グループ化: 分割-適用-結合#
「グループ化」とは、以下の1つ以上のステップを含むプロセスを指します。
ある基準に基づいてデータをグループに**分割**する。
各グループに**独立して**関数を適用する。
結果をデータ構造に**結合**する。
これらのうち、分割ステップが最も簡単です。適用ステップでは、以下のいずれかを実行したい場合があります。
**集計**: 各グループの要約統計量 (または統計量) を計算します。例:
グループの合計または平均を計算する。
グループのサイズ/カウントを計算する。
**変換**: グループ固有の計算を実行し、同じインデックスのオブジェクトを返します。例:
グループ内でデータを標準化する (zscore)。
各グループから導き出された値でグループ内のNAを埋める。
**フィルタリング**: グループごとの計算結果がTrueまたはFalseになるように、一部のグループを破棄します。例:
メンバーが少ないグループに属するデータを破棄する。
グループの合計または平均に基づいてデータをフィルタリングする。
これらの操作の多くはGroupByオブジェクトで定義されています。これらの操作は、集計API、ウィンドウAPI、およびリサンプルAPIの操作に似ています。
特定の操作がこれらのカテゴリのいずれにも当てはまらない、またはそれらの組み合わせである可能性があります。そのような場合、GroupByのapplyメソッドを使用して操作を計算できる場合があります。このメソッドは、適用ステップの結果を調べ、上記の3つのカテゴリのいずれにも当てはまらない場合、それらを単一の結果にうまく結合しようとします。
注
組み込みのGroupBy操作を使用して複数のステップに分割された操作は、ユーザー定義のPython関数をapplyメソッドで使用するよりも効率的です。
GroupByという名前は、SQLベースのツール (またはitertools) を使用したことがある人にはかなり馴染みがあるはずです。そこでは、次のようなコードを書くことができます。
SELECT Column1, Column2, mean(Column3), sum(Column4)
FROM SomeTable
GROUP BY Column1, Column2
pandasを使用して、このような操作を自然に、簡単に表現できるようにすることを目指しています。GroupBy機能の各領域について説明し、その後、いくつかの非自明な例/ユースケースを提供します。
いくつかの高度な戦略については、クックブックを参照してください。
オブジェクトをグループに分割する#
グループ化の抽象的な定義は、ラベルからグループ名へのマッピングを提供することです。GroupByオブジェクトを作成するには(GroupByオブジェクトが何であるかは後で詳しく説明します)、次のことができます。
In [1]: speeds = pd.DataFrame(
...: [
...: ("bird", "Falconiformes", 389.0),
...: ("bird", "Psittaciformes", 24.0),
...: ("mammal", "Carnivora", 80.2),
...: ("mammal", "Primates", np.nan),
...: ("mammal", "Carnivora", 58),
...: ],
...: index=["falcon", "parrot", "lion", "monkey", "leopard"],
...: columns=("class", "order", "max_speed"),
...: )
...:
In [2]: speeds
Out[2]:
class order max_speed
falcon bird Falconiformes 389.0
parrot bird Psittaciformes 24.0
lion mammal Carnivora 80.2
monkey mammal Primates NaN
leopard mammal Carnivora 58.0
In [3]: grouped = speeds.groupby("class")
In [4]: grouped = speeds.groupby(["class", "order"])
マッピングはさまざまな方法で指定できます。
各インデックスラベルで呼び出されるPython関数。
インデックスと同じ長さのリストまたはNumPy配列。
label -> group nameマッピングを提供するdictまたはSeries。DataFrameオブジェクトの場合、グループ化に使用する列名またはインデックスレベル名を示す文字列。上記のいずれかのもののリスト。
グループ化オブジェクトを総称して**キー**と呼びます。たとえば、次のDataFrameを考えます。
注
groupbyに渡される文字列は、列またはインデックスレベルのいずれかを指すことができます。文字列が列名とインデックスレベル名の両方に一致する場合、ValueErrorが発生します。
In [5]: df = pd.DataFrame(
...: {
...: "A": ["foo", "bar", "foo", "bar", "foo", "bar", "foo", "foo"],
...: "B": ["one", "one", "two", "three", "two", "two", "one", "three"],
...: "C": np.random.randn(8),
...: "D": np.random.randn(8),
...: }
...: )
...:
In [6]: df
Out[6]:
A B C D
0 foo one 0.469112 -0.861849
1 bar one -0.282863 -2.104569
2 foo two -1.509059 -0.494929
3 bar three -1.135632 1.071804
4 foo two 1.212112 0.721555
5 bar two -0.173215 -0.706771
6 foo one 0.119209 -1.039575
7 foo three -1.044236 0.271860
DataFrameでGroupByオブジェクトを取得するには、groupby()を呼び出します。このメソッドはpandas.api.typing.DataFrameGroupByインスタンスを返します。A列またはB列、あるいはその両方で自然にグループ化できます。
In [7]: grouped = df.groupby("A")
In [8]: grouped = df.groupby("B")
In [9]: grouped = df.groupby(["A", "B"])
注
df.groupby('A')はdf.groupby(df['A'])の糖衣構文にすぎません。
列AとBにMultiIndexがある場合、指定した列以外すべての列でグループ化できます。
In [10]: df2 = df.set_index(["A", "B"])
In [11]: grouped = df2.groupby(level=df2.index.names.difference(["B"]))
In [12]: grouped.sum()
Out[12]:
C D
A
bar -1.591710 -1.739537
foo -0.752861 -1.402938
上記のGroupByは、そのインデックス(行)でDataFrameを分割します。列で分割するには、まず転置を実行します。
In [13]: def get_letter_type(letter):
....: if letter.lower() in 'aeiou':
....: return 'vowel'
....: else:
....: return 'consonant'
....:
In [14]: grouped = df.T.groupby(get_letter_type)
pandasのIndexオブジェクトは重複する値をサポートします。重複しないインデックスがgroupby操作でグループキーとして使用される場合、同じインデックス値のすべての値は1つのグループにあると見なされるため、集計関数の出力には一意のインデックス値のみが含まれます。
In [15]: index = [1, 2, 3, 1, 2, 3]
In [16]: s = pd.Series([1, 2, 3, 10, 20, 30], index=index)
In [17]: s
Out[17]:
1 1
2 2
3 3
1 10
2 20
3 30
dtype: int64
In [18]: grouped = s.groupby(level=0)
In [19]: grouped.first()
Out[19]:
1 1
2 2
3 3
dtype: int64
In [20]: grouped.last()
Out[20]:
1 10
2 20
3 30
dtype: int64
In [21]: grouped.sum()
Out[21]:
1 11
2 22
3 33
dtype: int64
**必要になるまで**は**分割は行われない**ことに注意してください。GroupByオブジェクトを作成するだけでは、有効なマッピングを渡したかどうかを確認するだけです。
注
多くの種類の複雑なデータ操作は、GroupBy操作の観点から表現できます(ただし、最も効率的な実装であることは保証できません)。ラベルマッピング関数をかなり工夫できます。
GroupByのソート#
デフォルトでは、groupby操作中にグループキーがソートされます。ただし、潜在的な速度向上のためにsort=Falseを渡すことができます。sort=Falseの場合、グループキー間の順序は元のデータフレームでのキーの出現順序に従います。
In [22]: df2 = pd.DataFrame({"X": ["B", "B", "A", "A"], "Y": [1, 2, 3, 4]})
In [23]: df2.groupby(["X"]).sum()
Out[23]:
Y
X
A 7
B 3
In [24]: df2.groupby(["X"], sort=False).sum()
Out[24]:
Y
X
B 3
A 7
groupbyは、各グループ**内**でソートされる**観測値**の順序を保持することに注意してください。たとえば、以下のgroupby()によって作成されたグループは、元のDataFrameに表示された順序になっています。
In [25]: df3 = pd.DataFrame({"X": ["A", "B", "A", "B"], "Y": [1, 4, 3, 2]})
In [26]: df3.groupby("X").get_group("A")
Out[26]:
X Y
0 A 1
2 A 3
In [27]: df3.groupby(["X"]).get_group(("B",))
Out[27]:
X Y
1 B 4
3 B 2
GroupBy dropna#
デフォルトでは、groupby操作中、グループキーからNA値は除外されます。ただし、グループキーにNA値を含めたい場合は、dropna=Falseを渡すことで実現できます。
In [28]: df_list = [[1, 2, 3], [1, None, 4], [2, 1, 3], [1, 2, 2]]
In [29]: df_dropna = pd.DataFrame(df_list, columns=["a", "b", "c"])
In [30]: df_dropna
Out[30]:
a b c
0 1 2.0 3
1 1 NaN 4
2 2 1.0 3
3 1 2.0 2
# Default ``dropna`` is set to True, which will exclude NaNs in keys
In [31]: df_dropna.groupby(by=["b"], dropna=True).sum()
Out[31]:
a c
b
1.0 2 3
2.0 2 5
# In order to allow NaN in keys, set ``dropna`` to False
In [32]: df_dropna.groupby(by=["b"], dropna=False).sum()
Out[32]:
a c
b
1.0 2 3
2.0 2 5
NaN 1 4
dropna引数のデフォルト設定はTrueであり、これはNAがグループキーに含まれないことを意味します。
GroupByオブジェクトの属性#
groups属性は、計算された一意のグループをキーとし、対応する値が各グループに属する軸ラベルである辞書です。上記の例では、次のようになります。
In [33]: df.groupby("A").groups
Out[33]: {'bar': [1, 3, 5], 'foo': [0, 2, 4, 6, 7]}
In [34]: df.T.groupby(get_letter_type).groups
Out[34]: {'consonant': ['B', 'C', 'D'], 'vowel': ['A']}
GroupByオブジェクトに対して標準的なPythonのlen関数を呼び出すと、グループの数が返されます。これは、groups辞書の長さと同じです。
In [35]: grouped = df.groupby(["A", "B"])
In [36]: grouped.groups
Out[36]: {('bar', 'one'): [1], ('bar', 'three'): [3], ('bar', 'two'): [5], ('foo', 'one'): [0, 6], ('foo', 'three'): [7], ('foo', 'two'): [2, 4]}
In [37]: len(grouped)
Out[37]: 6
GroupByは、列名、GroupBy操作、およびその他の属性のタブ補完を行います。
In [38]: n = 10
In [39]: weight = np.random.normal(166, 20, size=n)
In [40]: height = np.random.normal(60, 10, size=n)
In [41]: time = pd.date_range("1/1/2000", periods=n)
In [42]: gender = np.random.choice(["male", "female"], size=n)
In [43]: df = pd.DataFrame(
....: {"height": height, "weight": weight, "gender": gender}, index=time
....: )
....:
In [44]: df
Out[44]:
height weight gender
2000-01-01 42.849980 157.500553 male
2000-01-02 49.607315 177.340407 male
2000-01-03 56.293531 171.524640 male
2000-01-04 48.421077 144.251986 female
2000-01-05 46.556882 152.526206 male
2000-01-06 68.448851 168.272968 female
2000-01-07 70.757698 136.431469 male
2000-01-08 58.909500 176.499753 female
2000-01-09 76.435631 174.094104 female
2000-01-10 45.306120 177.540920 male
In [45]: gb = df.groupby("gender")
In [46]: gb.<TAB> # noqa: E225, E999
gb.agg gb.boxplot gb.cummin gb.describe gb.filter gb.get_group gb.height gb.last gb.median gb.ngroups gb.plot gb.rank gb.std gb.transform
gb.aggregate gb.count gb.cumprod gb.dtype gb.first gb.groups gb.hist gb.max gb.min gb.nth gb.prod gb.resample gb.sum gb.var
gb.apply gb.cummax gb.cumsum gb.fillna gb.gender gb.head gb.indices gb.mean gb.name gb.ohlc gb.quantile gb.size gb.tail gb.weight
MultiIndexによるグループ化#
階層的にインデックス付けされたデータの場合、階層のレベルの1つでグループ化するのはごく自然なことです。
2レベルのMultiIndexを持つSeriesを作成してみましょう。
In [47]: arrays = [
....: ["bar", "bar", "baz", "baz", "foo", "foo", "qux", "qux"],
....: ["one", "two", "one", "two", "one", "two", "one", "two"],
....: ]
....:
In [48]: index = pd.MultiIndex.from_arrays(arrays, names=["first", "second"])
In [49]: s = pd.Series(np.random.randn(8), index=index)
In [50]: s
Out[50]:
first second
bar one -0.919854
two -0.042379
baz one 1.247642
two -0.009920
foo one 0.290213
two 0.495767
qux one 0.362949
two 1.548106
dtype: float64
次に、sのレベルの1つでグループ化できます。
In [51]: grouped = s.groupby(level=0)
In [52]: grouped.sum()
Out[52]:
first
bar -0.962232
baz 1.237723
foo 0.785980
qux 1.911055
dtype: float64
MultiIndexに名前が指定されている場合、レベル番号の代わりにそれらの名前を渡すことができます。
In [53]: s.groupby(level="second").sum()
Out[53]:
second
one 0.980950
two 1.991575
dtype: float64
複数のレベルでのグループ化がサポートされています。
In [54]: arrays = [
....: ["bar", "bar", "baz", "baz", "foo", "foo", "qux", "qux"],
....: ["doo", "doo", "bee", "bee", "bop", "bop", "bop", "bop"],
....: ["one", "two", "one", "two", "one", "two", "one", "two"],
....: ]
....:
In [55]: index = pd.MultiIndex.from_arrays(arrays, names=["first", "second", "third"])
In [56]: s = pd.Series(np.random.randn(8), index=index)
In [57]: s
Out[57]:
first second third
bar doo one -1.131345
two -0.089329
baz bee one 0.337863
two -0.945867
foo bop one -0.932132
two 1.956030
qux bop one 0.017587
two -0.016692
dtype: float64
In [58]: s.groupby(level=["first", "second"]).sum()
Out[58]:
first second
bar doo -1.220674
baz bee -0.608004
foo bop 1.023898
qux bop 0.000895
dtype: float64
インデックスレベル名はキーとして指定できます。
In [59]: s.groupby(["first", "second"]).sum()
Out[59]:
first second
bar doo -1.220674
baz bee -0.608004
foo bop 1.023898
qux bop 0.000895
dtype: float64
sum関数と集計については後述します。
インデックスレベルと列によるDataFrameのグループ化#
DataFrameは、列とインデックスレベルの組み合わせでグループ化できます。列名とインデックス名の両方を指定することも、Grouperを使用することもできます。
まず、MultiIndexを持つDataFrameを作成してみましょう。
In [60]: arrays = [
....: ["bar", "bar", "baz", "baz", "foo", "foo", "qux", "qux"],
....: ["one", "two", "one", "two", "one", "two", "one", "two"],
....: ]
....:
In [61]: index = pd.MultiIndex.from_arrays(arrays, names=["first", "second"])
In [62]: df = pd.DataFrame({"A": [1, 1, 1, 1, 2, 2, 3, 3], "B": np.arange(8)}, index=index)
In [63]: df
Out[63]:
A B
first second
bar one 1 0
two 1 1
baz one 1 2
two 1 3
foo one 2 4
two 2 5
qux one 3 6
two 3 7
次に、dfを2番目のインデックスレベルとA列でグループ化します。
In [64]: df.groupby([pd.Grouper(level=1), "A"]).sum()
Out[64]:
B
second A
one 1 2
2 4
3 6
two 1 4
2 5
3 7
インデックスレベルは名前でも指定できます。
In [65]: df.groupby([pd.Grouper(level="second"), "A"]).sum()
Out[65]:
B
second A
one 1 2
2 4
3 6
two 1 4
2 5
3 7
インデックスレベル名は、groupbyに直接キーとして指定できます。
In [66]: df.groupby(["second", "A"]).sum()
Out[66]:
B
second A
one 1 2
2 4
3 6
two 1 4
2 5
3 7
GroupByでのDataFrameの列選択#
DataFrameからGroupByオブジェクトを作成したら、各列に対して異なることを行いたい場合があります。したがって、DataFrameから列を取得するのと同様の方法でGroupByオブジェクトに[]を使用することで、次のことができます。
In [67]: df = pd.DataFrame(
....: {
....: "A": ["foo", "bar", "foo", "bar", "foo", "bar", "foo", "foo"],
....: "B": ["one", "one", "two", "three", "two", "two", "one", "three"],
....: "C": np.random.randn(8),
....: "D": np.random.randn(8),
....: }
....: )
....:
In [68]: df
Out[68]:
A B C D
0 foo one -0.575247 1.346061
1 bar one 0.254161 1.511763
2 foo two -1.143704 1.627081
3 bar three 0.215897 -0.990582
4 foo two 1.193555 -0.441652
5 bar two -0.077118 1.211526
6 foo one -0.408530 0.268520
7 foo three -0.862495 0.024580
In [69]: grouped = df.groupby(["A"])
In [70]: grouped_C = grouped["C"]
In [71]: grouped_D = grouped["D"]
これは、より冗長な代替手段の単なる糖衣構文です。
In [72]: df["C"].groupby(df["A"])
Out[72]: <pandas.core.groupby.generic.SeriesGroupBy object at 0x7f945c0eacb0>
さらに、この方法では、渡されたキーから派生した内部グループ化情報を再計算する必要がありません。
操作したい場合は、グループ化列を含めることもできます。
In [73]: grouped[["A", "B"]].sum()
Out[73]:
A B
A
bar barbarbar onethreetwo
foo foofoofoofoofoo onetwotwoonethree
グループのイテレーション#
GroupByオブジェクトがあれば、グループ化されたデータのイテレーションは非常に自然であり、itertools.groupby()と同様に機能します。
In [74]: grouped = df.groupby('A')
In [75]: for name, group in grouped:
....: print(name)
....: print(group)
....:
bar
A B C D
1 bar one 0.254161 1.511763
3 bar three 0.215897 -0.990582
5 bar two -0.077118 1.211526
foo
A B C D
0 foo one -0.575247 1.346061
2 foo two -1.143704 1.627081
4 foo two 1.193555 -0.441652
6 foo one -0.408530 0.268520
7 foo three -0.862495 0.024580
複数のキーでグループ化する場合、グループ名はタプルになります。
In [76]: for name, group in df.groupby(['A', 'B']):
....: print(name)
....: print(group)
....:
('bar', 'one')
A B C D
1 bar one 0.254161 1.511763
('bar', 'three')
A B C D
3 bar three 0.215897 -0.990582
('bar', 'two')
A B C D
5 bar two -0.077118 1.211526
('foo', 'one')
A B C D
0 foo one -0.575247 1.346061
6 foo one -0.408530 0.268520
('foo', 'three')
A B C D
7 foo three -0.862495 0.02458
('foo', 'two')
A B C D
2 foo two -1.143704 1.627081
4 foo two 1.193555 -0.441652
グループのイテレーションを参照してください。
グループの選択#
単一のグループは、DataFrameGroupBy.get_group()を使用して選択できます。
In [77]: grouped.get_group("bar")
Out[77]:
A B C D
1 bar one 0.254161 1.511763
3 bar three 0.215897 -0.990582
5 bar two -0.077118 1.211526
または、複数の列でグループ化されたオブジェクトの場合。
In [78]: df.groupby(["A", "B"]).get_group(("bar", "one"))
Out[78]:
A B C D
1 bar one 0.254161 1.511763
集計#
集計とは、グループ化オブジェクトの次元を削減するGroupBy操作です。集計の結果は、グループ内の各列のスカラー値、または少なくともスカラー値として扱われます。たとえば、値のグループ内の各列の合計を生成するなどです。
In [79]: animals = pd.DataFrame(
....: {
....: "kind": ["cat", "dog", "cat", "dog"],
....: "height": [9.1, 6.0, 9.5, 34.0],
....: "weight": [7.9, 7.5, 9.9, 198.0],
....: }
....: )
....:
In [80]: animals
Out[80]:
kind height weight
0 cat 9.1 7.9
1 dog 6.0 7.5
2 cat 9.5 9.9
3 dog 34.0 198.0
In [81]: animals.groupby("kind").sum()
Out[81]:
height weight
kind
cat 18.6 17.8
dog 40.0 205.5
結果では、デフォルトでグループのキーがインデックスに表示されます。as_index=Falseを渡すことで、代わりに列に含めることができます。
In [82]: animals.groupby("kind", as_index=False).sum()
Out[82]:
kind height weight
0 cat 18.6 17.8
1 dog 40.0 205.5
組み込みの集計メソッド#
多くの一般的な集計は、GroupByオブジェクトにメソッドとして組み込まれています。以下のメソッドのうち、*が付いているものは、効率的なGroupBy固有の実装を**持ちません**。
メソッド |
説明 |
|---|---|
グループ内のいずれかの値が真理値であるかどうかを計算する |
|
グループ内のすべての値が真理値であるかどうかを計算する |
|
グループ内のNA以外の値の数を計算する |
|
|
グループの共分散を計算する |
各グループで最初に出現する値を計算する |
|
各グループの最大値のインデックスを計算する |
|
各グループの最小値のインデックスを計算する |
|
各グループで最後に出現する値を計算する |
|
各グループの最大値を計算する |
|
各グループの平均を計算する |
|
各グループの中央値を計算する |
|
各グループの最小値を計算する |
|
各グループ内の一意の値の数を計算する |
|
各グループ内の値の積を計算する |
|
各グループ内の値の指定された分位数を計算する |
|
各グループ内の値の平均の標準誤差を計算する |
|
各グループ内の値の数を計算する |
|
|
各グループ内の値の歪度を計算する |
各グループ内の値の標準偏差を計算する |
|
各グループ内の値の合計を計算する |
|
各グループ内の値の分散を計算する |
いくつかの例
In [83]: df.groupby("A")[["C", "D"]].max()
Out[83]:
C D
A
bar 0.254161 1.511763
foo 1.193555 1.627081
In [84]: df.groupby(["A", "B"]).mean()
Out[84]:
C D
A B
bar one 0.254161 1.511763
three 0.215897 -0.990582
two -0.077118 1.211526
foo one -0.491888 0.807291
three -0.862495 0.024580
two 0.024925 0.592714
別の集計例として、各グループのサイズを計算します。これは、sizeメソッドとしてGroupByに含まれています。グループ名をインデックスとし、各グループのサイズを値とするSeriesを返します。
In [85]: grouped = df.groupby(["A", "B"])
In [86]: grouped.size()
Out[86]:
A B
bar one 1
three 1
two 1
foo one 2
three 1
two 2
dtype: int64
DataFrameGroupBy.describe()メソッド自体は削減関数ではありませんが、各グループに関する要約統計量のコレクションを便利に生成するために使用できます。
In [87]: grouped.describe()
Out[87]:
C ... D
count mean std ... 50% 75% max
A B ...
bar one 1.0 0.254161 NaN ... 1.511763 1.511763 1.511763
three 1.0 0.215897 NaN ... -0.990582 -0.990582 -0.990582
two 1.0 -0.077118 NaN ... 1.211526 1.211526 1.211526
foo one 2.0 -0.491888 0.117887 ... 0.807291 1.076676 1.346061
three 1.0 -0.862495 NaN ... 0.024580 0.024580 0.024580
two 2.0 0.024925 1.652692 ... 0.592714 1.109898 1.627081
[6 rows x 16 columns]
別の集計例として、各グループの一意の値を数えることがあります。これは、DataFrameGroupBy.value_counts()関数に似ていますが、一意の値の数のみをカウントします。
In [88]: ll = [['foo', 1], ['foo', 2], ['foo', 2], ['bar', 1], ['bar', 1]]
In [89]: df4 = pd.DataFrame(ll, columns=["A", "B"])
In [90]: df4
Out[90]:
A B
0 foo 1
1 foo 2
2 foo 2
3 bar 1
4 bar 1
In [91]: df4.groupby("A")["B"].nunique()
Out[91]:
A
bar 1
foo 2
Name: B, dtype: int64
注
as_index=True(デフォルト)の場合、集計関数は、集計対象のグループを名前付き**列**として返しません。グループ化された列は、返されたオブジェクトの**インデックス**になります。
as_index=Falseを渡すと、入力で名前付き**インデックス**であろうと**列**であろうと、集計対象のグループが名前付き列として返されます。
aggregate() メソッド#
注
aggregate() メソッドは、さまざまな種類の入力を受け入れることができます。このセクションでは、さまざまなGroupByメソッドの文字列エイリアスの使用について詳しく説明します。他の入力については、以下のセクションで詳しく説明します。
pandasが実装する任意の削減メソッドは、文字列としてaggregate()に渡すことができます。ユーザーは省略形であるaggを使用することをお勧めします。これは、対応するメソッドが呼び出されたかのように動作します。
In [92]: grouped = df.groupby("A")
In [93]: grouped[["C", "D"]].aggregate("sum")
Out[93]:
C D
A
bar 0.392940 1.732707
foo -1.796421 2.824590
In [94]: grouped = df.groupby(["A", "B"])
In [95]: grouped.agg("sum")
Out[95]:
C D
A B
bar one 0.254161 1.511763
three 0.215897 -0.990582
two -0.077118 1.211526
foo one -0.983776 1.614581
three -0.862495 0.024580
two 0.049851 1.185429
集計の結果は、グループ名が新しいインデックスになります。複数のキーの場合、結果はデフォルトでMultiIndexになります。前述のとおり、これはas_indexオプションを使用して変更できます。
In [96]: grouped = df.groupby(["A", "B"], as_index=False)
In [97]: grouped.agg("sum")
Out[97]:
A B C D
0 bar one 0.254161 1.511763
1 bar three 0.215897 -0.990582
2 bar two -0.077118 1.211526
3 foo one -0.983776 1.614581
4 foo three -0.862495 0.024580
5 foo two 0.049851 1.185429
In [98]: df.groupby("A", as_index=False)[["C", "D"]].agg("sum")
Out[98]:
A C D
0 bar 0.392940 1.732707
1 foo -1.796421 2.824590
列名が結果のMultiIndexに保存されるため、DataFrame.reset_index() DataFrame関数を使用して同じ結果を得ることができますが、これにより余分なコピーが作成されます。
In [99]: df.groupby(["A", "B"]).agg("sum").reset_index()
Out[99]:
A B C D
0 bar one 0.254161 1.511763
1 bar three 0.215897 -0.990582
2 bar two -0.077118 1.211526
3 foo one -0.983776 1.614581
4 foo three -0.862495 0.024580
5 foo two 0.049851 1.185429
ユーザー定義関数による集計#
ユーザーは、カスタム集計のために独自のユーザー定義関数(UDF)を提供することもできます。
警告
UDFで集計する場合、UDFは提供されたSeriesを変更してはいけません。ユーザー定義関数 (UDF) メソッドによる変更の詳細については、を参照してください。
注
UDFで集計することは、GroupByでpandasの組み込みメソッドを使用するよりもパフォーマンスが低い場合があります。複雑な操作を、組み込みメソッドを利用する一連の操作に分割することを検討してください。
In [100]: animals
Out[100]:
kind height weight
0 cat 9.1 7.9
1 dog 6.0 7.5
2 cat 9.5 9.9
3 dog 34.0 198.0
In [101]: animals.groupby("kind")[["height"]].agg(lambda x: set(x))
Out[101]:
height
kind
cat {9.1, 9.5}
dog {34.0, 6.0}
結果のdtypeは集計関数のdtypeを反映します。異なるグループの結果が異なるdtypeを持つ場合、DataFrame構築と同じ方法で共通のdtypeが決定されます。
In [102]: animals.groupby("kind")[["height"]].agg(lambda x: x.astype(int).sum())
Out[102]:
height
kind
cat 18
dog 40
複数の関数を同時に適用する#
グループ化されたSeriesでは、関数のリストまたは辞書をSeriesGroupBy.agg()に渡すことができ、DataFrameが出力されます。
In [103]: grouped = df.groupby("A")
In [104]: grouped["C"].agg(["sum", "mean", "std"])
Out[104]:
sum mean std
A
bar 0.392940 0.130980 0.181231
foo -1.796421 -0.359284 0.912265
グループ化されたDataFrameでは、関数のリストをDataFrameGroupBy.agg()に渡して各列を集計できます。これにより、階層的な列インデックスを持つ集計結果が生成されます。
In [105]: grouped[["C", "D"]].agg(["sum", "mean", "std"])
Out[105]:
C D
sum mean std sum mean std
A
bar 0.392940 0.130980 0.181231 1.732707 0.577569 1.366330
foo -1.796421 -0.359284 0.912265 2.824590 0.564918 0.884785
結果の集計は関数自体の名前が付けられます。名前を変更する必要がある場合は、次のようにSeriesの連結操作を追加できます。
In [106]: (
.....: grouped["C"]
.....: .agg(["sum", "mean", "std"])
.....: .rename(columns={"sum": "foo", "mean": "bar", "std": "baz"})
.....: )
.....:
Out[106]:
foo bar baz
A
bar 0.392940 0.130980 0.181231
foo -1.796421 -0.359284 0.912265
グループ化されたDataFrameの場合も、同様の方法で名前を変更できます。
In [107]: (
.....: grouped[["C", "D"]].agg(["sum", "mean", "std"]).rename(
.....: columns={"sum": "foo", "mean": "bar", "std": "baz"}
.....: )
.....: )
.....:
Out[107]:
C D
foo bar baz foo bar baz
A
bar 0.392940 0.130980 0.181231 1.732707 0.577569 1.366330
foo -1.796421 -0.359284 0.912265 2.824590 0.564918 0.884785
注
一般的に、出力列名は一意である必要がありますが、pandasでは同じ関数(または同じ名前の2つの関数)を同じ列に適用することができます。
In [108]: grouped["C"].agg(["sum", "sum"])
Out[108]:
sum sum
A
bar 0.392940 0.392940
foo -1.796421 -1.796421
pandasでは、複数のラムダ式を提供することもできます。この場合、pandasは(名前のない)ラムダ関数の名前をマングルし、後続の各ラムダに_<i>を追加します。
In [109]: grouped["C"].agg([lambda x: x.max() - x.min(), lambda x: x.median() - x.mean()])
Out[109]:
<lambda_0> <lambda_1>
A
bar 0.331279 0.084917
foo 2.337259 -0.215962
名前付き集計#
**出力列名を制御しながら**列固有の集計をサポートするために、pandasは、DataFrameGroupBy.agg()およびSeriesGroupBy.agg()で「名前付き集計」として知られる特殊な構文を受け入れます。
キーワードは**出力**列名です。
値は、最初の要素が選択する列であり、2番目の要素がその列に適用する集計であるタプルです。pandasは、引数が何であるかを明確にするために、フィールド
['column', 'aggfunc']を持つNamedAgg名前付きタプルを提供します。通常どおり、集計は呼び出し可能オブジェクトまたは文字列エイリアスにすることができます。
In [110]: animals
Out[110]:
kind height weight
0 cat 9.1 7.9
1 dog 6.0 7.5
2 cat 9.5 9.9
3 dog 34.0 198.0
In [111]: animals.groupby("kind").agg(
.....: min_height=pd.NamedAgg(column="height", aggfunc="min"),
.....: max_height=pd.NamedAgg(column="height", aggfunc="max"),
.....: average_weight=pd.NamedAgg(column="weight", aggfunc="mean"),
.....: )
.....:
Out[111]:
min_height max_height average_weight
kind
cat 9.1 9.5 8.90
dog 6.0 34.0 102.75
NamedAggは単なるnamedtupleです。プレーンなタプルも許可されています。
In [112]: animals.groupby("kind").agg(
.....: min_height=("height", "min"),
.....: max_height=("height", "max"),
.....: average_weight=("weight", "mean"),
.....: )
.....:
Out[112]:
min_height max_height average_weight
kind
cat 9.1 9.5 8.90
dog 6.0 34.0 102.75
希望する列名が有効なPythonキーワードでない場合は、辞書を構築し、キーワード引数を展開します。
In [113]: animals.groupby("kind").agg(
.....: **{
.....: "total weight": pd.NamedAgg(column="weight", aggfunc="sum")
.....: }
.....: )
.....:
Out[113]:
total weight
kind
cat 17.8
dog 205.5
名前付き集計を使用する場合、追加のキーワード引数は集計関数には渡されません。(column, aggfunc)のペアのみを**kwargsとして渡す必要があります。集計関数に追加の引数が必要な場合は、functools.partial()を使用して部分的に適用します。
名前付き集計は、Seriesのgroupby集計にも有効です。この場合、列の選択はないため、値は関数のみです。
In [114]: animals.groupby("kind").height.agg(
.....: min_height="min",
.....: max_height="max",
.....: )
.....:
Out[114]:
min_height max_height
kind
cat 9.1 9.5
dog 6.0 34.0
DataFrameの列に異なる関数を適用する#
aggregateに辞書を渡すことで、DataFrameの列に異なる集計を適用できます。
In [115]: grouped.agg({"C": "sum", "D": lambda x: np.std(x, ddof=1)})
Out[115]:
C D
A
bar 0.392940 1.366330
foo -1.796421 0.884785
関数名も文字列にできます。文字列が有効であるためには、GroupByに実装されている必要があります。
In [116]: grouped.agg({"C": "sum", "D": "std"})
Out[116]:
C D
A
bar 0.392940 1.366330
foo -1.796421 0.884785
変換#
変換は、グループ化されるオブジェクトと同じようにインデックス付けされた結果を返すGroupBy操作です。一般的な例には、cumsum()やdiff()があります。
In [117]: speeds
Out[117]:
class order max_speed
falcon bird Falconiformes 389.0
parrot bird Psittaciformes 24.0
lion mammal Carnivora 80.2
monkey mammal Primates NaN
leopard mammal Carnivora 58.0
In [118]: grouped = speeds.groupby("class")["max_speed"]
In [119]: grouped.cumsum()
Out[119]:
falcon 389.0
parrot 413.0
lion 80.2
monkey NaN
leopard 138.2
Name: max_speed, dtype: float64
In [120]: grouped.diff()
Out[120]:
falcon NaN
parrot -365.0
lion NaN
monkey NaN
leopard NaN
Name: max_speed, dtype: float64
集計とは異なり、元のオブジェクトを分割するために使用されたグループ化は結果に含まれません。
注
変換は、結果を分割するために使用されるグループ化を含まないため、DataFrame.groupby()およびSeries.groupby()の引数as_indexとsortは影響しません。
変換の一般的な使用法は、結果を元のDataFrameに再度追加することです。
In [121]: result = speeds.copy()
In [122]: result["cumsum"] = grouped.cumsum()
In [123]: result["diff"] = grouped.diff()
In [124]: result
Out[124]:
class order max_speed cumsum diff
falcon bird Falconiformes 389.0 389.0 NaN
parrot bird Psittaciformes 24.0 413.0 -365.0
lion mammal Carnivora 80.2 80.2 NaN
monkey mammal Primates NaN NaN NaN
leopard mammal Carnivora 58.0 138.2 NaN
組み込み変換メソッド#
GroupBy上の以下のメソッドは変換として機能します。
メソッド |
説明 |
|---|---|
各グループ内のNA値を後方埋めする |
|
各グループ内の累積カウントを計算する |
|
各グループ内の累積最大値を計算する |
|
各グループ内の累積最小値を計算する |
|
各グループ内の累積積を計算する |
|
各グループ内の累積合計を計算する |
|
各グループ内の隣接する値の差を計算する |
|
各グループ内のNA値を前方埋めする |
|
各グループ内の隣接する値間のパーセント変化を計算する |
|
各グループ内の各値のランクを計算する |
|
各グループ内で値を上下にシフトする |
さらに、組み込みの集計メソッドを文字列としてtransform()(次のセクションを参照)に渡すと、結果がグループ全体にブロードキャストされ、変換された結果が生成されます。集計メソッドに効率的な実装がある場合、これもパフォーマンスが高いでしょう。
transform() メソッド#
集計メソッドと同様に、transform()メソッドは、前のセクションで説明した組み込み変換メソッドの文字列エイリアスを受け入れることができます。組み込み集計メソッドの文字列エイリアスも**受け入れることができます**。集計メソッドが提供されると、結果はグループ全体にブロードキャストされます。
In [125]: speeds
Out[125]:
class order max_speed
falcon bird Falconiformes 389.0
parrot bird Psittaciformes 24.0
lion mammal Carnivora 80.2
monkey mammal Primates NaN
leopard mammal Carnivora 58.0
In [126]: grouped = speeds.groupby("class")[["max_speed"]]
In [127]: grouped.transform("cumsum")
Out[127]:
max_speed
falcon 389.0
parrot 413.0
lion 80.2
monkey NaN
leopard 138.2
In [128]: grouped.transform("sum")
Out[128]:
max_speed
falcon 413.0
parrot 413.0
lion 138.2
monkey 138.2
leopard 138.2
文字列エイリアスに加えて、transform()メソッドは、ユーザー定義関数 (UDF) も受け入れることができます。UDFは次の条件を満たす必要があります。
グループチャンクと同じサイズの結果を返すか、グループチャンクのサイズにブロードキャスト可能であること (例: スカラー、
grouped.transform(lambda x: x.iloc[-1]))。グループチャンクに対して列ごとに操作すること。変換は、
chunk.applyを使用して最初のグループチャンクに適用されます。グループチャンクに対してインプレース操作を実行しないこと。グループチャンクは不変として扱われるべきであり、グループチャンクへの変更は予期しない結果を生み出す可能性があります。ユーザー定義関数 (UDF) メソッドによる変更の詳細については、を参照してください。
(オプションで) グループチャンク全体のすべての列に対して一度に操作する。これがサポートされている場合、**2番目の**チャンク以降は高速パスが使用されます。
注
transformにUDFを渡して変換することは、GroupByの組み込みメソッドを使用するよりもパフォーマンスが低いことがよくあります。複雑な操作を、組み込みメソッドを利用する一連の操作に分割することを検討してください。
このセクションのすべての例は、UDFを使用する代わりに組み込みメソッドを呼び出すことで、よりパフォーマンスを向上させることができます。以下の例を参照してください。
バージョン2.0.0で変更: グループ化されたDataFrameで.transformを使用し、変換関数がDataFrameを返す場合、pandasは結果のインデックスを入力のインデックスと揃えるようになりました。変換関数内で.to_numpy()を呼び出すことで、アライメントを回避できます。
aggregate() メソッドと同様に、結果のdtypeは変換関数のdtypeを反映します。異なるグループの結果が異なるdtypeを持つ場合、DataFrame構築と同じ方法で共通のdtypeが決定されます。
各グループ内のデータを標準化したいとします。
In [129]: index = pd.date_range("10/1/1999", periods=1100)
In [130]: ts = pd.Series(np.random.normal(0.5, 2, 1100), index)
In [131]: ts = ts.rolling(window=100, min_periods=100).mean().dropna()
In [132]: ts.head()
Out[132]:
2000-01-08 0.779333
2000-01-09 0.778852
2000-01-10 0.786476
2000-01-11 0.782797
2000-01-12 0.798110
Freq: D, dtype: float64
In [133]: ts.tail()
Out[133]:
2002-09-30 0.660294
2002-10-01 0.631095
2002-10-02 0.673601
2002-10-03 0.709213
2002-10-04 0.719369
Freq: D, dtype: float64
In [134]: transformed = ts.groupby(lambda x: x.year).transform(
.....: lambda x: (x - x.mean()) / x.std()
.....: )
.....:
結果は、各グループ内で平均0、標準偏差1になることが期待されます(浮動小数点誤差まで)。これは簡単に確認できます。
# Original Data
In [135]: grouped = ts.groupby(lambda x: x.year)
In [136]: grouped.mean()
Out[136]:
2000 0.442441
2001 0.526246
2002 0.459365
dtype: float64
In [137]: grouped.std()
Out[137]:
2000 0.131752
2001 0.210945
2002 0.128753
dtype: float64
# Transformed Data
In [138]: grouped_trans = transformed.groupby(lambda x: x.year)
In [139]: grouped_trans.mean()
Out[139]:
2000 -4.870756e-16
2001 -1.545187e-16
2002 4.136282e-16
dtype: float64
In [140]: grouped_trans.std()
Out[140]:
2000 1.0
2001 1.0
2002 1.0
dtype: float64
元のデータセットと変換されたデータセットを視覚的に比較することもできます。
In [141]: compare = pd.DataFrame({"Original": ts, "Transformed": transformed})
In [142]: compare.plot()
Out[142]: <Axes: >
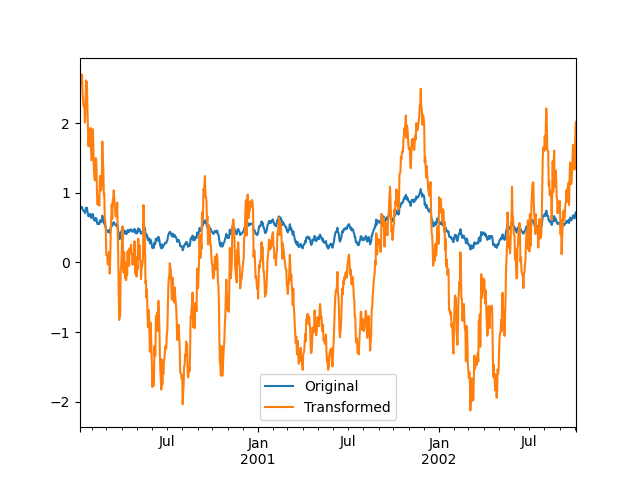
低次元出力を伴う変換関数は、入力配列の形状と一致するようにブロードキャストされます。
In [143]: ts.groupby(lambda x: x.year).transform(lambda x: x.max() - x.min())
Out[143]:
2000-01-08 0.623893
2000-01-09 0.623893
2000-01-10 0.623893
2000-01-11 0.623893
2000-01-12 0.623893
...
2002-09-30 0.558275
2002-10-01 0.558275
2002-10-02 0.558275
2002-10-03 0.558275
2002-10-04 0.558275
Freq: D, Length: 1001, dtype: float64
別の一般的なデータ変換は、欠損データをグループ平均で置き換えることです。
In [144]: cols = ["A", "B", "C"]
In [145]: values = np.random.randn(1000, 3)
In [146]: values[np.random.randint(0, 1000, 100), 0] = np.nan
In [147]: values[np.random.randint(0, 1000, 50), 1] = np.nan
In [148]: values[np.random.randint(0, 1000, 200), 2] = np.nan
In [149]: data_df = pd.DataFrame(values, columns=cols)
In [150]: data_df
Out[150]:
A B C
0 1.539708 -1.166480 0.533026
1 1.302092 -0.505754 NaN
2 -0.371983 1.104803 -0.651520
3 -1.309622 1.118697 -1.161657
4 -1.924296 0.396437 0.812436
.. ... ... ...
995 -0.093110 0.683847 -0.774753
996 -0.185043 1.438572 NaN
997 -0.394469 -0.642343 0.011374
998 -1.174126 1.857148 NaN
999 0.234564 0.517098 0.393534
[1000 rows x 3 columns]
In [151]: countries = np.array(["US", "UK", "GR", "JP"])
In [152]: key = countries[np.random.randint(0, 4, 1000)]
In [153]: grouped = data_df.groupby(key)
# Non-NA count in each group
In [154]: grouped.count()
Out[154]:
A B C
GR 209 217 189
JP 240 255 217
UK 216 231 193
US 239 250 217
In [155]: transformed = grouped.transform(lambda x: x.fillna(x.mean()))
変換されたデータではグループ平均が変化しておらず、NA値が含まれていないことを確認できます。
In [156]: grouped_trans = transformed.groupby(key)
In [157]: grouped.mean() # original group means
Out[157]:
A B C
GR -0.098371 -0.015420 0.068053
JP 0.069025 0.023100 -0.077324
UK 0.034069 -0.052580 -0.116525
US 0.058664 -0.020399 0.028603
In [158]: grouped_trans.mean() # transformation did not change group means
Out[158]:
A B C
GR -0.098371 -0.015420 0.068053
JP 0.069025 0.023100 -0.077324
UK 0.034069 -0.052580 -0.116525
US 0.058664 -0.020399 0.028603
In [159]: grouped.count() # original has some missing data points
Out[159]:
A B C
GR 209 217 189
JP 240 255 217
UK 216 231 193
US 239 250 217
In [160]: grouped_trans.count() # counts after transformation
Out[160]:
A B C
GR 228 228 228
JP 267 267 267
UK 247 247 247
US 258 258 258
In [161]: grouped_trans.size() # Verify non-NA count equals group size
Out[161]:
GR 228
JP 267
UK 247
US 258
dtype: int64
上記の注記で述べたように、このセクションの各例は、組み込みメソッドを使用することでより効率的に計算できます。以下のコードでは、UDFを使用した非効率な方法はコメントアウトされ、より高速な代替方法が下に示されています。
# result = ts.groupby(lambda x: x.year).transform(
# lambda x: (x - x.mean()) / x.std()
# )
In [162]: grouped = ts.groupby(lambda x: x.year)
In [163]: result = (ts - grouped.transform("mean")) / grouped.transform("std")
# result = ts.groupby(lambda x: x.year).transform(lambda x: x.max() - x.min())
In [164]: grouped = ts.groupby(lambda x: x.year)
In [165]: result = grouped.transform("max") - grouped.transform("min")
# grouped = data_df.groupby(key)
# result = grouped.transform(lambda x: x.fillna(x.mean()))
In [166]: grouped = data_df.groupby(key)
In [167]: result = data_df.fillna(grouped.transform("mean"))
ウィンドウとリサンプル操作#
resample()、expanding()、およびrolling()をgroupbysのメソッドとして使用できます。
以下の例では、列Aのグループに基づいて、列Bのサンプルにrolling()メソッドを適用します。
In [168]: df_re = pd.DataFrame({"A": [1] * 10 + [5] * 10, "B": np.arange(20)})
In [169]: df_re
Out[169]:
A B
0 1 0
1 1 1
2 1 2
3 1 3
4 1 4
.. .. ..
15 5 15
16 5 16
17 5 17
18 5 18
19 5 19
[20 rows x 2 columns]
In [170]: df_re.groupby("A").rolling(4).B.mean()
Out[170]:
A
1 0 NaN
1 NaN
2 NaN
3 1.5
4 2.5
...
5 15 13.5
16 14.5
17 15.5
18 16.5
19 17.5
Name: B, Length: 20, dtype: float64
expanding()メソッドは、特定のグループのすべてのメンバーに対して、指定された操作(例ではsum())を累積します。
In [171]: df_re.groupby("A").expanding().sum()
Out[171]:
B
A
1 0 0.0
1 1.0
2 3.0
3 6.0
4 10.0
... ...
5 15 75.0
16 91.0
17 108.0
18 126.0
19 145.0
[20 rows x 1 columns]
DataFrameの各グループでresample()メソッドを使用して日次頻度を取得し、欠損値をffill()メソッドで補完したいとします。
In [172]: df_re = pd.DataFrame(
.....: {
.....: "date": pd.date_range(start="2016-01-01", periods=4, freq="W"),
.....: "group": [1, 1, 2, 2],
.....: "val": [5, 6, 7, 8],
.....: }
.....: ).set_index("date")
.....:
In [173]: df_re
Out[173]:
group val
date
2016-01-03 1 5
2016-01-10 1 6
2016-01-17 2 7
2016-01-24 2 8
In [174]: df_re.groupby("group").resample("1D", include_groups=False).ffill()
Out[174]:
val
group date
1 2016-01-03 5
2016-01-04 5
2016-01-05 5
2016-01-06 5
2016-01-07 5
... ...
2 2016-01-20 7
2016-01-21 7
2016-01-22 7
2016-01-23 7
2016-01-24 8
[16 rows x 1 columns]
フィルタリング#
フィルタリングは、元のグループ化オブジェクトをサブセット化するGroupBy操作です。グループ全体、グループの一部、またはその両方をフィルターで除外できます。フィルタリングは、呼び出し元のオブジェクトのフィルター済みバージョンを返し、提供されている場合はグループ化列も含まれます。次の例では、classが結果に含まれています。
In [175]: speeds
Out[175]:
class order max_speed
falcon bird Falconiformes 389.0
parrot bird Psittaciformes 24.0
lion mammal Carnivora 80.2
monkey mammal Primates NaN
leopard mammal Carnivora 58.0
In [176]: speeds.groupby("class").nth(1)
Out[176]:
class order max_speed
parrot bird Psittaciformes 24.0
monkey mammal Primates NaN
注
集計とは異なり、フィルタリングはグループキーを結果のインデックスに追加しません。そのため、as_index=Falseまたはsort=Trueを渡してもこれらのメソッドには影響しません。
フィルタリングは、GroupByオブジェクトの列のサブセット化を尊重します。
In [177]: speeds.groupby("class")[["order", "max_speed"]].nth(1)
Out[177]:
order max_speed
parrot Psittaciformes 24.0
monkey Primates NaN
組み込みフィルタリング#
GroupByの以下のメソッドは、フィルタリングとして機能します。これらのメソッドはすべて、効率的なGroupBy固有の実装を持っています。
メソッド |
説明 |
|---|---|
各グループの最初の行を選択する |
|
各グループのn番目の行を選択する |
|
各グループの最後の行を選択する |
ユーザーは、変換とブールインデックス付けを組み合わせて、グループ内の複雑なフィルタリングを構築することもできます。たとえば、製品とそのボリュームのグループが与えられた場合、各グループの合計ボリュームの90%以下を占める最大の製品のみにデータをサブセット化したいとします。
In [178]: product_volumes = pd.DataFrame(
.....: {
.....: "group": list("xxxxyyy"),
.....: "product": list("abcdefg"),
.....: "volume": [10, 30, 20, 15, 40, 10, 20],
.....: }
.....: )
.....:
In [179]: product_volumes
Out[179]:
group product volume
0 x a 10
1 x b 30
2 x c 20
3 x d 15
4 y e 40
5 y f 10
6 y g 20
# Sort by volume to select the largest products first
In [180]: product_volumes = product_volumes.sort_values("volume", ascending=False)
In [181]: grouped = product_volumes.groupby("group")["volume"]
In [182]: cumpct = grouped.cumsum() / grouped.transform("sum")
In [183]: cumpct
Out[183]:
4 0.571429
1 0.400000
2 0.666667
6 0.857143
3 0.866667
0 1.000000
5 1.000000
Name: volume, dtype: float64
In [184]: significant_products = product_volumes[cumpct <= 0.9]
In [185]: significant_products.sort_values(["group", "product"])
Out[185]:
group product volume
1 x b 30
2 x c 20
3 x d 15
4 y e 40
6 y g 20
filter メソッド#
注
ユーザー定義関数 (UDF) をfilterに指定してフィルタリングすることは、GroupByの組み込みメソッドを使用するよりもパフォーマンスが低いことがよくあります。複雑な操作を、組み込みメソッドを利用する一連の操作に分割することを検討してください。
filterメソッドは、グループ全体に適用されるとTrueまたはFalseを返すユーザー定義関数(UDF)を受け取ります。filterメソッドの結果は、UDFがTrueを返したグループのサブセットになります。
グループの合計が2より大きいグループに属する要素のみを取得したいとします。
In [186]: sf = pd.Series([1, 1, 2, 3, 3, 3])
In [187]: sf.groupby(sf).filter(lambda x: x.sum() > 2)
Out[187]:
3 3
4 3
5 3
dtype: int64
もう一つの便利な操作は、メンバーが少ないグループに属する要素をフィルタリングすることです。
In [188]: dff = pd.DataFrame({"A": np.arange(8), "B": list("aabbbbcc")})
In [189]: dff.groupby("B").filter(lambda x: len(x) > 2)
Out[189]:
A B
2 2 b
3 3 b
4 4 b
5 5 b
あるいは、問題のあるグループを削除する代わりに、フィルターを通過しないグループがNaNで埋められた、同様のインデックスのオブジェクトを返すこともできます。
In [190]: dff.groupby("B").filter(lambda x: len(x) > 2, dropna=False)
Out[190]:
A B
0 NaN NaN
1 NaN NaN
2 2.0 b
3 3.0 b
4 4.0 b
5 5.0 b
6 NaN NaN
7 NaN NaN
複数の列を持つDataFrameの場合、フィルタはフィルター条件として列を明示的に指定する必要があります。
In [191]: dff["C"] = np.arange(8)
In [192]: dff.groupby("B").filter(lambda x: len(x["C"]) > 2)
Out[192]:
A B C
2 2 b 2
3 3 b 3
4 4 b 4
5 5 b 5
柔軟な apply#
グループ化されたデータに対する一部の操作は、集計、変換、またはフィルタリングのカテゴリに当てはまらない場合があります。これらには、apply関数を使用できます。
警告
applyは、渡されたものに応じて、レデューサー、トランスフォーマー、**または**フィルターとして動作すべきかどうかを結果から推測しようとします。そのため、グループ化された列が出力に含まれたり、含まれなかったりする場合があります。賢く動作しようとしますが、時には間違って推測することがあります。
注
このセクションのすべての例は、他のpandas機能を使用することで、より信頼性が高く、より効率的に計算できます。
In [193]: df
Out[193]:
A B C D
0 foo one -0.575247 1.346061
1 bar one 0.254161 1.511763
2 foo two -1.143704 1.627081
3 bar three 0.215897 -0.990582
4 foo two 1.193555 -0.441652
5 bar two -0.077118 1.211526
6 foo one -0.408530 0.268520
7 foo three -0.862495 0.024580
In [194]: grouped = df.groupby("A")
# could also just call .describe()
In [195]: grouped["C"].apply(lambda x: x.describe())
Out[195]:
A
bar count 3.000000
mean 0.130980
std 0.181231
min -0.077118
25% 0.069390
...
foo min -1.143704
25% -0.862495
50% -0.575247
75% -0.408530
max 1.193555
Name: C, Length: 16, dtype: float64
返される結果の次元も変更できます。
In [196]: grouped = df.groupby('A')['C']
In [197]: def f(group):
.....: return pd.DataFrame({'original': group,
.....: 'demeaned': group - group.mean()})
.....:
In [198]: grouped.apply(f)
Out[198]:
original demeaned
A
bar 1 0.254161 0.123181
3 0.215897 0.084917
5 -0.077118 -0.208098
foo 0 -0.575247 -0.215962
2 -1.143704 -0.784420
4 1.193555 1.552839
6 -0.408530 -0.049245
7 -0.862495 -0.503211
Seriesに対するapplyは、適用された関数からの戻り値がそれ自体がSeriesである場合でも操作でき、結果をDataFrameにアップキャストする可能性もあります。
In [199]: def f(x):
.....: return pd.Series([x, x ** 2], index=["x", "x^2"])
.....:
In [200]: s = pd.Series(np.random.rand(5))
In [201]: s
Out[201]:
0 0.582898
1 0.098352
2 0.001438
3 0.009420
4 0.815826
dtype: float64
In [202]: s.apply(f)
Out[202]:
x x^2
0 0.582898 0.339770
1 0.098352 0.009673
2 0.001438 0.000002
3 0.009420 0.000089
4 0.815826 0.665572
aggregate() メソッドと同様に、結果のdtypeはapply関数のdtypeを反映します。異なるグループの結果が異なるdtypeを持つ場合、DataFrame構築と同じ方法で共通のdtypeが決定されます。
group_keysでグループ化された列の配置を制御する#
グループ化された列をインデックスに含めるかどうかを制御するには、デフォルトがTrueであるgroup_keys引数を使用します。比較します。
In [203]: df.groupby("A", group_keys=True).apply(lambda x: x, include_groups=False)
Out[203]:
B C D
A
bar 1 one 0.254161 1.511763
3 three 0.215897 -0.990582
5 two -0.077118 1.211526
foo 0 one -0.575247 1.346061
2 two -1.143704 1.627081
4 two 1.193555 -0.441652
6 one -0.408530 0.268520
7 three -0.862495 0.024580
と
In [204]: df.groupby("A", group_keys=False).apply(lambda x: x, include_groups=False)
Out[204]:
B C D
0 one -0.575247 1.346061
1 one 0.254161 1.511763
2 two -1.143704 1.627081
3 three 0.215897 -0.990582
4 two 1.193555 -0.441652
5 two -0.077118 1.211526
6 one -0.408530 0.268520
7 three -0.862495 0.024580
Numba高速ルーチン#
バージョン 1.1 で追加。
Numbaがオプションの依存関係としてインストールされている場合、transformおよびaggregateメソッドはengine='numba'およびengine_kwargs引数をサポートします。引数の一般的な使用法とパフォーマンスに関する考慮事項については、Numbaによるパフォーマンス向上を参照してください。
関数シグネチャは**厳密に**values, indexで始まる必要があります。各グループに属するデータはvaluesに渡され、グループインデックスはindexに渡されます。
警告
engine='numba'を使用する場合、内部で「フォールバック」動作は発生しません。グループデータとグループインデックスは、JITされたユーザー定義関数にNumPy配列として渡され、代替の実行試行は行われません。
その他の便利な機能#
非数値列の除外#
私たちが今まで見てきた例のDataFrameをもう一度考えてみましょう。
In [205]: df
Out[205]:
A B C D
0 foo one -0.575247 1.346061
1 bar one 0.254161 1.511763
2 foo two -1.143704 1.627081
3 bar three 0.215897 -0.990582
4 foo two 1.193555 -0.441652
5 bar two -0.077118 1.211526
6 foo one -0.408530 0.268520
7 foo three -0.862495 0.024580
A列でグループ化された標準偏差を計算したいとします。少し問題があります。つまり、B列のデータは数値ではないため、気にする必要はありません。numeric_only=Trueを指定することで、非数値列を避けることができます。
In [206]: df.groupby("A").std(numeric_only=True)
Out[206]:
C D
A
bar 0.181231 1.366330
foo 0.912265 0.884785
df.groupby('A').colname.std()はdf.groupby('A').std().colnameよりも効率的であることに注意してください。したがって、集計関数の結果が1つの列(ここではcolname)のみで必要な場合、集計関数を適用する**前**にフィルター処理することができます。
In [207]: from decimal import Decimal
In [208]: df_dec = pd.DataFrame(
.....: {
.....: "id": [1, 2, 1, 2],
.....: "int_column": [1, 2, 3, 4],
.....: "dec_column": [
.....: Decimal("0.50"),
.....: Decimal("0.15"),
.....: Decimal("0.25"),
.....: Decimal("0.40"),
.....: ],
.....: }
.....: )
.....:
In [209]: df_dec.groupby(["id"])[["dec_column"]].sum()
Out[209]:
dec_column
id
1 0.75
2 0.55
(未)観測カテゴリカル値の扱い#
Categoricalグルーパ(単一のグルーパとして、または複数のグルーパの一部として)を使用する場合、observedキーワードは、考えられるすべてのグルーパ値のデカルト積を返すか(observed=False)、観測されたグルーパのみを返すか(observed=True)を制御します。
すべての値を表示
In [210]: pd.Series([1, 1, 1]).groupby(
.....: pd.Categorical(["a", "a", "a"], categories=["a", "b"]), observed=False
.....: ).count()
.....:
Out[210]:
a 3
b 0
dtype: int64
観測された値のみを表示
In [211]: pd.Series([1, 1, 1]).groupby(
.....: pd.Categorical(["a", "a", "a"], categories=["a", "b"]), observed=True
.....: ).count()
.....:
Out[211]:
a 3
dtype: int64
グループ化された値の返されるdtypeは、常にグループ化された**すべて**のカテゴリを含みます。
In [212]: s = (
.....: pd.Series([1, 1, 1])
.....: .groupby(pd.Categorical(["a", "a", "a"], categories=["a", "b"]), observed=True)
.....: .count()
.....: )
.....:
In [213]: s.index.dtype
Out[213]: CategoricalDtype(categories=['a', 'b'], ordered=False, categories_dtype=object)
NAグループの処理#
NAとは、NA、NaN、NaT、Noneを含む任意のNA値を指します。グループ化キーにNA値がある場合、デフォルトではこれらは除外されます。つまり、任意の「NAグループ」は削除されます。dropna=Falseを指定することで、NAグループを含めることができます。
In [214]: df = pd.DataFrame({"key": [1.0, 1.0, np.nan, 2.0, np.nan], "A": [1, 2, 3, 4, 5]})
In [215]: df
Out[215]:
key A
0 1.0 1
1 1.0 2
2 NaN 3
3 2.0 4
4 NaN 5
In [216]: df.groupby("key", dropna=True).sum()
Out[216]:
A
key
1.0 3
2.0 4
In [217]: df.groupby("key", dropna=False).sum()
Out[217]:
A
key
1.0 3
2.0 4
NaN 8
順序付き因子によるグループ化#
pandasのCategoricalクラスのインスタンスとして表現されたカテゴリ変数は、グループキーとして使用できます。その場合、レベルの順序が保持されます。observed=Falseかつsort=Falseの場合、観測されていないカテゴリは結果の最後に順序通りに配置されます。
In [218]: days = pd.Categorical(
.....: values=["Wed", "Mon", "Thu", "Mon", "Wed", "Sat"],
.....: categories=["Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"],
.....: )
.....:
In [219]: data = pd.DataFrame(
.....: {
.....: "day": days,
.....: "workers": [3, 4, 1, 4, 2, 2],
.....: }
.....: )
.....:
In [220]: data
Out[220]:
day workers
0 Wed 3
1 Mon 4
2 Thu 1
3 Mon 4
4 Wed 2
5 Sat 2
In [221]: data.groupby("day", observed=False, sort=True).sum()
Out[221]:
workers
day
Mon 8
Tue 0
Wed 5
Thu 1
Fri 0
Sat 2
Sun 0
In [222]: data.groupby("day", observed=False, sort=False).sum()
Out[222]:
workers
day
Wed 5
Mon 8
Thu 1
Sat 2
Tue 0
Fri 0
Sun 0
グルーパ指定によるグループ化#
適切にグループ化するには、もう少しデータを指定する必要があるかもしれません。このローカル制御を提供するために、pd.Grouperを使用できます。
In [223]: import datetime
In [224]: df = pd.DataFrame(
.....: {
.....: "Branch": "A A A A A A A B".split(),
.....: "Buyer": "Carl Mark Carl Carl Joe Joe Joe Carl".split(),
.....: "Quantity": [1, 3, 5, 1, 8, 1, 9, 3],
.....: "Date": [
.....: datetime.datetime(2013, 1, 1, 13, 0),
.....: datetime.datetime(2013, 1, 1, 13, 5),
.....: datetime.datetime(2013, 10, 1, 20, 0),
.....: datetime.datetime(2013, 10, 2, 10, 0),
.....: datetime.datetime(2013, 10, 1, 20, 0),
.....: datetime.datetime(2013, 10, 2, 10, 0),
.....: datetime.datetime(2013, 12, 2, 12, 0),
.....: datetime.datetime(2013, 12, 2, 14, 0),
.....: ],
.....: }
.....: )
.....:
In [225]: df
Out[225]:
Branch Buyer Quantity Date
0 A Carl 1 2013-01-01 13:00:00
1 A Mark 3 2013-01-01 13:05:00
2 A Carl 5 2013-10-01 20:00:00
3 A Carl 1 2013-10-02 10:00:00
4 A Joe 8 2013-10-01 20:00:00
5 A Joe 1 2013-10-02 10:00:00
6 A Joe 9 2013-12-02 12:00:00
7 B Carl 3 2013-12-02 14:00:00
目的の頻度で特定の列をグループ化します。これはリサンプリングに似ています。
In [226]: df.groupby([pd.Grouper(freq="1ME", key="Date"), "Buyer"])[["Quantity"]].sum()
Out[226]:
Quantity
Date Buyer
2013-01-31 Carl 1
Mark 3
2013-10-31 Carl 6
Joe 9
2013-12-31 Carl 3
Joe 9
freqが指定されている場合、pd.Grouperによって返されるオブジェクトはpandas.api.typing.TimeGrouperのインスタンスになります。同じ名前の列とインデックスがある場合、keyを使用して列でグループ化し、levelを使用してインデックスでグループ化できます。
In [227]: df = df.set_index("Date")
In [228]: df["Date"] = df.index + pd.offsets.MonthEnd(2)
In [229]: df.groupby([pd.Grouper(freq="6ME", key="Date"), "Buyer"])[["Quantity"]].sum()
Out[229]:
Quantity
Date Buyer
2013-02-28 Carl 1
Mark 3
2014-02-28 Carl 9
Joe 18
In [230]: df.groupby([pd.Grouper(freq="6ME", level="Date"), "Buyer"])[["Quantity"]].sum()
Out[230]:
Quantity
Date Buyer
2013-01-31 Carl 1
Mark 3
2014-01-31 Carl 9
Joe 18
各グループの最初の行を取得する#
DataFrameまたはSeriesと同様に、groupbyオブジェクトに対してheadとtailを呼び出すことができます。
In [231]: df = pd.DataFrame([[1, 2], [1, 4], [5, 6]], columns=["A", "B"])
In [232]: df
Out[232]:
A B
0 1 2
1 1 4
2 5 6
In [233]: g = df.groupby("A")
In [234]: g.head(1)
Out[234]:
A B
0 1 2
2 5 6
In [235]: g.tail(1)
Out[235]:
A B
1 1 4
2 5 6
これは、各グループの最初のまたは最後のn行を示します。
各グループのn番目の行を取得する#
各グループからn番目の項目を選択するには、DataFrameGroupBy.nth()またはSeriesGroupBy.nth()を使用します。引数には任意の整数、整数のリスト、スライス、またはスライスのリストを指定できます(例は以下を参照)。グループのn番目の要素が存在しない場合でも、エラーは**発生せず**、対応する行は返されません。
一般的に、この操作はフィルタリングとして機能します。特定の場合には、グループごとに1行を返すため、削減としても機能します。ただし、一般的にはグループごとに0行または複数行を返す可能性があるため、pandasはすべての場合でこれをフィルタリングとして扱います。
In [236]: df = pd.DataFrame([[1, np.nan], [1, 4], [5, 6]], columns=["A", "B"])
In [237]: g = df.groupby("A")
In [238]: g.nth(0)
Out[238]:
A B
0 1 NaN
2 5 6.0
In [239]: g.nth(-1)
Out[239]:
A B
1 1 4.0
2 5 6.0
In [240]: g.nth(1)
Out[240]:
A B
1 1 4.0
グループのn番目の要素が存在しない場合、結果には対応する行は含まれません。特に、指定されたnがどのグループよりも大きい場合、結果は空のDataFrameになります。
In [241]: g.nth(5)
Out[241]:
Empty DataFrame
Columns: [A, B]
Index: []
nullでないn番目の項目を選択したい場合は、dropnaキーワード引数を使用します。DataFrameの場合、dropnaに渡すのと同じように'any'または'all'のいずれかである必要があります。
# nth(0) is the same as g.first()
In [242]: g.nth(0, dropna="any")
Out[242]:
A B
1 1 4.0
2 5 6.0
In [243]: g.first()
Out[243]:
B
A
1 4.0
5 6.0
# nth(-1) is the same as g.last()
In [244]: g.nth(-1, dropna="any")
Out[244]:
A B
1 1 4.0
2 5 6.0
In [245]: g.last()
Out[245]:
B
A
1 4.0
5 6.0
In [246]: g.B.nth(0, dropna="all")
Out[246]:
1 4.0
2 6.0
Name: B, dtype: float64
整数のリストとして複数のn番目の値を指定することで、各グループから複数の行を選択することもできます。
In [247]: business_dates = pd.date_range(start="4/1/2014", end="6/30/2014", freq="B")
In [248]: df = pd.DataFrame(1, index=business_dates, columns=["a", "b"])
# get the first, 4th, and last date index for each month
In [249]: df.groupby([df.index.year, df.index.month]).nth([0, 3, -1])
Out[249]:
a b
2014-04-01 1 1
2014-04-04 1 1
2014-04-30 1 1
2014-05-01 1 1
2014-05-06 1 1
2014-05-30 1 1
2014-06-02 1 1
2014-06-05 1 1
2014-06-30 1 1
スライスまたはスライスのリストも使用できます。
In [250]: df.groupby([df.index.year, df.index.month]).nth[1:]
Out[250]:
a b
2014-04-02 1 1
2014-04-03 1 1
2014-04-04 1 1
2014-04-07 1 1
2014-04-08 1 1
... .. ..
2014-06-24 1 1
2014-06-25 1 1
2014-06-26 1 1
2014-06-27 1 1
2014-06-30 1 1
[62 rows x 2 columns]
In [251]: df.groupby([df.index.year, df.index.month]).nth[1:, :-1]
Out[251]:
a b
2014-04-01 1 1
2014-04-02 1 1
2014-04-03 1 1
2014-04-04 1 1
2014-04-07 1 1
... .. ..
2014-06-24 1 1
2014-06-25 1 1
2014-06-26 1 1
2014-06-27 1 1
2014-06-30 1 1
[65 rows x 2 columns]
グループ項目の列挙#
各行がグループ内で出現する順序を確認するには、cumcountメソッドを使用します。
In [252]: dfg = pd.DataFrame(list("aaabba"), columns=["A"])
In [253]: dfg
Out[253]:
A
0 a
1 a
2 a
3 b
4 b
5 a
In [254]: dfg.groupby("A").cumcount()
Out[254]:
0 0
1 1
2 2
3 0
4 1
5 3
dtype: int64
In [255]: dfg.groupby("A").cumcount(ascending=False)
Out[255]:
0 3
1 2
2 1
3 1
4 0
5 0
dtype: int64
グループの列挙#
グループの順序(cumcountによって与えられるグループ内の行の順序ではなく)を見るには、DataFrameGroupBy.ngroup()を使用できます。
グループに与えられる番号は、groupbyオブジェクトを反復処理するときにグループが表示される順序と一致することに注意してください。最初に観測された順序ではありません。
In [256]: dfg = pd.DataFrame(list("aaabba"), columns=["A"])
In [257]: dfg
Out[257]:
A
0 a
1 a
2 a
3 b
4 b
5 a
In [258]: dfg.groupby("A").ngroup()
Out[258]:
0 0
1 0
2 0
3 1
4 1
5 0
dtype: int64
In [259]: dfg.groupby("A").ngroup(ascending=False)
Out[259]:
0 1
1 1
2 1
3 0
4 0
5 1
dtype: int64
プロット#
GroupByは一部のプロットメソッドでも機能します。この場合、列1の値がグループ「B」では平均して3倍高いと推測するとします。
In [260]: np.random.seed(1234)
In [261]: df = pd.DataFrame(np.random.randn(50, 2))
In [262]: df["g"] = np.random.choice(["A", "B"], size=50)
In [263]: df.loc[df["g"] == "B", 1] += 3
これはボックスプロットで簡単に視覚化できます。
In [264]: df.groupby("g").boxplot()
Out[264]:
A Axes(0.1,0.15;0.363636x0.75)
B Axes(0.536364,0.15;0.363636x0.75)
dtype: object
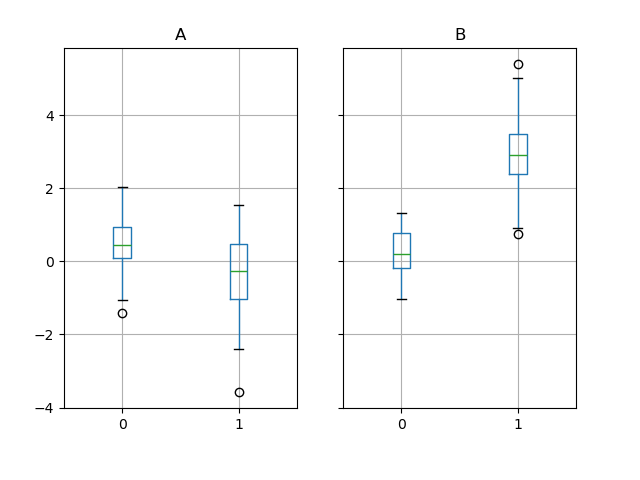
boxplot呼び出しの結果は、グループ化列g(「A」と「B」)の値がキーとなる辞書です。結果の辞書の値は、boxplotのreturn_typeキーワードで制御できます。詳細については、視覚化ドキュメントを参照してください。
警告
歴史的な理由により、df.groupby("g").boxplot()はdf.boxplot(by="g")と等価ではありません。説明についてはこちらを参照してください。
関数呼び出しのパイプ処理#
DataFrameおよびSeriesによって提供される機能と同様に、GroupByオブジェクトを受け取る関数は、よりクリーンで読みやすい構文を可能にするpipeメソッドを使用して連鎖させることができます。.pipeの一般的な説明については、こちらを参照してください。
.groupbyと.pipeを組み合わせることは、GroupByオブジェクトを再利用する必要がある場合に役立つことがよくあります。
例として、店舗、製品、収益、販売数量の列を持つDataFrameがあると想像してください。店舗ごと、製品ごとの**価格**(つまり、収益/数量)のグループごとの計算を行いたいとします。これは複数ステップの操作で実行できますが、パイプ処理の観点から表現すると、コードがより読みやすくなります。まず、データを設定します。
In [265]: n = 1000
In [266]: df = pd.DataFrame(
.....: {
.....: "Store": np.random.choice(["Store_1", "Store_2"], n),
.....: "Product": np.random.choice(["Product_1", "Product_2"], n),
.....: "Revenue": (np.random.random(n) * 50 + 10).round(2),
.....: "Quantity": np.random.randint(1, 10, size=n),
.....: }
.....: )
.....:
In [267]: df.head(2)
Out[267]:
Store Product Revenue Quantity
0 Store_2 Product_1 26.12 1
1 Store_2 Product_1 28.86 1
次に、店舗/製品ごとの価格を求めます。
In [268]: (
.....: df.groupby(["Store", "Product"])
.....: .pipe(lambda grp: grp.Revenue.sum() / grp.Quantity.sum())
.....: .unstack()
.....: .round(2)
.....: )
.....:
Out[268]:
Product Product_1 Product_2
Store
Store_1 6.82 7.05
Store_2 6.30 6.64
パイプ処理は、グループ化されたオブジェクトを任意の関数に渡したい場合にも表現力豊かです。たとえば、
In [269]: def mean(groupby):
.....: return groupby.mean()
.....:
In [270]: df.groupby(["Store", "Product"]).pipe(mean)
Out[270]:
Revenue Quantity
Store Product
Store_1 Product_1 34.622727 5.075758
Product_2 35.482815 5.029630
Store_2 Product_1 32.972837 5.237589
Product_2 34.684360 5.224000
ここでmeanはGroupByオブジェクトを受け取り、各Store-Productの組み合わせについてそれぞれRevenue列とQuantity列の平均を求めます。mean関数はGroupByオブジェクトを受け取る任意の関数であり、.pipeはGroupByオブジェクトを指定した関数にパラメータとして渡します。
例#
複数列の因子化#
DataFrameGroupBy.ngroup()を使用することで、factorize()(リシェイプAPIでさらに説明)と同様の方法でグループに関する情報を抽出できますが、これは異なる型の複数の列や異なるソースに自然に適用されます。これは、グループ行間の関係がその内容よりも重要である場合、または整数エンコーディングのみを受け入れるアルゴリズムへの入力として、処理の中間的なカテゴリのようなステップとして役立ちます。(完全なカテゴリデータに対するpandasのサポートの詳細については、カテゴリカルデータの紹介とAPIドキュメントを参照してください。)
In [271]: dfg = pd.DataFrame({"A": [1, 1, 2, 3, 2], "B": list("aaaba")})
In [272]: dfg
Out[272]:
A B
0 1 a
1 1 a
2 2 a
3 3 b
4 2 a
In [273]: dfg.groupby(["A", "B"]).ngroup()
Out[273]:
0 0
1 0
2 1
3 2
4 1
dtype: int64
In [274]: dfg.groupby(["A", [0, 0, 0, 1, 1]]).ngroup()
Out[274]:
0 0
1 0
2 1
3 3
4 2
dtype: int64
インデクサーによるGroupbyでデータを「リサンプル」する#
リサンプリングとは、既存の観測データまたはデータを生成するモデルから、新しい仮想サンプル(リサンプル)を生成することです。これらの新しいサンプルは、既存のサンプルに似ています。
リサンプルが非日付時刻のようなインデックスで機能するためには、以下の手順を利用できます。
以下の例では、**df.index // 5** は、groupby操作で何が選択されるかを決定するために使用される整数配列を返します。
注
以下の例は、サンプルの統合によってダウンサンプリングする方法を示しています。ここでは、**df.index // 5** を使用してサンプルをビンに集計しています。**std()** 関数を適用することで、多くのサンプルに含まれる情報を、それらの標準偏差である少数の値のサブセットに集約し、それによってサンプルの数を削減しています。
In [275]: df = pd.DataFrame(np.random.randn(10, 2))
In [276]: df
Out[276]:
0 1
0 -0.793893 0.321153
1 0.342250 1.618906
2 -0.975807 1.918201
3 -0.810847 -1.405919
4 -1.977759 0.461659
5 0.730057 -1.316938
6 -0.751328 0.528290
7 -0.257759 -1.081009
8 0.505895 -1.701948
9 -1.006349 0.020208
In [277]: df.index // 5
Out[277]: Index([0, 0, 0, 0, 0, 1, 1, 1, 1, 1], dtype='int64')
In [278]: df.groupby(df.index // 5).std()
Out[278]:
0 1
0 0.823647 1.312912
1 0.760109 0.942941
名前を伝播するためのSeriesの返却#
DataFrameの列をグループ化し、一連のメトリックを計算して、名前付きのSeriesを返します。Seriesの名前は、列インデックスの名前として使用されます。これは、スタッキングなどのリシェイプ操作と組み合わせて特に役立ちます。この場合、列インデックスの名前が挿入された列の名前として使用されます。
In [279]: df = pd.DataFrame(
.....: {
.....: "a": [0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2],
.....: "b": [0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1],
.....: "c": [1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0],
.....: "d": [0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1],
.....: }
.....: )
.....:
In [280]: def compute_metrics(x):
.....: result = {"b_sum": x["b"].sum(), "c_mean": x["c"].mean()}
.....: return pd.Series(result, name="metrics")
.....:
In [281]: result = df.groupby("a").apply(compute_metrics, include_groups=False)
In [282]: result
Out[282]:
metrics b_sum c_mean
a
0 2.0 0.5
1 2.0 0.5
2 2.0 0.5
In [283]: result.stack(future_stack=True)
Out[283]:
a metrics
0 b_sum 2.0
c_mean 0.5
1 b_sum 2.0
c_mean 0.5
2 b_sum 2.0
c_mean 0.5
dtype: float64