no2 26.5 µg/m³ 3 Paris FR 2019-06-20 21:00:00+00:00 FR04014 no2 24.9 µg/m³ 4 Paris FR 2019-06-20 20:00:00+00:00 FR04014 no2 21.4 µg/m³
In [6]: air_quality.city.unique() Out[6]: array(['Paris', 'Antwerpen', 'London'], dtype=object)
時系列データを簡単に扱う方法#
pandas の datetime プロパティの使用#
datetime列の日付を、プレーンテキストではなく datetime オブジェクトとして扱いたいIn [7]: air_quality["datetime"] = pd.to_datetime(air_quality["datetime"]) In [8]: air_quality["datetime"] Out[8]: 0 2019-06-21 00:00:00+00:00 1 2019-06-20 23:00:00+00:00 2 2019-06-20 22:00:00+00:00 3 2019-06-20 21:00:00+00:00 4 2019-06-20 20:00:00+00:00 ... 2063 2019-05-07 06:00:00+00:00 2064 2019-05-07 04:00:00+00:00 2065 2019-05-07 03:00:00+00:00 2066 2019-05-07 02:00:00+00:00 2067 2019-05-07 01:00:00+00:00 Name: datetime, Length: 2068, dtype: datetime64[ns, UTC]
当初、
datetimeの値は文字列であり、いかなる datetime 操作 (例: 年、曜日などを抽出する) も提供しません。to_datetime関数を適用することで、pandas は文字列を解釈し、これらを datetime (つまりdatetime64[ns, UTC]) オブジェクトに変換します。pandas では、これらの datetime オブジェクトを標準ライブラリのdatetime.datetimeと同様にpandas.Timestampと呼びます。
注
多くのデータセットは列の1つに datetime 情報を含んでいるため、pandas.read_csv() や pandas.read_json() のような pandas の入力関数は、parse_dates パラメータに Timestamp として読み込む列のリストを指定することで、データを読み込む際に日付への変換を行うことができます。
pd.read_csv("../data/air_quality_no2_long.csv", parse_dates=["datetime"])
これらの pandas.Timestamp オブジェクトが役立つのはなぜでしょうか?いくつかの例でその付加価値を説明しましょう。
作業している時系列データセットの開始日と終了日はいつですか?
In [9]: air_quality["datetime"].min(), air_quality["datetime"].max()
Out[9]:
(Timestamp('2019-05-07 01:00:00+0000', tz='UTC'),
Timestamp('2019-06-21 00:00:00+0000', tz='UTC'))
日付に pandas.Timestamp を使用することで、日付情報を計算したり比較したりすることができます。したがって、これを使用して時系列の長さを取得できます。
In [10]: air_quality["datetime"].max() - air_quality["datetime"].min()
Out[10]: Timedelta('44 days 23:00:00')
結果は、標準 Python ライブラリの datetime.timedelta と同様の pandas.Timedelta オブジェクトであり、時間間隔を定義します。
pandas がサポートする様々な時間概念は、時間関連の概念 に関するユーザーガイドのセクションで説明されています。
測定月のデータのみを含む新しい列を
DataFrameに追加したいIn [11]: air_quality["month"] = air_quality["datetime"].dt.month In [12]: air_quality.head() Out[12]: city country datetime ... value unit month 0 Paris FR 2019-06-21 00:00:00+00:00 ... 20.0 µg/m³ 6 1 Paris FR 2019-06-20 23:00:00+00:00 ... 21.8 µg/m³ 6 2 Paris FR 2019-06-20 22:00:00+00:00 ... 26.5 µg/m³ 6 3 Paris FR 2019-06-20 21:00:00+00:00 ... 24.9 µg/m³ 6 4 Paris FR 2019-06-20 20:00:00+00:00 ... 21.4 µg/m³ 6 [5 rows x 8 columns]
日付に
Timestampオブジェクトを使用することで、多くの時間関連プロパティが pandas によって提供されます。例えばmonthの他に、year、quarterなどがあります。これらのすべてのプロパティはdtアクセサを通じてアクセス可能です。
既存の日付プロパティの概要は、時刻と日付のコンポーネント概要表 に示されています。datetime のようなプロパティを返す dt アクセサに関する詳細については、dt アクセサ の専用セクションで説明されています。
各測定場所における曜日ごとの平均 \(NO_2\) 濃度はどのくらいですか?
In [13]: air_quality.groupby( ....: [air_quality["datetime"].dt.weekday, "location"])["value"].mean() ....: Out[13]: datetime location 0 BETR801 27.875000 FR04014 24.856250 London Westminster 23.969697 1 BETR801 22.214286 FR04014 30.999359 ... 5 FR04014 25.266154 London Westminster 24.977612 6 BETR801 21.896552 FR04014 23.274306 London Westminster 24.859155 Name: value, Length: 21, dtype: float64
統計計算に関するチュートリアル で提供された
groupbyによる分割-適用-結合パターンを覚えていますか?ここでは、各曜日ごと、そして各測定場所ごとに、指定された統計量 (例: \(NO_2\) の平均) を計算したいと考えています。曜日でグループ化するには、pandas のTimestampの datetime プロパティであるweekday(月曜日=0、日曜日=6) を使用します。これもdtアクセサでアクセスできます。場所と曜日の両方でグループ化することで、これらの各組み合わせで平均の計算を分割することができます。注意
これらの例では非常に短い時系列データを使用しているため、分析結果は長期的な代表性のある結果を提供するものではありません!
すべてのステーションを合わせた時系列データの日中の典型的な \(NO_2\) パターンをプロットします。言い換えれば、各時間帯の平均値はどのくらいですか?
In [14]: fig, axs = plt.subplots(figsize=(12, 4)) In [15]: air_quality.groupby(air_quality["datetime"].dt.hour)["value"].mean().plot( ....: kind='bar', rot=0, ax=axs ....: ) ....: Out[15]: <Axes: xlabel='datetime'> In [16]: plt.xlabel("Hour of the day"); # custom x label using Matplotlib In [17]: plt.ylabel("$NO_2 (µg/m^3)$");
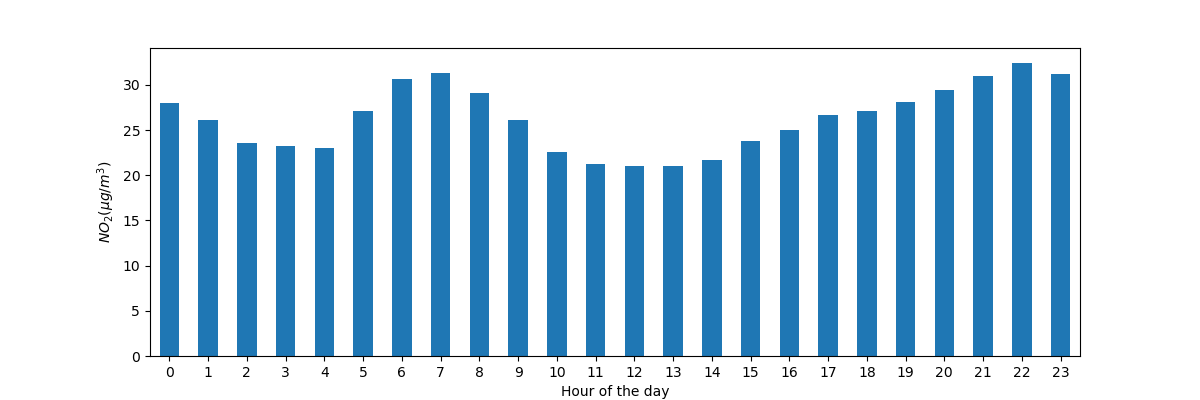
前のケースと同様に、**1日の各時間ごと**に所定の統計量(例:平均\(NO_2\))を計算したいので、再び分割・適用・結合のアプローチを使用できます。この場合、pandasの
Timestampのdatetimeプロパティhourを使用します。これはdtアクセサでもアクセス可能です。
インデックスとしての datetime#
再形成に関するチュートリアル で、各測定場所を別々の列としてデータテーブルを再形成するために pivot() が紹介されました。
In [18]: no_2 = air_quality.pivot(index="datetime", columns="location", values="value")
In [19]: no_2.head()
Out[19]:
location BETR801 FR04014 London Westminster
datetime
2019-05-07 01:00:00+00:00 50.5 25.0 23.0
2019-05-07 02:00:00+00:00 45.0 27.7 19.0
2019-05-07 03:00:00+00:00 NaN 50.4 19.0
2019-05-07 04:00:00+00:00 NaN 61.9 16.0
2019-05-07 05:00:00+00:00 NaN 72.4 NaN
注
データをピボットすることで、datetime 情報がテーブルのインデックスになりました。一般的に、列をインデックスに設定するには set_index 関数を使用できます。
datetime インデックス (つまり DatetimeIndex) を使用すると、強力な機能が提供されます。例えば、時系列プロパティを取得するために dt アクセサは必要なく、これらのプロパティはインデックスで直接利用できます。
In [20]: no_2.index.year, no_2.index.weekday
Out[20]:
(Index([2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019,
...
2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019],
dtype='int32', name='datetime', length=1033),
Index([1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
...
3, 3, 3, 3, 3, 3, 3, 3, 3, 4],
dtype='int32', name='datetime', length=1033))
その他の利点としては、特定の期間のデータ抽出が便利になったり、プロット上の時間軸が調整されたりすることです。これをデータに適用してみましょう。
5月20日から5月21日の終わりまでの各ステーションにおける \(NO_2\) 値のプロットを作成します。
In [21]: no_2["2019-05-20":"2019-05-21"].plot();
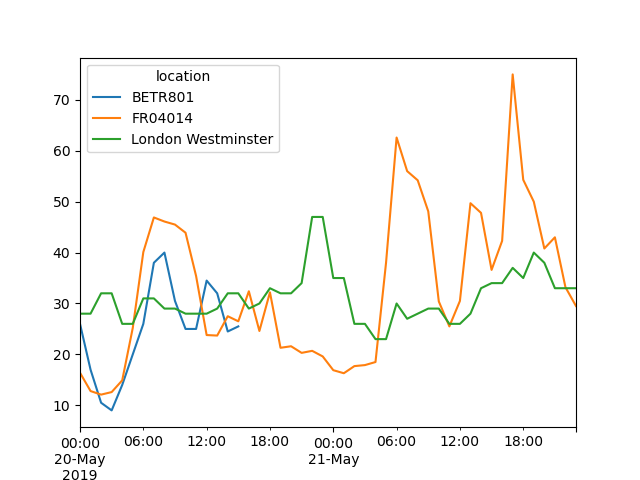
datetime にパースできる文字列を提供することで、
DatetimeIndex上でデータの特定の部分を選択できます。
DatetimeIndex と文字列を使用したスライスに関する詳細情報は、時系列インデックス付け のセクションで提供されています。
時系列データを別の頻度にリサンプリングする#
現在の時間単位の時系列値を、各ステーションにおける月ごとの最大値に集計します。
In [22]: monthly_max = no_2.resample("ME").max() In [23]: monthly_max Out[23]: location BETR801 FR04014 London Westminster datetime 2019-05-31 00:00:00+00:00 74.5 97.0 97.0 2019-06-30 00:00:00+00:00 52.5 84.7 52.0
datetime インデックスを持つ時系列データにおける非常に強力なメソッドは、時系列を別の頻度(例:秒単位のデータを5分単位のデータに変換する)に
resample()する機能です。
resample() メソッドは groupby 操作に似ています
これは、目標の頻度を定義する文字列 (例:
M,5Hなど) を使用して、時間ベースのグループ化を提供します。これは、
mean、maxなどの集約関数を必要とします。
時系列の頻度を定義するために使用されるエイリアスの概要は、オフセットエイリアス概要表 に示されています。
定義されると、時系列の頻度は freq 属性によって提供されます。
In [24]: monthly_max.index.freq
Out[24]: <MonthEnd>
各観測所の日平均 \(NO_2\) 値のプロットを作成します。
In [25]: no_2.resample("D").mean().plot(style="-o", figsize=(10, 5));
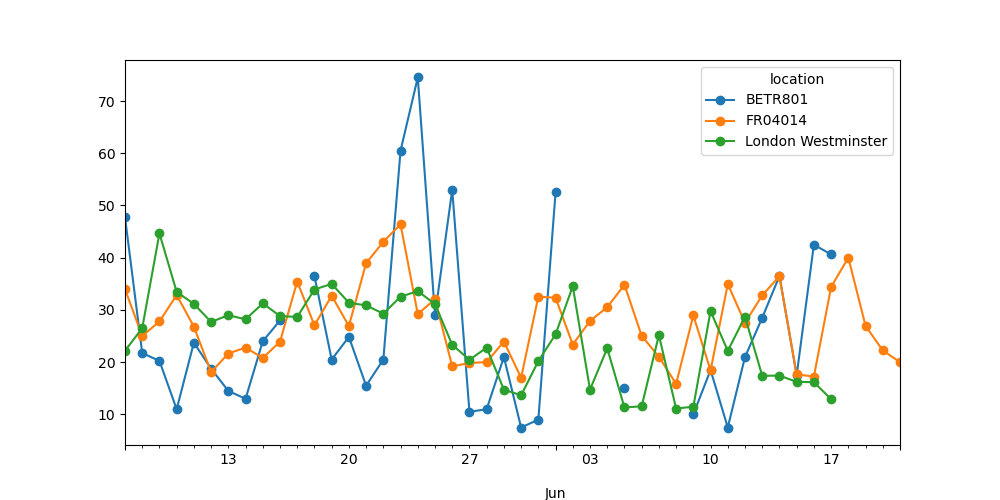
時系列 リサンプリング の強力さに関する詳細は、リサンプリング に関するユーザーガイドのセクションで提供されています。
覚えておいてください
有効な日付文字列は、
to_datetime関数を使用するか、読み取り関数の一部として datetime オブジェクトに変換できます。pandas の datetime オブジェクトは、
dtアクセサを使用して、計算、論理演算、および便利な日付関連プロパティをサポートします。DatetimeIndexはこれらの日付関連プロパティを含み、便利なスライスをサポートします。Resampleは、時系列の頻度を変更するための強力なメソッドです。
時系列に関する完全な概要は、時系列と日付機能 のページに記載されています。