バージョン 0.20.1 (2017年5月5日)#
これは 0.19.2 からのメジャーリリースで、多数のバグ修正に加えて、API変更、非推奨、新機能、機能強化、パフォーマンス改善が含まれています。すべてのユーザーにこのバージョンへのアップグレードをお勧めします。
主な機能は以下の通りです。
groupby-rolling-resample APIに似たSeries/DataFrameの新しい
.agg()APIについては、こちらを参照してください。feather-formatとの統合。新しいトップレベルのpd.read_feather()およびDataFrame.to_feather()メソッドについては、こちらを参照してください。.ixインデクサーは非推奨になりました。詳細はこちらを参照してください。Panelは非推奨になりました。詳細はこちらを参照してください。IntervalIndexとIntervalスカラー型の追加については、こちらを参照してください。.groupby()でインデックスレベルごとにグループ化する際のユーザーAPIの改善については、こちらを参照してください。UInt64dtypeのサポートの改善については、こちらを参照してください。JSONシリアル化のための新しいorient、
orient='table'。これはテーブルスキーマの仕様を使用し、Jupyter Notebookでよりインタラクティブな表現を可能にします。詳細はこちらを参照してください。スタイル付きDataFrame (
DataFrame.style) のExcelへのエクスポートの実験的サポートについては、こちらを参照してください。ウィンドウのバイナリのcorr/cov操作は、
Panelが非推奨になったため、PanelではなくMultiIndexedDataFrameを返すようになりました。詳細はこちらを参照してください。S3ハンドリングのサポートは
s3fsを使用するようになりました。詳細はこちらを参照してください。Google BigQueryのサポートは
pandas-gbqライブラリを使用するようになりました。詳細はこちらを参照してください。
警告
pandasはコードベースの内部構造とレイアウトを変更しました。これはトップレベルのpandas.*名前空間からのインポートに影響を与える可能性があります。変更についてはこちらを参照してください。
注
これは0.20.0と0.20.1の統合リリースです。バージョン0.20.1には、pandasのutilsルーチンを使用するダウンストリームプロジェクトとの下位互換性のための追加の変更が1つ含まれています。(GH 16250)
新機能#
DataFrame/Seriesのメソッドagg API#
Series & DataFrameが、集計APIをサポートするように強化されました。これは、groupby、ウィンドウ操作、リサンプリングでおなじみのAPIです。agg()とtransform()を使用することで、簡潔な方法で集計操作を実行できます。完全なドキュメントはこちらです (GH 1623)。
以下に例を示します。
In [1]: df = pd.DataFrame(np.random.randn(10, 3), columns=['A', 'B', 'C'],
...: index=pd.date_range('1/1/2000', periods=10))
...:
In [2]: df.iloc[3:7] = np.nan
In [3]: df
Out[3]:
A B C
2000-01-01 0.469112 -0.282863 -1.509059
2000-01-02 -1.135632 1.212112 -0.173215
2000-01-03 0.119209 -1.044236 -0.861849
2000-01-04 NaN NaN NaN
2000-01-05 NaN NaN NaN
2000-01-06 NaN NaN NaN
2000-01-07 NaN NaN NaN
2000-01-08 0.113648 -1.478427 0.524988
2000-01-09 0.404705 0.577046 -1.715002
2000-01-10 -1.039268 -0.370647 -1.157892
[10 rows x 3 columns]
文字列関数名、呼び出し可能オブジェクト、リスト、またはこれらの辞書を使用して操作できます。
単一の関数を使用することは.applyと同等です。
In [4]: df.agg('sum')
Out[4]:
A -1.068226
B -1.387015
C -4.892029
Length: 3, dtype: float64
関数のリストによる複数集計。
In [5]: df.agg(['sum', 'min'])
Out[5]:
A B C
sum -1.068226 -1.387015 -4.892029
min -1.135632 -1.478427 -1.715002
[2 rows x 3 columns]
辞書を使用すると、列ごとに特定の集計を適用できます。すべての集計関数の行列のような出力が得られます。出力は一意の関数ごとに1つの列を持ちます。特定の列に適用された関数はNaNになります。
In [6]: df.agg({'A': ['sum', 'min'], 'B': ['min', 'max']})
Out[6]:
A B
sum -1.068226 NaN
min -1.135632 -1.478427
max NaN 1.212112
[3 rows x 2 columns]
APIは、結果をブロードキャストするための.transform()関数もサポートしています。
In [7]: df.transform(['abs', lambda x: x - x.min()])
Out[7]:
A B C
abs <lambda> abs <lambda> abs <lambda>
2000-01-01 0.469112 1.604745 0.282863 1.195563 1.509059 0.205944
2000-01-02 1.135632 0.000000 1.212112 2.690539 0.173215 1.541787
2000-01-03 0.119209 1.254841 1.044236 0.434191 0.861849 0.853153
2000-01-04 NaN NaN NaN NaN NaN NaN
2000-01-05 NaN NaN NaN NaN NaN NaN
2000-01-06 NaN NaN NaN NaN NaN NaN
2000-01-07 NaN NaN NaN NaN NaN NaN
2000-01-08 0.113648 1.249281 1.478427 0.000000 0.524988 2.239990
2000-01-09 0.404705 1.540338 0.577046 2.055473 1.715002 0.000000
2000-01-10 1.039268 0.096364 0.370647 1.107780 1.157892 0.557110
[10 rows x 6 columns]
集計できない混合データ型が提示された場合、.agg()は有効な集計のみを適用します。これは、groupby .agg()の動作に似ています。(GH 15015)
In [8]: df = pd.DataFrame({'A': [1, 2, 3],
...: 'B': [1., 2., 3.],
...: 'C': ['foo', 'bar', 'baz'],
...: 'D': pd.date_range('20130101', periods=3)})
...:
In [9]: df.dtypes
Out[9]:
A int64
B float64
C object
D datetime64[ns]
Length: 4, dtype: object
In [10]: df.agg(['min', 'sum'])
Out[10]:
A B C D
min 1 1.0 bar 2013-01-01
sum 6 6.0 foobarbaz NaT
データIOのキーワード引数dtype#
read_csv()の'python'エンジン、固定幅テキストファイルを解析するためのread_fwf()関数、Excelファイルを解析するためのread_excel()は、特定の列の型を指定するためのdtypeキーワード引数を受け入れるようになりました (GH 14295)。詳細についてはio docsを参照してください。
In [10]: data = "a b\n1 2\n3 4"
In [11]: pd.read_fwf(StringIO(data)).dtypes
Out[11]:
a int64
b int64
Length: 2, dtype: object
In [12]: pd.read_fwf(StringIO(data), dtype={'a': 'float64', 'b': 'object'}).dtypes
Out[12]:
a float64
b object
Length: 2, dtype: object
メソッド.to_datetime()にoriginパラメータが追加されました#
to_datetime()に新しいパラメータoriginが追加され、特定のunitが指定された数値値を解析する際に、結果のタイムスタンプを計算するための基準日を定義できるようになりました。(GH 11276、GH 11745)
たとえば、開始日を1960-01-01とすると
In [13]: pd.to_datetime([1, 2, 3], unit='D', origin=pd.Timestamp('1960-01-01'))
Out[13]: DatetimeIndex(['1960-01-02', '1960-01-03', '1960-01-04'], dtype='datetime64[ns]', freq=None)
デフォルトはorigin='unix'に設定されており、これは一般的に「Unixエポック」またはPOSIX時間と呼ばれる1970-01-01 00:00:00がデフォルトとなります。これは以前のデフォルトだったので、後方互換性のある変更です。
In [14]: pd.to_datetime([1, 2, 3], unit='D')
Out[14]: DatetimeIndex(['1970-01-02', '1970-01-03', '1970-01-04'], dtype='datetime64[ns]', freq=None)
GroupByの機能強化#
DataFrame.groupby()にbyパラメータとして渡される文字列は、列名またはインデックスレベル名のいずれかを参照できるようになりました。以前は列名のみを参照できました。これにより、列とインデックスレベルを同時に簡単にグループ化できます。(GH 5677)
In [15]: arrays = [['bar', 'bar', 'baz', 'baz', 'foo', 'foo', 'qux', 'qux'],
....: ['one', 'two', 'one', 'two', 'one', 'two', 'one', 'two']]
....:
In [16]: index = pd.MultiIndex.from_arrays(arrays, names=['first', 'second'])
In [17]: df = pd.DataFrame({'A': [1, 1, 1, 1, 2, 2, 3, 3],
....: 'B': np.arange(8)},
....: index=index)
....:
In [18]: df
Out[18]:
A B
first second
bar one 1 0
two 1 1
baz one 1 2
two 1 3
foo one 2 4
two 2 5
qux one 3 6
two 3 7
[8 rows x 2 columns]
In [19]: df.groupby(['second', 'A']).sum()
Out[19]:
B
second A
one 1 2
2 4
3 6
two 1 4
2 5
3 7
[6 rows x 1 columns]
read_csvにおける圧縮URLのサポートの改善#
圧縮コードがリファクタリングされました (GH 12688)。その結果、read_csv()またはread_table()でのURLからのデータフレームの読み取りが、追加の圧縮メソッド(xz、bz2、zip)をサポートするようになりました (GH 14570)。以前はgzip圧縮のみがサポートされていました。デフォルトでは、URLとパスの圧縮はファイル拡張子を使用して推測されるようになりました。さらに、Python 2 C-engineでのbz2圧縮のサポートが改善されました (GH 14874)。
In [20]: url = ('https://github.com/{repo}/raw/{branch}/{path}'
....: .format(repo='pandas-dev/pandas',
....: branch='main',
....: path='pandas/tests/io/parser/data/salaries.csv.bz2'))
....:
# default, infer compression
In [21]: df = pd.read_csv(url, sep='\t', compression='infer')
# explicitly specify compression
In [22]: df = pd.read_csv(url, sep='\t', compression='bz2')
In [23]: df.head(2)
Out[23]:
S X E M
0 13876 1 1 1
1 11608 1 3 0
[2 rows x 4 columns]
PickleファイルIOが圧縮をサポートするようになりました#
read_pickle()、DataFrame.to_pickle()、Series.to_pickle()が、圧縮されたPickleファイルの読み書きをサポートするようになりました。圧縮メソッドは明示的なパラメータとして指定することも、ファイル拡張子から推測することもできます。詳細についてはこちらのドキュメントを参照してください。
In [24]: df = pd.DataFrame({'A': np.random.randn(1000),
....: 'B': 'foo',
....: 'C': pd.date_range('20130101', periods=1000, freq='s')})
....:
明示的な圧縮タイプを使用する
In [25]: df.to_pickle("data.pkl.compress", compression="gzip")
In [26]: rt = pd.read_pickle("data.pkl.compress", compression="gzip")
In [27]: rt.head()
Out[27]:
A B C
0 -1.344312 foo 2013-01-01 00:00:00
1 0.844885 foo 2013-01-01 00:00:01
2 1.075770 foo 2013-01-01 00:00:02
3 -0.109050 foo 2013-01-01 00:00:03
4 1.643563 foo 2013-01-01 00:00:04
[5 rows x 3 columns]
デフォルトでは、拡張子から圧縮タイプを推測します (compression='infer')。
In [28]: df.to_pickle("data.pkl.gz")
In [29]: rt = pd.read_pickle("data.pkl.gz")
In [30]: rt.head()
Out[30]:
A B C
0 -1.344312 foo 2013-01-01 00:00:00
1 0.844885 foo 2013-01-01 00:00:01
2 1.075770 foo 2013-01-01 00:00:02
3 -0.109050 foo 2013-01-01 00:00:03
4 1.643563 foo 2013-01-01 00:00:04
[5 rows x 3 columns]
In [31]: df["A"].to_pickle("s1.pkl.bz2")
In [32]: rt = pd.read_pickle("s1.pkl.bz2")
In [33]: rt.head()
Out[33]:
0 -1.344312
1 0.844885
2 1.075770
3 -0.109050
4 1.643563
Name: A, Length: 5, dtype: float64
UInt64のサポートの改善#
pandasは、符号なし、または純粋な非負整数を含む操作のサポートを大幅に改善しました。以前は、これらの整数を処理すると、不適切な丸めやデータ型キャストが発生し、誤った結果につながることがありました。特に、新しい数値インデックスであるUInt64Indexが作成されました (GH 14937)。
In [1]: idx = pd.UInt64Index([1, 2, 3])
In [2]: df = pd.DataFrame({'A': ['a', 'b', 'c']}, index=idx)
In [3]: df.index
Out[3]: UInt64Index([1, 2, 3], dtype='uint64')
配列のようなオブジェクトのオブジェクト要素を符号なし64ビット整数に変換する際のバグ (GH 4471、GH 14982)
符号なし64ビット整数がオーバーフローを引き起こしていた
Series.unique()のバグ (GH 14721)符号なし64ビット整数要素がオブジェクトに変換されていた
DataFrame構築のバグ (GH 14881)符号なし64ビット整数要素が誤ったデータ型に不適切に変換されていた
pd.read_csv()のバグ (GH 14983)符号なし64ビット整数がオーバーフローを引き起こしていた
pd.unique()のバグ (GH 14915)符号なし64ビット整数が出力で誤って切り捨てられていた
pd.value_counts()のバグ (GH 14934)
カテゴリカルデータでのGroupBy#
以前のバージョンでは、データに表示されないカテゴリを持つカテゴリカルシリーズでグループ化すると、.groupby(..., sort=False)はValueErrorで失敗していました。(GH 13179)
In [34]: chromosomes = np.r_[np.arange(1, 23).astype(str), ['X', 'Y']]
In [35]: df = pd.DataFrame({
....: 'A': np.random.randint(100),
....: 'B': np.random.randint(100),
....: 'C': np.random.randint(100),
....: 'chromosomes': pd.Categorical(np.random.choice(chromosomes, 100),
....: categories=chromosomes,
....: ordered=True)})
....:
In [36]: df
Out[36]:
A B C chromosomes
0 87 22 81 4
1 87 22 81 13
2 87 22 81 22
3 87 22 81 2
4 87 22 81 6
.. .. .. .. ...
95 87 22 81 8
96 87 22 81 11
97 87 22 81 X
98 87 22 81 1
99 87 22 81 19
[100 rows x 4 columns]
以前の動作:
In [3]: df[df.chromosomes != '1'].groupby('chromosomes', observed=False, sort=False).sum()
---------------------------------------------------------------------------
ValueError: items in new_categories are not the same as in old categories
新しい動作:
In [37]: df[df.chromosomes != '1'].groupby('chromosomes', observed=False, sort=False).sum()
Out[37]:
A B C
chromosomes
4 348 88 324
13 261 66 243
22 348 88 324
2 348 88 324
6 174 44 162
... ... .. ...
3 348 88 324
11 348 88 324
19 174 44 162
1 0 0 0
21 0 0 0
[24 rows x 3 columns]
テーブルスキーマ出力#
DataFrame.to_json()の新しいorient 'table'は、テーブルスキーマ互換のデータ文字列表現を生成します。
In [38]: df = pd.DataFrame(
....: {'A': [1, 2, 3],
....: 'B': ['a', 'b', 'c'],
....: 'C': pd.date_range('2016-01-01', freq='d', periods=3)},
....: index=pd.Index(range(3), name='idx'))
....:
In [39]: df
Out[39]:
A B C
idx
0 1 a 2016-01-01
1 2 b 2016-01-02
2 3 c 2016-01-03
[3 rows x 3 columns]
In [40]: df.to_json(orient='table')
Out[40]: '{"schema":{"fields":[{"name":"idx","type":"integer"},{"name":"A","type":"integer"},{"name":"B","type":"string"},{"name":"C","type":"datetime"}],"primaryKey":["idx"],"pandas_version":"1.4.0"},"data":[{"idx":0,"A":1,"B":"a","C":"2016-01-01T00:00:00.000"},{"idx":1,"A":2,"B":"b","C":"2016-01-02T00:00:00.000"},{"idx":2,"A":3,"B":"c","C":"2016-01-03T00:00:00.000"}]}'
詳細については、IO: テーブルスキーマを参照してください。
さらに、IPython (またはJupyterメッセージングプロトコルを使用するnteractなどの他のフロントエンド) を使用している場合、DataFrameおよびSeriesのreprは、SeriesまたはDataFrameのこのJSONテーブルスキーマ表現を公開できるようになりました。これにより、Jupyterノートブックやnteractなどのフロントエンドは、データに関するより多くの情報を持つため、pandasオブジェクトの表示方法に関してより柔軟になります。これを有効にするには、display.html.table_schemaオプションをTrueに設定する必要があります。
SparseDataFrameからのSciPyスパース行列#
pandasは、scipy.sparse.spmatrixインスタンスから直接疎データフレームを作成する機能をサポートするようになりました。詳細についてはドキュメントを参照してください。(GH 4343)
すべての疎形式がサポートされていますが、COOrdinate形式ではない行列は、必要に応じてデータをコピーして変換されます。
from scipy.sparse import csr_matrix
arr = np.random.random(size=(1000, 5))
arr[arr < .9] = 0
sp_arr = csr_matrix(arr)
sp_arr
sdf = pd.SparseDataFrame(sp_arr)
sdf
SparseDataFrameをCOO形式の疎SciPy行列に戻すには、次を使用します。
sdf.to_coo()
スタイル付きDataFrameのExcel出力#
openpyxlエンジンを使用してDataFrame.style形式をExcelにエクスポートする実験的サポートが追加されました。(GH 15530)
例えば、以下を実行すると、styled.xlsxは以下のようにレンダリングされます。
In [41]: np.random.seed(24)
In [42]: df = pd.DataFrame({'A': np.linspace(1, 10, 10)})
In [43]: df = pd.concat([df, pd.DataFrame(np.random.RandomState(24).randn(10, 4),
....: columns=list('BCDE'))],
....: axis=1)
....:
In [44]: df.iloc[0, 2] = np.nan
In [45]: df
Out[45]:
A B C D E
0 1.0 1.329212 NaN -0.316280 -0.990810
1 2.0 -1.070816 -1.438713 0.564417 0.295722
2 3.0 -1.626404 0.219565 0.678805 1.889273
3 4.0 0.961538 0.104011 -0.481165 0.850229
4 5.0 1.453425 1.057737 0.165562 0.515018
5 6.0 -1.336936 0.562861 1.392855 -0.063328
6 7.0 0.121668 1.207603 -0.002040 1.627796
7 8.0 0.354493 1.037528 -0.385684 0.519818
8 9.0 1.686583 -1.325963 1.428984 -2.089354
9 10.0 -0.129820 0.631523 -0.586538 0.290720
[10 rows x 5 columns]
In [46]: styled = (df.style
....: .applymap(lambda val: 'color:red;' if val < 0 else 'color:black;')
....: .highlight_max())
....:
In [47]: styled.to_excel('styled.xlsx', engine='openpyxl')
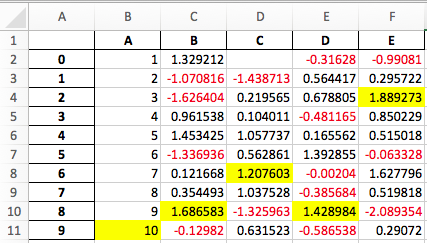
詳細についてはStyle documentationを参照してください。
IntervalIndex#
pandasは、独自のdtypeであるintervalを持つIntervalIndexと、Intervalスカラー型を獲得しました。これにより、区間表記法がファーストクラスでサポートされ、特にcut()とqcut()のカテゴリの戻り値の型としてサポートされます。IntervalIndexは独自のインデックス付けを可能にします。詳細はdocsを参照してください。(GH 7640、GH 8625)
警告
IntervalIndexのこれらのインデックス付け動作は暫定的なものであり、将来のpandasバージョンで変更される可能性があります。使用に関するフィードバックを歓迎します。
以前の動作
返されるカテゴリは文字列で、区間を表していました。
In [1]: c = pd.cut(range(4), bins=2)
In [2]: c
Out[2]:
[(-0.003, 1.5], (-0.003, 1.5], (1.5, 3], (1.5, 3]]
Categories (2, object): [(-0.003, 1.5] < (1.5, 3]]
In [3]: c.categories
Out[3]: Index(['(-0.003, 1.5]', '(1.5, 3]'], dtype='object')
新しい動作
In [48]: c = pd.cut(range(4), bins=2)
In [49]: c
Out[49]:
[(-0.003, 1.5], (-0.003, 1.5], (1.5, 3.0], (1.5, 3.0]]
Categories (2, interval[float64, right]): [(-0.003, 1.5] < (1.5, 3.0]]
In [50]: c.categories
Out[50]: IntervalIndex([(-0.003, 1.5], (1.5, 3.0]], dtype='interval[float64, right]')
さらに、これにより、他のデータと同じビンでビン分割することができ、NaNは他のdtypeと同様に欠損値を表します。
In [51]: pd.cut([0, 3, 5, 1], bins=c.categories)
Out[51]:
[(-0.003, 1.5], (1.5, 3.0], NaN, (-0.003, 1.5]]
Categories (2, interval[float64, right]): [(-0.003, 1.5] < (1.5, 3.0]]
IntervalIndexは、SeriesおよびDataFrameでインデックスとしても使用できます。
In [52]: df = pd.DataFrame({'A': range(4),
....: 'B': pd.cut([0, 3, 1, 1], bins=c.categories)
....: }).set_index('B')
....:
In [53]: df
Out[53]:
A
B
(-0.003, 1.5] 0
(1.5, 3.0] 1
(-0.003, 1.5] 2
(-0.003, 1.5] 3
[4 rows x 1 columns]
特定の区間による選択
In [54]: df.loc[pd.Interval(1.5, 3.0)]
Out[54]:
A 1
Name: (1.5, 3.0], Length: 1, dtype: int64
区間に含まれるスカラー値による選択。
In [55]: df.loc[0]
Out[55]:
A
B
(-0.003, 1.5] 0
(-0.003, 1.5] 2
(-0.003, 1.5] 3
[3 rows x 1 columns]
その他の機能強化#
DataFrame.rolling()が、ローリングウィンドウの終点の閉鎖を選択するためのパラメータclosed='right'|'left'|'both'|'neither'を受け入れるようになりました。詳細についてはドキュメントを参照してください (GH 13965)。feather-formatとの統合。新しいトップレベルのpd.read_feather()およびDataFrame.to_feather()メソッドについては、こちらを参照してください。Series.str.replace()が、re.subに渡される置換として呼び出し可能オブジェクトを受け入れるようになりました (GH 15055)。Series.str.replace()が、コンパイル済みの正規表現をパターンとして受け入れるようになりました (GH 15446)。Series.sort_indexが、パラメータkindとna_positionを受け入れるようになりました (GH 13589、GH 14444)。DataFrameとDataFrame.groupby()に、軸に沿った異なる値の数を数えるためのnunique()メソッドが追加されました (GH 14336、GH 15197)。DataFrameに、ワイド形式からロング形式へアンピボットするためのpd.melt()と同等のmelt()メソッドが追加されました (GH 12640)。pd.read_excel()が、sheetname=Noneを使用する際にシート順序を保持するようになりました (GH 9930)。小数点を含む複数のオフセットエイリアスがサポートされるようになりました (例:
0.5minは30sとして解析されます) (GH 8419)。Indexオブジェクトに.isnull()と.notnull()が追加され、SeriesAPIとの一貫性が向上しました (GH 15300)。ソートされていないMultiIndexにインデックス付け/スライスすると、新しい
UnsortedIndexError(KeyErrorのサブクラス)がスローされるようになりました (GH 11897)。これにより、ソート不足によるエラーと不正なキーによるエラーを区別できます。詳細はこちらを参照してください。MultiIndexに、DataFrameに変換するための.to_frame()メソッドが追加されました (GH 12397)。pd.cutとpd.qcutがdatetime64とtimedelta64 dtypeをサポートするようになりました (GH 14714、GH 14798)。pd.qcutに、重複したエッジでエラーを発生させるかどうかを制御するためのduplicates='raise'|'drop'オプションが追加されました (GH 7751)。SeriesがExcelファイルを出力するためのto_excelメソッドを提供します (GH 8825)。pd.read_csv()のusecols引数が、値として呼び出し可能関数を受け入れるようになりました (GH 14154)。pd.read_csv()のskiprows引数が、値として呼び出し可能関数を受け入れるようになりました (GH 10882)。pd.read_csv()のnrowsとchunksize引数は、両方が渡された場合にサポートされます (GH 6774、GH 15755)。DataFrame.plotは、suplots=Trueでtitleが文字列のリストである場合、各サブプロットの上にタイトルを表示するようになりました (GH 14753)。DataFrame.plotは、matplotlib 2.0のデフォルトのカラーサイクルを単一の文字列としてカラーパラメータに渡せるようになりました。詳細はこちらを参照してください。(GH 15516)Series.interpolate()が、method='time'でtimedeltaをインデックス型としてサポートするようになりました (GH 6424)。MultiIndexの指定されたレベルのラベル名を変更するために、
DataFrame/Series.renameにlevelキーワードが追加されました (GH 4160)。DataFrame.reset_index()は、タプルのindex.nameを、columnsがMultiIndexである場合、そのレベルをまたがるキーとして解釈するようになりました (GH 16164)。Timedelta.isoformatメソッドが追加され、TimedeltaをISO 8601期間としてフォーマットできるようになりました。詳細についてはTimedelta docsを参照してください (GH 15136)。.select_dtypes()が、タイムゾーン付きのdatetimeを汎用的に選択するために文字列datetimetzを許可するようになりました (GH 14910)。.to_latex()メソッドが、付属のLaTeX拡張機能を使用するためにmulticolumnおよびmultirow引数を受け入れるようになりました。pd.merge_asof()にdirection='backward'|'forward'|'nearest'オプションが追加されました (GH 14887)。Series/DataFrame.asfreq()に、欠損値を埋めるためのfill_valueパラメータが追加されました (GH 3715)。Series/DataFrame.resample.asfreqに、リサンプリング中の欠損値を埋めるためのfill_valueパラメータが追加されました (GH 3715)。pandas.util.hash_pandas_object()がMultiIndexをハッシュする機能を追加しました (GH 15224)。Series/DataFrame.squeeze()にaxisパラメータが追加されました。(GH 15339)DataFrame.to_excel()に新しいfreeze_panesパラメータが追加され、Excelへのエクスポート時にウィンドウ枠の固定をオンにできるようになりました (GH 15160)。pd.read_html()が複数のヘッダー行を解析し、MultiIndexヘッダーを作成するようになりました (GH 13434)。HTMLテーブル出力は、
colspanまたはrowspan属性が1の場合にスキップするようになりました。(GH 15403)pandas.io.formats.style.Stylerテンプレートに、拡張しやすくするためにブロックが追加されました。詳細については例のノートブックを参照してください (GH 15649)。Styler.render()が**kwargsを受け入れるようになり、テンプレート内でユーザー定義変数を許可するようになりました (GH 15649)。Jupyter notebook 5.0との互換性; MultiIndex列ラベルは左揃え、MultiIndex行ラベルは上揃えになりました (GH 15379)。
TimedeltaIndexが、ナノ秒レベルの精度に特化して設計されたカスタムの日付目盛りフォーマッタを持つようになりました (GH 8711)。pd.api.types.union_categoricalsにignore_ordered引数が追加され、結合されたカテゴリカルの順序属性を無視できるようになりました (GH 13410)。詳細についてはcategorical union docsを参照してください。DataFrame.to_latex()とDataFrame.to_string()が、オプションでヘッダーエイリアスを許可するようになりました。(GH 15536)pd.read_excel()のparse_datesキーワードが、文字列列を日付として解析するために再度有効になりました (GH 14326)。Indexのサブクラスに.emptyプロパティが追加されました。(GH 15270)TimedeltaおよびTimedeltaIndexに対する床除算が有効になりました (GH 15828)。pandas.io.json.json_normalize()にerrors='ignore'|'raise'オプションが追加されました。デフォルトはerrors='raise'で、これは後方互換性があります。(GH 14583)空の
listを持つpandas.io.json.json_normalize()は、空のDataFrameを返します (GH 15534)。pandas.io.json.json_normalize()に、結合されたフィールドを区切るためのstrを受け入れるsepオプションが追加されました。デフォルトは"."で、これは後方互換性があります。(GH 14883)MultiIndex.remove_unused_levels()が追加され、未使用のレベルを削除するのが容易になりました。(GH 15694)pd.read_csv()は、解析エラーが発生した場合にParserErrorエラーを発生させるようになりました (GH 15913、GH 15925)。pd.read_csv()が、Pythonパーサーに対してerror_bad_linesおよびwarn_bad_lines引数をサポートするようになりました (GH 15925)。display.show_dimensionsオプションは、Seriesのreprにその長さが表示されるかどうかを指定するためにも使用できるようになりました (GH 7117)。parallel_coordinates()にsort_labelsキーワード引数が追加され、クラスラベルとそれらに割り当てられた色がソートされるようになりました (GH 15908)。bottleneckとnumexprの使用をオン/オフするオプションが追加されました。詳細はこちらを参照してください (GH 16157)。DataFrame.style.bar()が、棒グラフをさらにカスタマイズするための2つのオプションを受け入れるようになりました。棒の配置はalign='left'|'mid'|'zero'で設定され、デフォルトは「left」で後方互換性があります。また、color=[color_negative, color_positive]のリストを渡すことができるようになりました。(GH 14757)
下位互換性のない API の変更#
pandas < 0.13.0で作成されたHDF5形式の互換性の可能性のある問題#
pd.TimeSeriesは、0.13.0以降すでにエイリアスでしたが、0.17.0で正式に非推奨となりました。pd.Seriesに置き換えられました。(GH 15098)。
これにより、以前のバージョンでpd.TimeSeriesを使用して作成されたHDF5ファイルが読み取れなくなる可能性があります。これはpandas < 0.13.0の場合に最も起こりやすいです。この状況になった場合、最近の以前のバージョンのpandasを使用してHDF5ファイルを読み込み、以下の手順を適用してから再度書き出すことができます。
In [2]: s = pd.TimeSeries([1, 2, 3], index=pd.date_range('20130101', periods=3))
In [3]: s
Out[3]:
2013-01-01 1
2013-01-02 2
2013-01-03 3
Freq: D, dtype: int64
In [4]: type(s)
Out[4]: pandas.core.series.TimeSeries
In [5]: s = pd.Series(s)
In [6]: s
Out[6]:
2013-01-01 1
2013-01-02 2
2013-01-03 3
Freq: D, dtype: int64
In [7]: type(s)
Out[7]: pandas.core.series.Series
インデックス型でのマップが他のインデックス型を返すようになりました#
Indexでのmapが、NumPy配列ではなくIndexを返すようになりました (GH 12766)。
In [56]: idx = pd.Index([1, 2])
In [57]: idx
Out[57]: Index([1, 2], dtype='int64')
In [58]: mi = pd.MultiIndex.from_tuples([(1, 2), (2, 4)])
In [59]: mi
Out[59]:
MultiIndex([(1, 2),
(2, 4)],
)
以前の動作
In [5]: idx.map(lambda x: x * 2)
Out[5]: array([2, 4])
In [6]: idx.map(lambda x: (x, x * 2))
Out[6]: array([(1, 2), (2, 4)], dtype=object)
In [7]: mi.map(lambda x: x)
Out[7]: array([(1, 2), (2, 4)], dtype=object)
In [8]: mi.map(lambda x: x[0])
Out[8]: array([1, 2])
新しい動作
In [60]: idx.map(lambda x: x * 2)
Out[60]: Index([2, 4], dtype='int64')
In [61]: idx.map(lambda x: (x, x * 2))
Out[61]:
MultiIndex([(1, 2),
(2, 4)],
)
In [62]: mi.map(lambda x: x)
Out[62]:
MultiIndex([(1, 2),
(2, 4)],
)
In [63]: mi.map(lambda x: x[0])
Out[63]: Index([1, 2], dtype='int64')
datetime64値を持つSeriesでのmapは、int32ではなくint64 dtypeを返す場合があります。
In [64]: s = pd.Series(pd.date_range('2011-01-02T00:00', '2011-01-02T02:00', freq='H')
....: .tz_localize('Asia/Tokyo'))
....:
In [65]: s
Out[65]:
0 2011-01-02 00:00:00+09:00
1 2011-01-02 01:00:00+09:00
2 2011-01-02 02:00:00+09:00
Length: 3, dtype: datetime64[ns, Asia/Tokyo]
以前の動作
In [9]: s.map(lambda x: x.hour)
Out[9]:
0 0
1 1
2 2
dtype: int32
新しい動作
In [66]: s.map(lambda x: x.hour)
Out[66]:
0 0
1 1
2 2
Length: 3, dtype: int64
インデックスのdatetimeフィールドへのアクセスがインデックスを返すようになりました#
DatetimeIndex、PeriodIndex、TimedeltaIndexのdatetime関連属性(概要はこちらを参照)は、以前はNumPy配列を返していました。これらは、ブールフィールドの場合を除き、新しいIndexオブジェクトを返すようになりました。ブールフィールドの場合、結果は引き続きブールnd配列になります。(GH 15022)
以前の動作
In [1]: idx = pd.date_range("2015-01-01", periods=5, freq='10H')
In [2]: idx.hour
Out[2]: array([ 0, 10, 20, 6, 16], dtype=int32)
新しい動作
In [67]: idx = pd.date_range("2015-01-01", periods=5, freq='10H')
In [68]: idx.hour
Out[68]: Index([0, 10, 20, 6, 16], dtype='int32')
これにより、特定のIndexメソッドが結果に対して引き続き利用可能であるという利点があります。一方、これには後方互換性の問題がある可能性があります。たとえば、NumPy配列と比較して、Indexオブジェクトは変更できません。元のndarrayを取得するには、常にnp.asarray(idx.hour)を使用して明示的に変換できます。
pd.uniqueは拡張型と一貫するようになります#
以前のバージョンでは、Categoricalおよびタイムゾーン対応のデータ型に対してSeries.unique()およびpandas.unique()を使用すると、異なる戻り値の型が生成されていました。これらは一貫性を持つようになりました。(GH 15903)
Datetime tz-aware
以前の動作
# Series In [5]: pd.Series([pd.Timestamp('20160101', tz='US/Eastern'), ...: pd.Timestamp('20160101', tz='US/Eastern')]).unique() Out[5]: array([Timestamp('2016-01-01 00:00:00-0500', tz='US/Eastern')], dtype=object) In [6]: pd.unique(pd.Series([pd.Timestamp('20160101', tz='US/Eastern'), ...: pd.Timestamp('20160101', tz='US/Eastern')])) Out[6]: array(['2016-01-01T05:00:00.000000000'], dtype='datetime64[ns]') # Index In [7]: pd.Index([pd.Timestamp('20160101', tz='US/Eastern'), ...: pd.Timestamp('20160101', tz='US/Eastern')]).unique() Out[7]: DatetimeIndex(['2016-01-01 00:00:00-05:00'], dtype='datetime64[ns, US/Eastern]', freq=None) In [8]: pd.unique([pd.Timestamp('20160101', tz='US/Eastern'), ...: pd.Timestamp('20160101', tz='US/Eastern')]) Out[8]: array(['2016-01-01T05:00:00.000000000'], dtype='datetime64[ns]')
新しい動作
# Series, returns an array of Timestamp tz-aware In [64]: pd.Series([pd.Timestamp(r'20160101', tz=r'US/Eastern'), ....: pd.Timestamp(r'20160101', tz=r'US/Eastern')]).unique() ....: Out[64]: <DatetimeArray> ['2016-01-01 00:00:00-05:00'] Length: 1, dtype: datetime64[ns, US/Eastern] In [65]: pd.unique(pd.Series([pd.Timestamp('20160101', tz='US/Eastern'), ....: pd.Timestamp('20160101', tz='US/Eastern')])) ....: Out[65]: <DatetimeArray> ['2016-01-01 00:00:00-05:00'] Length: 1, dtype: datetime64[ns, US/Eastern] # Index, returns a DatetimeIndex In [66]: pd.Index([pd.Timestamp('20160101', tz='US/Eastern'), ....: pd.Timestamp('20160101', tz='US/Eastern')]).unique() ....: Out[66]: DatetimeIndex(['2016-01-01 00:00:00-05:00'], dtype='datetime64[ns, US/Eastern]', freq=None) In [67]: pd.unique(pd.Index([pd.Timestamp('20160101', tz='US/Eastern'), ....: pd.Timestamp('20160101', tz='US/Eastern')])) ....: Out[67]: DatetimeIndex(['2016-01-01 00:00:00-05:00'], dtype='datetime64[ns, US/Eastern]', freq=None)
カテゴリカル
以前の動作
In [1]: pd.Series(list('baabc'), dtype='category').unique() Out[1]: [b, a, c] Categories (3, object): [b, a, c] In [2]: pd.unique(pd.Series(list('baabc'), dtype='category')) Out[2]: array(['b', 'a', 'c'], dtype=object)
新しい動作
# returns a Categorical In [68]: pd.Series(list('baabc'), dtype='category').unique() Out[68]: ['b', 'a', 'c'] Categories (3, object): ['a', 'b', 'c'] In [69]: pd.unique(pd.Series(list('baabc'), dtype='category')) Out[69]: ['b', 'a', 'c'] Categories (3, object): ['a', 'b', 'c']
S3ファイルハンドリング#
pandasはS3接続のハンドリングにs3fsを使用するようになりました。これにより既存のコードが壊れることはないはずです。ただし、s3fsは必須の依存関係ではないため、以前のバージョンのpandasのbotoと同様に、別途インストールする必要があります。(GH 11915)。
部分文字列インデックスの変更#
DatetimeIndexの部分文字列インデックスが、文字列の解決とインデックスの解決が一致する場合、両方が秒単位である場合を含め、厳密な一致として機能するようになりました (GH 14826)。詳細についてはスライス vs. 厳密な一致を参照してください。
In [70]: df = pd.DataFrame({'a': [1, 2, 3]}, pd.DatetimeIndex(['2011-12-31 23:59:59',
....: '2012-01-01 00:00:00',
....: '2012-01-01 00:00:01']))
....:
以前の動作
In [4]: df['2011-12-31 23:59:59']
Out[4]:
a
2011-12-31 23:59:59 1
In [5]: df['a']['2011-12-31 23:59:59']
Out[5]:
2011-12-31 23:59:59 1
Name: a, dtype: int64
新しい動作
In [4]: df['2011-12-31 23:59:59']
KeyError: '2011-12-31 23:59:59'
In [5]: df['a']['2011-12-31 23:59:59']
Out[5]: 1
異なるfloat dtypeの連結は自動的にアップキャストされません#
以前は、異なるfloat dtypesを持つ複数のオブジェクトをconcatすると、結果が自動的にfloat64 dtypeにアップキャストされていました。現在では、最小限許容されるdtypeが使用されます (GH 13247)。
In [71]: df1 = pd.DataFrame(np.array([1.0], dtype=np.float32, ndmin=2))
In [72]: df1.dtypes
Out[72]:
0 float32
Length: 1, dtype: object
In [73]: df2 = pd.DataFrame(np.array([np.nan], dtype=np.float32, ndmin=2))
In [74]: df2.dtypes
Out[74]:
0 float32
Length: 1, dtype: object
以前の動作
In [7]: pd.concat([df1, df2]).dtypes
Out[7]:
0 float64
dtype: object
新しい動作
In [75]: pd.concat([df1, df2]).dtypes
Out[75]:
0 float32
Length: 1, dtype: object
pandas Google BigQueryのサポートが移動しました#
pandasはGoogle BigQueryのサポートをpandas-gbqという別のパッケージに分割しました。conda install pandas-gbq -c conda-forgeまたはpip install pandas-gbqでインストールできます。read_gbq()とDataFrame.to_gbq()の機能は、現在リリースされているpandas-gbq=0.1.4と同じままです。ドキュメントはこちらでホストされるようになりました (GH 15347)。
インデックスのメモリ使用量がより正確になりました#
以前のバージョンでは、インデックスを持つpandas構造で.memory_usage()を表示すると、実際のインデックス値のみが含まれ、高速なインデックス付けを容易にする構造は含まれていませんでした。これは、IndexとMultiIndexでは一般的に異なり、他のインデックス型ではそれほどではありません。(GH 15237)
以前の動作
In [8]: index = pd.Index(['foo', 'bar', 'baz'])
In [9]: index.memory_usage(deep=True)
Out[9]: 180
In [10]: index.get_loc('foo')
Out[10]: 0
In [11]: index.memory_usage(deep=True)
Out[11]: 180
新しい動作
In [8]: index = pd.Index(['foo', 'bar', 'baz'])
In [9]: index.memory_usage(deep=True)
Out[9]: 180
In [10]: index.get_loc('foo')
Out[10]: 0
In [11]: index.memory_usage(deep=True)
Out[11]: 260
DataFrame.sort_indexの変更#
特定のケースでは、MultiIndexed DataFrameで.sort_index()を呼び出すと、ソートされていないように見えても、同じDataFrameが返されました。これは、lexsortedであるが非単調なレベルで発生しました。(GH 15622、GH 15687、GH 14015、GH 13431、GH 15797)
これは以前のバージョンから変更されていませんが、説明のために示しています。
In [81]: df = pd.DataFrame(np.arange(6), columns=['value'],
....: index=pd.MultiIndex.from_product([list('BA'), range(3)]))
....:
In [82]: df
Out[82]:
value
B 0 0
1 1
2 2
A 0 3
1 4
2 5
[6 rows x 1 columns]
In [87]: df.index.is_lexsorted()
Out[87]: False
In [88]: df.index.is_monotonic
Out[88]: False
ソートは期待通りに機能します。
In [76]: df.sort_index()
Out[76]:
a
2011-12-31 23:59:59 1
2012-01-01 00:00:00 2
2012-01-01 00:00:01 3
[3 rows x 1 columns]
In [90]: df.sort_index().index.is_lexsorted()
Out[90]: True
In [91]: df.sort_index().index.is_monotonic
Out[91]: True
しかし、この例では、非単調な第2レベルを持つため、期待通りの動作をしません。
In [77]: df = pd.DataFrame({'value': [1, 2, 3, 4]},
....: index=pd.MultiIndex([['a', 'b'], ['bb', 'aa']],
....: [[0, 0, 1, 1], [0, 1, 0, 1]]))
....:
In [78]: df
Out[78]:
value
a bb 1
aa 2
b bb 3
aa 4
[4 rows x 1 columns]
以前の動作
In [11]: df.sort_index()
Out[11]:
value
a bb 1
aa 2
b bb 3
aa 4
In [14]: df.sort_index().index.is_lexsorted()
Out[14]: True
In [15]: df.sort_index().index.is_monotonic
Out[15]: False
新しい動作
In [94]: df.sort_index()
Out[94]:
value
a aa 2
bb 1
b aa 4
bb 3
[4 rows x 1 columns]
In [95]: df.sort_index().index.is_lexsorted()
Out[95]: True
In [96]: df.sort_index().index.is_monotonic
Out[96]: True
GroupByの書式設定#
groupby.describe()の出力形式が変更され、describe()のメトリクスがインデックスではなく列に表示されるようになりました。この形式は、複数の関数を一度に適用する際のgroupby.agg()と一貫しています。(GH 4792)
以前の動作
In [1]: df = pd.DataFrame({'A': [1, 1, 2, 2], 'B': [1, 2, 3, 4]})
In [2]: df.groupby('A').describe()
Out[2]:
B
A
1 count 2.000000
mean 1.500000
std 0.707107
min 1.000000
25% 1.250000
50% 1.500000
75% 1.750000
max 2.000000
2 count 2.000000
mean 3.500000
std 0.707107
min 3.000000
25% 3.250000
50% 3.500000
75% 3.750000
max 4.000000
In [3]: df.groupby('A').agg(["mean", "std", "min", "max"])
Out[3]:
B
mean std amin amax
A
1 1.5 0.707107 1 2
2 3.5 0.707107 3 4
新しい動作
In [79]: df = pd.DataFrame({'A': [1, 1, 2, 2], 'B': [1, 2, 3, 4]})
In [80]: df.groupby('A').describe()
Out[80]:
B
count mean std min 25% 50% 75% max
A
1 2.0 1.5 0.707107 1.0 1.25 1.5 1.75 2.0
2 2.0 3.5 0.707107 3.0 3.25 3.5 3.75 4.0
[2 rows x 8 columns]
In [81]: df.groupby('A').agg(["mean", "std", "min", "max"])
Out[81]:
B
mean std min max
A
1 1.5 0.707107 1 2
2 3.5 0.707107 3 4
[2 rows x 4 columns]
ウィンドウのバイナリのcorr/cov操作がMultiIndex DataFrameを返すようになりました#
.rolling(..)、.expanding(..)、または.ewm(..)オブジェクトに対する.corr()や.cov()のようなバイナリウィンドウ操作は、Panelが非推奨になったため、Panelではなく2レベルのMultiIndexed DataFrameを返すようになりました。詳細はこちらを参照してください。これらは機能的には同等ですが、MultiIndexed DataFrameはpandasでより多くのサポートを受けています。詳細についてはウィンドウバイナリ操作のセクションを参照してください。(GH 15677)
In [82]: np.random.seed(1234)
In [83]: df = pd.DataFrame(np.random.rand(100, 2),
....: columns=pd.Index(['A', 'B'], name='bar'),
....: index=pd.date_range('20160101',
....: periods=100, freq='D', name='foo'))
....:
In [84]: df.tail()
Out[84]:
bar A B
foo
2016-04-05 0.640880 0.126205
2016-04-06 0.171465 0.737086
2016-04-07 0.127029 0.369650
2016-04-08 0.604334 0.103104
2016-04-09 0.802374 0.945553
[5 rows x 2 columns]
以前の動作
In [2]: df.rolling(12).corr()
Out[2]:
<class 'pandas.core.panel.Panel'>
Dimensions: 100 (items) x 2 (major_axis) x 2 (minor_axis)
Items axis: 2016-01-01 00:00:00 to 2016-04-09 00:00:00
Major_axis axis: A to B
Minor_axis axis: A to B
新しい動作
In [85]: res = df.rolling(12).corr()
In [86]: res.tail()
Out[86]:
bar A B
foo bar
2016-04-07 B -0.132090 1.000000
2016-04-08 A 1.000000 -0.145775
B -0.145775 1.000000
2016-04-09 A 1.000000 0.119645
B 0.119645 1.000000
[5 rows x 2 columns]
断面の相関行列の取得
In [87]: df.rolling(12).corr().loc['2016-04-07']
Out[87]:
bar A B
bar
A 1.00000 -0.13209
B -0.13209 1.00000
[2 rows x 2 columns]
HDFStoreのwhere文字列比較#
以前のバージョンでは、ほとんどの型はHDFStore内の文字列列と比較でき、通常は無効な比較になり、空の結果フレームを返していました。これらの比較は、現在TypeErrorを発生させるようになりました (GH 15492)。
In [88]: df = pd.DataFrame({'unparsed_date': ['2014-01-01', '2014-01-01']})
In [89]: df.to_hdf('store.h5', key='key', format='table', data_columns=True)
In [90]: df.dtypes
Out[90]:
unparsed_date object
Length: 1, dtype: object
以前の動作
In [4]: pd.read_hdf('store.h5', 'key', where='unparsed_date > ts')
File "<string>", line 1
(unparsed_date > 1970-01-01 00:00:01.388552400)
^
SyntaxError: invalid token
新しい動作
In [18]: ts = pd.Timestamp('2014-01-01')
In [19]: pd.read_hdf('store.h5', 'key', where='unparsed_date > ts')
TypeError: Cannot compare 2014-01-01 00:00:00 of
type <class 'pandas.tslib.Timestamp'> to string column
Index.intersectionと内部結合が左のIndexの順序を保持するようになりました#
Index.intersection()は、呼び出し元のIndex(左)の順序を、他のIndex(右)の順序ではなく、保持するようになりました (GH 15582)。これは内部結合、DataFrame.join()、merge()、および.alignメソッドに影響を与えます。
Index.intersectionIn [91]: left = pd.Index([2, 1, 0]) In [92]: left Out[92]: Index([2, 1, 0], dtype='int64') In [93]: right = pd.Index([1, 2, 3]) In [94]: right Out[94]: Index([1, 2, 3], dtype='int64')
以前の動作
In [4]: left.intersection(right) Out[4]: Int64Index([1, 2], dtype='int64')
新しい動作
In [95]: left.intersection(right) Out[95]: Index([2, 1], dtype='int64')
DataFrame.joinとpd.mergeIn [96]: left = pd.DataFrame({'a': [20, 10, 0]}, index=[2, 1, 0]) In [97]: left Out[97]: a 2 20 1 10 0 0 [3 rows x 1 columns] In [98]: right = pd.DataFrame({'b': [100, 200, 300]}, index=[1, 2, 3]) In [99]: right Out[99]: b 1 100 2 200 3 300 [3 rows x 1 columns]
以前の動作
In [4]: left.join(right, how='inner') Out[4]: a b 1 10 100 2 20 200
新しい動作
In [100]: left.join(right, how='inner') Out[100]: a b 2 20 200 1 10 100 [2 rows x 2 columns]
ピボットテーブルは常にDataFrameを返します#
pivot_table()のドキュメントには、常に DataFrameが返されると記載されています。ここでは、特定の状況下でSeriesが返される可能性があったバグが修正されました。(GH 4386)
In [101]: df = pd.DataFrame({'col1': [3, 4, 5],
.....: 'col2': ['C', 'D', 'E'],
.....: 'col3': [1, 3, 9]})
.....:
In [102]: df
Out[102]:
col1 col2 col3
0 3 C 1
1 4 D 3
2 5 E 9
[3 rows x 3 columns]
以前の動作
In [2]: df.pivot_table('col1', index=['col3', 'col2'], aggfunc="sum")
Out[2]:
col3 col2
1 C 3
3 D 4
9 E 5
Name: col1, dtype: int64
新しい動作
In [103]: df.pivot_table('col1', index=['col3', 'col2'], aggfunc="sum")
Out[103]:
col1
col3 col2
1 C 3
3 D 4
9 E 5
[3 rows x 1 columns]
その他の API の変更#
numexprのバージョンは2.4.6以上である必要があり、この要件が満たされていない場合は全く使用されません (GH 15213)。CParserErrorはpd.read_csv()でParserErrorに名前が変更され、将来的に削除されます (GH 12665)。SparseArray.cumsum()とSparseSeries.cumsum()は、それぞれ常にSparseArrayとSparseSeriesを返すようになります (GH 12855)。空の
DataFrameでDataFrame.applymap()を使用すると、Seriesではなく空のDataFrameのコピーが返されます (GH 8222)。Series.map()が、__missing__メソッドを持つ辞書サブクラス(例:collections.Counter)のデフォルト値を尊重するようになりました (GH 15999)。.locは、イテレータとNamedTupleを受け入れる点で.ixと互換性があります (GH 15120)。interpolate()とfillna()は、limitキーワード引数が0より大きくない場合、ValueErrorを発生させるようになりました。(GH 9217)pd.read_csv()は、dialectパラメータとユーザーによって提供された値が競合する場合、ParserWarningを発行するようになりました (GH 14898)。pd.read_csv()は、Cエンジンで引用符文字が1バイトよりも大きい場合、ValueErrorを発生させるようになりました (GH 11592)。inplace引数はブール値である必要があり、そうでない場合はValueErrorがスローされます (GH 14189)。pandas.api.types.is_datetime64_ns_dtypeは、pandas.api.types.is_datetime64_any_dtypeと同様に、タイムゾーン対応のdtypeに対してTrueを報告するようになりました。DataFrame.asof()は、一致が見つからなかった場合、スカラーNaNではなくnullで埋められたSeriesを返すようになりました (GH 15118)。NDFrameオブジェクトでの
copy.copy()およびcopy.deepcopy()関数の具体的なサポート (GH 15444)Series.sort_values()が、DataFrame.sort_values()の動作との一貫性のために、ブールの1要素リストを受け入れるようになりました (GH 15604)。categorydtypeの列に対する.merge()と.join()は、可能な限りカテゴリdtypeを保持するようになりました (GH 10409)。SparseDataFrame.default_fill_valueは0になります。以前はpd.get_dummies(..., sparse=True)からの戻り値ではnanでした (GH 15594)。Series.str.matchのデフォルトの動作が、グループの抽出からパターンのマッチングに変更されました。抽出動作はpandasバージョン0.13.0から非推奨となっており、Series.str.extractメソッドで実行できます (GH 5224)。その結果、as_indexerキーワードは無視され(新しい動作を指定するために不要)、非推奨になりました。NaTが、is_month_startのようなdatetimelikeなブール演算に対して、正しくFalseを報告するようになりました (GH 15781)。NaTは、TimedeltaおよびPeriodアクセッサ(例:daysやquarter)に対して、正しくnp.nanを返すようになりました (GH 15782)。NaTは、tz_localizeおよびtz_convertメソッドに対してNaTを返すようになりました (GH 15830)。DataFrameとPanelコンストラクタは、スカラー入力を軸なしで呼び出すと、PandasErrorではなくValueErrorを発生させるようになりました (GH 15541)。DataFrameとPanelのコンストラクタは、スカラー入力を軸なしで呼び出すと、pandas.core.common.PandasErrorではなくValueErrorを発生させるようになりました。例外PandasErrorも削除されました。(GH 15541)例外
pandas.core.common.AmbiguousIndexErrorは参照されていないため削除されました (GH 15541)。
ライブラリの再編成:プライバシーの変更#
モジュールのプライバシーが変更されました#
以前は公開されていた一部のPython/C/C++/Cython拡張モジュールが移動および/または名前変更されました。これらはすべて公開APIから削除されました。さらに、pandas.core、pandas.compat、およびpandas.utilトップレベルモジュールは現在PRIVATEとみなされます。これらのモジュールを参照すると、指示があった場合、非推奨警告が発行されます。(GH 12588)
以前の場所 |
新しい場所 |
非推奨 |
|---|---|---|
pandas.lib |
pandas._libs.lib |
X |
pandas.tslib |
pandas._libs.tslib |
X |
pandas.computation |
pandas.core.computation |
X |
pandas.msgpack |
pandas.io.msgpack |
|
pandas.index |
pandas._libs.index |
|
pandas.algos |
pandas._libs.algos |
|
pandas.hashtable |
pandas._libs.hashtable |
|
pandas.indexes |
pandas.core.indexes |
|
pandas.json |
pandas._libs.json / pandas.io.json |
X |
pandas.parser |
pandas._libs.parsers |
X |
pandas.formats |
pandas.io.formats |
|
pandas.sparse |
pandas.core.sparse |
|
pandas.tools |
pandas.core.reshape |
X |
pandas.types |
pandas.core.dtypes |
X |
pandas.io.sas.saslib |
pandas.io.sas._sas |
|
pandas._join |
pandas._libs.join |
|
pandas._hash |
pandas._libs.hashing |
|
pandas._period |
pandas._libs.period |
|
pandas._sparse |
pandas._libs.sparse |
|
pandas._testing |
pandas._libs.testing |
|
pandas._window |
pandas._libs.window |
トップレベルの名前空間に直接公開されていないパブリック機能を持ついくつかの新しいサブパッケージが作成されました。pandas.errors、pandas.plotting、およびpandas.testing(詳細は後述)。これらは、pandas.api.typesおよびpandas.ioおよびpandas.tseriesサブモジュールの一部の関数とともに、現在のパブリックサブパッケージです。
さらなる変更
関数
union_categoricals()は、以前はpandas.types.concatからインポートできましたが、現在はpandas.api.typesからインポートできるようになりました (GH 15998)。型インポート
pandas.tslib.NaTTypeは非推奨となり、type(pandas.NaT)を使用して置き換えることができます (GH 16146)。pandas.tools.hashing内の公開関数は、その場所から非推奨となりましたが、現在はpandas.utilからインポートできるようになりました (GH 16223)。pandas.util内のモジュール:decorators,print_versions,doctools,validators,depr_moduleはプライベートになりました。pandas.util自体で公開されている関数のみが公開されています (GH 16223)。
pandas.errors#
すべてのpandas例外と警告のための標準的な公開モジュールpandas.errorsを追加しています。(GH 14800)。以前は、これらの例外と警告はpandas.core.commonまたはpandas.io.commonからインポートできました。これらの例外と警告は、将来のリリースで*.commonの場所から削除されます。(GH 15541)
以下がこのAPIの一部となりました。
['DtypeWarning',
'EmptyDataError',
'OutOfBoundsDatetime',
'ParserError',
'ParserWarning',
'PerformanceWarning',
'UnsortedIndexError',
'UnsupportedFunctionCall']
pandas.testing#
公開テスト関数を公開する標準モジュールpandas.testingを追加しています (GH 9895)。これらの関数は、pandasオブジェクトを使用する機能のテストを作成する際に使用できます。
以下のテスト関数がこのAPIの一部となりました。
pandas.plotting#
以前は pandas.tools.plotting またはトップレベルの名前空間にあったプロット機能を持つ、新しい公開モジュール pandas.plotting が追加されました。詳細については、非推奨セクションを参照してください。
その他の開発上の変更点#
非推奨#
.ix の非推奨化#
.ix インデクサーは非推奨となり、より厳密な .iloc および .loc インデクサーが推奨されます。.ix は、ユーザーが何をしたいのかを推測する上で多くのマジックを提供します。より具体的には、.ix はインデックスのデータ型に応じて、位置的 または ラベル によるインデックス付けを決定できます。これにより、長年にわたり多くのユーザーの混乱を招いてきました。完全なインデックス付けのドキュメントはこちらです。 (GH 14218)
推奨されるインデックス付け方法は以下のとおりです。
ラベル でインデックス付けしたい場合は
.loc位置的 にインデックス付けしたい場合は
.iloc
.ix を使用すると、コードを変換する方法の例へのリンク付きで DeprecationWarning が表示されるようになりましたこちら。
In [104]: df = pd.DataFrame({'A': [1, 2, 3],
.....: 'B': [4, 5, 6]},
.....: index=list('abc'))
.....:
In [105]: df
Out[105]:
A B
a 1 4
b 2 5
c 3 6
[3 rows x 2 columns]
以前の動作では、「A」列のインデックスから0番目と2番目の要素を取得したい場合。
In [3]: df.ix[[0, 2], 'A']
Out[3]:
a 1
c 3
Name: A, dtype: int64
.loc を使用。ここでは、インデックスから適切なインデックスを選択し、ラベル インデックスを使用します。
In [106]: df.loc[df.index[[0, 2]], 'A']
Out[106]:
a 1
c 3
Name: A, Length: 2, dtype: int64
.iloc を使用。ここでは、「A」列の位置を取得し、位置的 インデックスを使用して要素を選択します。
In [107]: df.iloc[[0, 2], df.columns.get_loc('A')]
Out[107]:
a 1
c 3
Name: A, Length: 2, dtype: int64
パネルの非推奨化#
Panel は非推奨となり、将来のバージョンで削除されます。3次元データを表現する推奨される方法は、to_frame() を使用した DataFrame 上の MultiIndex、または xarray パッケージを使用することです。pandas はこの変換を自動化する to_xarray() メソッドを提供します (GH 13563)。
In [133]: import pandas._testing as tm
In [134]: p = tm.makePanel()
In [135]: p
Out[135]:
<class 'pandas.core.panel.Panel'>
Dimensions: 3 (items) x 3 (major_axis) x 4 (minor_axis)
Items axis: ItemA to ItemC
Major_axis axis: 2000-01-03 00:00:00 to 2000-01-05 00:00:00
Minor_axis axis: A to D
MultiIndex DataFrame に変換する
In [136]: p.to_frame()
Out[136]:
ItemA ItemB ItemC
major minor
2000-01-03 A 0.628776 -1.409432 0.209395
B 0.988138 -1.347533 -0.896581
C -0.938153 1.272395 -0.161137
D -0.223019 -0.591863 -1.051539
2000-01-04 A 0.186494 1.422986 -0.592886
B -0.072608 0.363565 1.104352
C -1.239072 -1.449567 0.889157
D 2.123692 -0.414505 -0.319561
2000-01-05 A 0.952478 -2.147855 -1.473116
B -0.550603 -0.014752 -0.431550
C 0.139683 -1.195524 0.288377
D 0.122273 -1.425795 -0.619993
[12 rows x 3 columns]
xarray DataArray に変換する
In [137]: p.to_xarray()
Out[137]:
<xarray.DataArray (items: 3, major_axis: 3, minor_axis: 4)>
array([[[ 0.628776, 0.988138, -0.938153, -0.223019],
[ 0.186494, -0.072608, -1.239072, 2.123692],
[ 0.952478, -0.550603, 0.139683, 0.122273]],
[[-1.409432, -1.347533, 1.272395, -0.591863],
[ 1.422986, 0.363565, -1.449567, -0.414505],
[-2.147855, -0.014752, -1.195524, -1.425795]],
[[ 0.209395, -0.896581, -0.161137, -1.051539],
[-0.592886, 1.104352, 0.889157, -0.319561],
[-1.473116, -0.43155 , 0.288377, -0.619993]]])
Coordinates:
* items (items) object 'ItemA' 'ItemB' 'ItemC'
* major_axis (major_axis) datetime64[ns] 2000-01-03 2000-01-04 2000-01-05
* minor_axis (minor_axis) object 'A' 'B' 'C' 'D'
groupby.agg() を辞書でリネームする場合の非推奨化#
.groupby(..).agg(..)、.rolling(..).agg(..)、および .resample(..).agg(..) の構文は、スカラー、リスト、および列名をスカラーまたはリストに対応付ける辞書を含む、様々な入力を受け入れることができます。これは、複数の(潜在的に異なる)集計を構築するのに便利な構文を提供します。
しかし、.agg(..) は、結果の列の「名前変更」を可能にする辞書も受け入れることができます。これは、Series と DataFrame の間で一貫性がなく、複雑で紛らわしい構文です。この「名前変更」機能は非推奨となります。
グループ化/ロール化/リサンプリングされた
Seriesに辞書を渡すことは非推奨となります。これにより、結果の集計をrenameすることができましたが、これは列から集計を受け入れるグループ化されたDataFrameに辞書を渡すのとは全く異なる意味を持っていました。同様に、グループ化/ロール化/リサンプリングされた
DataFrameに辞書の辞書を渡すことも非推奨となります。
これは説明のための例です
In [108]: df = pd.DataFrame({'A': [1, 1, 1, 2, 2],
.....: 'B': range(5),
.....: 'C': range(5)})
.....:
In [109]: df
Out[109]:
A B C
0 1 0 0
1 1 1 1
2 1 2 2
3 2 3 3
4 2 4 4
[5 rows x 3 columns]
異なる列に対して異なる集計を計算するための一般的な便利な構文です。これは自然で便利な構文です。指定された列を取り、関数のリストを適用することで、辞書からリストへの集計を行います。これは列に MultiIndex を返します (これは非推奨ではありません)。
In [110]: df.groupby('A').agg({'B': 'sum', 'C': 'min'})
Out[110]:
B C
A
1 3 0
2 7 3
[2 rows x 2 columns]
ここでは、最初の非推奨化の例として、グループ化された Series に辞書を渡す場合を示します。これは集計と名前変更の組み合わせです。
In [6]: df.groupby('A').B.agg({'foo': 'count'})
FutureWarning: using a dict on a Series for aggregation
is deprecated and will be removed in a future version
Out[6]:
foo
A
1 3
2 2
同じ操作を、より慣用的な方法で実現できます。
In [111]: df.groupby('A').B.agg(['count']).rename(columns={'count': 'foo'})
Out[111]:
foo
A
1 3
2 2
[2 rows x 1 columns]
ここでは、2番目の非推奨化の例として、グループ化された DataFrame に辞書の辞書を渡す場合を示します。
In [23]: (df.groupby('A')
...: .agg({'B': {'foo': 'sum'}, 'C': {'bar': 'min'}})
...: )
FutureWarning: using a dict with renaming is deprecated and
will be removed in a future version
Out[23]:
B C
foo bar
A
1 3 0
2 7 3
ほぼ同じことを次のようにして実現できます。
In [112]: (df.groupby('A')
.....: .agg({'B': 'sum', 'C': 'min'})
.....: .rename(columns={'B': 'foo', 'C': 'bar'})
.....: )
.....:
Out[112]:
foo bar
A
1 3 0
2 7 3
[2 rows x 2 columns]
.plotting の非推奨化#
pandas.tools.plotting モジュールは非推奨となり、トップレベルの pandas.plotting モジュールが推奨されます。すべての公開されているプロット関数は pandas.plotting から利用できるようになりました (GH 12548)。
さらに、トップレベルの pandas.scatter_matrix および pandas.plot_params は非推奨です。ユーザーはこれらを pandas.plotting からインポートすることもできます。
以前のスクリプト
pd.tools.plotting.scatter_matrix(df)
pd.scatter_matrix(df)
以下のように変更する必要があります。
pd.plotting.scatter_matrix(df)
その他の非推奨化#
SparseArray.to_dense()のfillパラメーターは、以前尊重されていなかったため非推奨となりました (GH 14647)SparseSeries.to_dense()のsparse_onlyパラメーターは非推奨となりました (GH 14647)Series.repeat()のrepsパラメーターはrepeatsに置き換えられ非推奨となりました (GH 12662)Seriesコンストラクターと.astypeメソッドは、dtypeパラメーターに周波数なしのタイムスタンプ dtype (例:np.datetime64) を受け入れることを非推奨としました (GH 15524)Index.repeat()およびMultiIndex.repeat()のnパラメーターはrepeatsに置き換えられ非推奨となりました (GH 12662)Categorical.searchsorted()とSeries.searchsorted()のvパラメーターはvalueに置き換えられ非推奨となりました (GH 12662)TimedeltaIndex.searchsorted(),DatetimeIndex.searchsorted(), およびPeriodIndex.searchsorted()のkeyパラメーターはvalueに置き換えられ非推奨となりました (GH 12662)DataFrame.astype()のraise_on_errorパラメーターはerrorsに置き換えられ非推奨となりました (GH 14878)Series.sortlevelおよびDataFrame.sortlevelは、Series.sort_indexおよびDataFrame.sort_indexに置き換えられ非推奨となりました (GH 15099)pandas.tools.mergeからconcatをインポートすることは、pandas名前空間からのインポートに置き換えられ非推奨となりました。これは明示的なインポートにのみ影響するはずです (GH 15358)Series/DataFrame/Panel.consolidate()は公開メソッドとして非推奨となりました。 (GH 15483)Series.str.match()のas_indexerキーワードは非推奨となりました (無視されるキーワード) (GH 15257)。以下のトップレベルの pandas 関数は非推奨となり、将来のバージョンで削除されます (GH 13790, GH 15940)
pd.pnow()はPeriod.now()に置き換えられましたpd.Termはユーザーコードには適用されないため削除されました。代わりに HDFStore で検索する際に where 句でインライン文字列式を使用してください。pd.Exprはユーザーコードには適用されないため削除されました。pd.match()は削除されました。pd.groupby()は、Series/DataFrameで直接.groupby()メソッドを使用することに置き換えられました。pd.get_store()はpd.HDFStore(...)の直接呼び出しに置き換えられました。
is_any_int_dtype、is_floating_dtype、およびis_sequenceはpandas.api.typesから非推奨となりました (GH 16042)
以前のバージョンの非推奨/変更の削除#
pandas.rpyモジュールは削除されました。同様の機能は rpy2 プロジェクトを通じてアクセスできます。詳細については、R インターフェースのドキュメントを参照してください。google-analyticsインターフェースを持つpandas.io.gaモジュールは削除されました (GH 11308)。同様の機能は Google2Pandas パッケージで見つけることができます。pd.to_datetimeとpd.to_timedeltaはcoerceパラメーターをerrorsに置き換え非推奨としました (GH 13602)pandas.stats.fama_macbeth、pandas.stats.ols、pandas.stats.plm、およびpandas.stats.var、ならびにトップレベルのpandas.fama_macbethおよびpandas.olsルーチンは削除されました。同様の機能は statsmodels パッケージで見つけることができます。 (GH 11898)SeriesおよびSparseSeriesのエイリアスであるTimeSeriesおよびSparseTimeSeriesクラスは削除されました (GH 10890, GH 15098)。Series.is_time_seriesはSeries.index.is_all_datesに置き換えられ削除されました (GH 15098)非推奨となった
irow,icol,iget,iget_valueメソッドは、こちらで説明されているようにilocとiatに置き換えられ削除されました (GH 10711)。非推奨となった
DataFrame.iterkv()はDataFrame.iteritems()に置き換えられ削除されました (GH 10711)Categoricalコンストラクターはnameパラメーターを削除しました (GH 10632)CategoricalはNaNカテゴリのサポートを削除しました (GH 10748)take_lastパラメーターはduplicated(),drop_duplicates(),nlargest(), およびnsmallest()メソッドから削除されました (GH 10236, GH 10792, GH 10920)Series、Index、およびDataFrameはsortおよびorderメソッドを削除しました (GH 10726)pytablesの where 句は文字列および式型としてのみ受け入れられ、他のデータ型では受け入れられません (GH 12027)DataFrameはcombineAddおよびcombineMultメソッドを、それぞれaddおよびmulに置き換え削除しました (GH 10735)
パフォーマンス改善#
pd.wide_to_long()のパフォーマンスが改善されました (GH 14779)pd.factorize()のパフォーマンスが改善されました。文字列と推測されるobjectdtype の場合、GIL が解放されます (GH 14859, GH 16057)不規則な DatetimeIndex (または
compat_x=True) を持つ時系列プロットのパフォーマンスが改善されました (GH 15073)。groupby().cummin()とgroupby().cummax()のパフォーマンスが改善されました (GH 15048, GH 15109, GH 15561, GH 15635)MultiIndexを使用したインデックス付けのパフォーマンスが改善され、メモリが削減されました (GH 15245)read_sas()メソッドで、指定された形式なしでバッファオブジェクトを読み込む際、バッファオブジェクトではなくファイルパス文字列が推測されるようになりました。 (GH 14947)カテゴリカルデータに対する
.rank()のパフォーマンスが改善されました (GH 15498).unstack()を使用する際のパフォーマンスが改善されました (GH 15503)category列でのマージ/結合のパフォーマンスが改善されました (GH 10409)bool列でのdrop_duplicates()のパフォーマンスが改善されました (GH 12963)適用される関数がグループ DataFrame の
.name属性を使用した場合のpd.core.groupby.GroupBy.applyのパフォーマンスが改善されました (GH 15062)。リストまたは配列を使用した
ilocインデックス付けのパフォーマンスが改善されました (GH 15504)。単調なインデックスを持つ
Series.sort_index()のパフォーマンスが改善されました (GH 15694)一部のプラットフォームでのバッファリングされた読み込みで
pd.read_csv()のパフォーマンスが改善されました (GH 16039)
バグ修正#
変換#
Timestamp.replaceのバグで、以前はValueErrorが発生していましたが、誤った引数名が与えられた場合にTypeErrorが発生するようになりました (GH 15240)Timestamp.replaceのバグで、長い整数を渡す際の互換性が確保されました (GH 15030)タイムゾーンが指定された場合に、
Timestampが UTC ベースの時刻/日付属性を返すバグ (GH 13303, GH 6538)TimedeltaIndexの加算で、エラーなしでオーバーフローが許容されていたバグ (GH 14816)TimedeltaIndexでlocを使用してブールインデックス付けを行うとValueErrorが発生するバグ (GH 14946)Timestamp+Timedelta/Offset演算でのオーバーフローをキャッチする際のバグ (GH 15126)DatetimeIndex.round()とTimestamp.round()のバグで、ミリ秒以下で丸める際の浮動小数点精度が不正確だった問題 (GH 14440, GH 15578)astype()のバグで、inf値が誤って整数に変換されていました。現在では、Series および DataFrame のastype()でエラーが発生するようになりました (GH 14265)値が decimal.Decimal 型の場合の
DataFrame(..).apply(to_numeric)のバグ。 (GH 14827)describe()のバグで、percentilesキーワード引数に中央値を含まない numpy 配列を渡した場合に問題がありました (GH 14908)PeriodIndexコンストラクターをクリーンアップし、浮動小数点数に対してより一貫してエラーを発生させるようにしました (GH 13277)空の NDFrame オブジェクトで
__deepcopy__を使用する際のバグ (GH 15370).replace()のバグにより、dtypes が正しくない場合があります。 (GH 12747, GH 15765)空の置換辞書で失敗する
Series.replaceおよびDataFrame.replaceのバグ (GH 15289)数値を文字列に置き換える
Series.replaceのバグ (GH 15743)NaN要素と指定された整数 dtype を持つIndexの構築におけるバグ (GH 15187)datetimetz を使用した
Series構築のバグ (GH 14928)Series.dt.round()のバグで、異なる引数を持つNaTで一貫性のない動作が発生していました (GH 14940)Seriesコンストラクターで、copy=Trueとdtype引数が両方指定された場合のバグ (GH 15125)空の
DataFrameに対する比較メソッド(例:lt、gt、…)が定数と比較された場合、不正な dtype のSeriesが返されるバグ (GH 15077)タイムゾーン対応の datetime を含む混合 dtype の
Series.ffill()のバグ。 (GH 14956)DataFrame.fillna()のバグで、fillna 値がdict型の場合に引数downcastが無視されていた問題 (GH 15277).asfreq()のバグで、空のSeriesの周波数が設定されていなかった問題 (GH 14320)リストのようなものに null と datetime を含む
DataFrame構築のバグ (GH 15869)タイムゾーン対応の datetime を含む
DataFrame.fillna()のバグ (GH 15855)is_string_dtype、is_timedelta64_ns_dtype、およびis_string_like_dtypeのバグで、Noneが渡されたときにエラーが発生していました (GH 15941)pd.uniqueがCategoricalに対して ndarray を返し、Categoricalを返していなかったバグ (GH 15903)Index.to_series()のバグで、インデックスがコピーされなかったため(後に変更すると元のインデックスも変更される)、問題が発生していました (GH 15949)長さが1の DataFrame で部分文字列インデックス付けを行う際のバグ (GH 16071)
Series構築のバグで、無効な dtype を渡してもエラーが発生しませんでした。 (GH 15520)
インデックス付け#
反転されたオペランドを持つ
Indexの累乗演算のバグ (GH 14973)DataFrame.sort_values()のバグで、複数の列でソートする際に、1つの列がint64型でNaTを含んでいると問題が発生していました (GH 14922)DataFrame.reindex()のバグで、columnsを渡すときにmethodが無視されていた問題 (GH 14992)DataFrame.locのバグで、MultiIndexをSeriesインデクサーでインデックス付けする際に問題が発生していました (GH 14730, GH 15424)DataFrame.locのバグで、MultiIndexを numpy 配列でインデックス付けする際に問題が発生していました (GH 15434)Series.asofのバグで、シリーズがすべてnp.nanを含んでいる場合にエラーが発生していました (GH 15713)タイムゾーン対応の列から選択する際の
.atのバグ (GH 15822)Series.where()とDataFrame.where()のバグで、配列のような条件が拒否されていました (GH 15414)Series.where()のバグで、TZ-aware データが浮動小数点表現に変換されていました (GH 15701)DataFrame のスカラーアクセスで正しい dtype を返さない
.locのバグ (GH 11617)Categorical.searchsorted()のバグで、提供されたカテゴリ順ではなくアルファベット順が使用されていました (GH 14522)Series.ilocのバグで、リストのようなインデックス入力の場合にCategoricalオブジェクトが返され、本来はSeriesが期待されていました。 (GH 14580)datetimelike を空のフレームと比較する
DataFrame.isinのバグ (GH 15473).reset_index()のバグで、MultiIndexのすべてのNaNレベルが失敗する問題 (GH 6322).reset_index()のバグで、MultiIndexの列にインデックス名が既に存在する場合にエラーが発生する問題 (GH 16120)タプルを使って
MultiIndexを作成する際に、名前のリストを渡さないとValueErrorが発生するようになりました (GH 15110)MultiIndexと切り捨てを伴う HTML 表示のバグ (GH 14882).info()の表示バグで、文字列以外のみを含むMultiIndexの場合、常に修飾子 (+) が表示されていました (GH 15245)pd.concat()のバグで、入力DataFrameのMultiIndexの名前にNoneが含まれている場合、結果のDataFrameのMultiIndexの名前が正しく処理されない問題 (GH 15787)DataFrame.sort_index()とSeries.sort_index()のバグで、na_positionがMultiIndexで機能しない問題 (GH 14784, GH 16604)CategoricalIndexを持つオブジェクトを結合する際のpd.concat()のバグ (GH 16111)スカラーと
CategoricalIndexを用いたインデックス付けのバグ (GH 16123)
IO#
pd.to_numeric()のバグで、float と符号なし整数要素が誤ってキャストされていた問題 (GH 14941, GH 15005)pd.read_fwf()のバグで、列幅推測時に skiprows パラメータが尊重されていなかった問題 (GH 11256)pd.read_csv()のバグで、dialectパラメータが処理前に検証されていなかった問題 (GH 14898)pd.read_csv()のバグで、usecolsを使用した場合に欠損データが誤って処理されていた問題 (GH 6710)pd.read_csv()のバグで、多数の列を持つ行の後に少数の列を持つ行が続くファイルがクラッシュを引き起こす問題 (GH 14125)pd.read_csv()の C エンジンでのバグで、parse_datesとusecolsのインデックス付けが誤っていた問題 (GH 14792)pd.read_csv()のバグで、複数行ヘッダーが指定された場合にparse_datesが正しく機能しなかった問題 (GH 15376)pd.read_csv()のバグで、float_precision='round_trip'を指定すると、テキストエントリがパースされたときにセグメンテーション違反が発生する問題 (GH 15140)pd.read_csv()のバグで、インデックスが指定され、null 値として何も指定されていない場合に問題がありました (GH 15835)pd.read_csv()のバグで、特定の無効なファイルオブジェクトが Python インタープリターをクラッシュさせる問題 (GH 15337)pd.read_csv()のバグで、nrowsおよびchunksizeに無効な値が許容されていた問題 (GH 15767)pd.read_csv()の Python エンジンでのバグで、パースエラーが発生した際に役立たないエラーメッセージが表示されていた問題 (GH 15910)pd.read_csv()のバグで、skipfooterパラメーターが適切に検証されていなかった問題 (GH 15925)pd.to_csv()のバグで、タイムスタンプインデックスが書き込まれる際に数値オーバーフローが発生していました (GH 15982)pd.util.hashing.hash_pandas_object()のバグで、カテゴリカルのハッシュ化が、値だけでなくカテゴリの順序にも依存していた問題 (GH 15143).to_json()のバグで、lines=Trueかつ内容(キーまたは値)にエスケープ文字が含まれている場合に問題が発生していました (GH 15096).to_json()のバグで、シングルバイトの ASCII 文字が4バイトの Unicode に展開されていました (GH 15344).to_json()の C エンジンでのバグで、分数部が奇数で差が正確に 0.5 の場合にロールオーバーが正しく処理されていなかった問題 (GH 15716, GH 15864)Python 2 の
pd.read_json()のバグで、lines=Trueかつ内容に非 ASCII Unicode 文字が含まれている場合に問題が発生していました (GH 15132)pd.read_msgpack()のバグで、Seriesカテゴリカルが誤って処理されていた問題 (GH 14901)pd.read_msgpack()のバグで、CategoricalIndex型のインデックスを持つデータフレームをロードできなかった問題 (GH 15487)pd.read_msgpack()のバグで、CategoricalIndexを逆シリアル化する際に問題がありました (GH 15487)タイムゾーンを持つ
DatetimeIndexを変換する際のDataFrame.to_records()のバグ (GH 13937)列名にユニコード文字が含まれている場合に失敗する
DataFrame.to_records()のバグ (GH 11879)数値インデックス名を持つ DataFrame を書き込む際の
.to_sql()のバグ (GH 15404)。DataFrame.to_html()のバグで、index=Falseとmax_rowsがIndexErrorを発生させていた問題 (GH 14998)pd.read_hdf()のバグで、日付以外の列を持つwhereパラメーターにTimestampを渡す際に問題が発生していました (GH 15492)DataFrame.to_stata()およびStataWriterのバグで、一部のロケールで誤った形式のファイルが生成される問題 (GH 13856)StataReaderおよびStataWriterのバグで、無効なエンコーディングが許可されていた問題 (GH 15723)Seriesの repr 形式のバグで、出力が切り捨てられた場合に長さが表示されなかった問題 (GH 15962)。
プロット#
DataFrame.histのバグで、plt.tight_layoutがAttributeErrorを発生させていました (matplotlib >= 2.0.1を使用) (GH 9351)DataFrame.boxplotのバグで、fontsizeが両軸の目盛りラベルに適用されていなかった問題 (GH 15108)matplotlib に登録されている pandas の日付と時刻のコンバーターが複数の次元を処理しないバグ (GH 16026)
pd.scatter_matrix()のバグで、colorまたはcのいずれかを受け入れたが、両方は受け入れなかった問題 (GH 14855)
GroupBy/resample/rolling#
.groupby(..).resample()のバグで、on=kwarg を渡した場合に問題が発生していました。 (GH 15021)Groupby.*関数に対して__name__および__qualname__が適切に設定されるようになりました (GH 14620)カテゴリカルグルーパで
GroupBy.get_group()が失敗するバグ (GH 15155).groupby(...).rolling(...)のバグで、onが指定され、DatetimeIndexが使用されている場合に問題が発生していました (GH 15130, GH 13966)numeric_only=Falseを渡したときにtimedelta64を使用した groupby 操作のバグ (GH 5724)groupby.apply()のバグで、すべての値が数値でない場合でもobjectdtypes を数値型に強制変換していました (GH 14423, GH 15421, GH 15670)resampleのバグで、時系列をリサンプリングする際に非文字列のloffset引数が適用されなかった問題 (GH 13218)DataFrame.groupby().describe()のバグで、タプルを含むIndexでグループ化する際に問題が発生していました (GH 14848)groupby().nunique()のバグで、datetimelike グルーパを使用した場合にビンカウントが誤っていた問題 (GH 13453)groupby.transform()のバグで、結果の dtype を元の型に強制変換していました (GH 10972, GH 11444)groupby.agg()のバグで、datetimeのタイムゾーンを誤ってローカライズしていました (GH 15426, GH 10668, GH 13046).rolling/expanding()関数のバグで、count()がnp.Infをカウントせず、objectdtypes を処理していなかった問題 (GH 12541).rolling()のバグで、pd.Timedeltaまたはdatetime.timedeltaがwindow引数として受け入れられなかった問題 (GH 15440)Rolling.quantile関数のバグで、範囲 [0, 1] 外の分位値で呼び出されたときにセグメンテーション違反が発生していました (GH 15463)重複する列名が存在する場合の
DataFrame.resample().median()のバグ (GH 14233)
スパース#
再整形#
pd.merge_asof()のバグで、複数のbyが指定された場合にleft_indexまたはright_indexが失敗する問題 (GH 15676)pd.merge_asof()のバグで、toleranceが指定された場合にleft_indexとright_indexが同時に失敗する問題 (GH 15135)DataFrame.pivot_table()のバグで、dropna=Trueが、列がcategorydtype の場合にすべての NaN 列を削除しなかった問題 (GH 15193)pd.melt()のバグで、value_varsにタプル値を渡すとTypeErrorが発生しました (GH 15348)pd.pivot_table()のバグで、values 引数が列にない場合にエラーが発生しなかった問題 (GH 14938)pd.concat()のバグで、join='inner'で空のデータフレームと連結した場合に誤って処理されていた問題 (GH 15328)インデックス結合時に
DataFrame.joinおよびpd.mergeでsort=Trueのバグ (GH 15582)DataFrame.nsmallestとDataFrame.nlargestのバグで、同一の値が重複行を引き起こしていました (GH 15297)pandas.pivot_table()のバグで、marginsキーワードに Unicode 入力を渡すとUnicodeErrorが誤って発生していました (GH 13292)
数値#
.rank()のバグで、順序付きカテゴリが誤ってランク付けされていました (GH 15420).corr()と.cov()のバグで、列とインデックスが同じオブジェクトだった場合の問題 (GH 14617).mode()のバグで、単一の値しか存在しない場合でもmodeが返されなかった問題 (GH 15714)すべて 0 の配列で単一のビンを持つ
pd.cut()のバグ (GH 15428)単一の分位点と同一の値を持つ配列を持つ
pd.qcut()のバグ (GH 15431)pandas.tools.utils.cartesian_product()のバグで、大きな入力が Windows でオーバーフローを引き起こす可能性がありました (GH 15265).eval()のバグで、複数行の eval が最初の行にローカル変数がない場合に失敗していました (GH 15342)
その他#
貢献者#
このリリースには合計 204 名がパッチを貢献しました。名前の横に「+」が付いている方は、初めてパッチを貢献された方です。
Adam J. Stewart +
Adrian +
Ajay Saxena
Akash Tandon +
Albert Villanova del Moral +
Aleksey Bilogur +
Alexis Mignon +
Amol Kahat +
Andreas Winkler +
Andrew Kittredge +
Anthonios Partheniou
Arco Bast +
Ashish Singal +
Baurzhan Muftakhidinov +
Ben Kandel
Ben Thayer +
Ben Welsh +
Bill Chambers +
Brandon M. Burroughs
Brian +
Brian McFee +
Carlos Souza +
Chris
Chris Ham
Chris Warth
Christoph Gohlke
Christoph Paulik +
Christopher C. Aycock
Clemens Brunner +
D.S. McNeil +
DaanVanHauwermeiren +
Daniel Himmelstein
Dave Willmer
David Cook +
David Gwynne +
David Hoffman +
David Krych
Diego Fernandez +
Dimitris Spathis +
Dmitry L +
Dody Suria Wijaya +
Dominik Stanczak +
Dr-Irv
Dr. Irv +
Elliott Sales de Andrade +
Ennemoser Christoph +
Francesc Alted +
Fumito Hamamura +
Giacomo Ferroni
Graham R. Jeffries +
Greg Williams +
Guilherme Beltramini +
Guilherme Samora +
Hao Wu +
Harshit Patni +
Ilya V. Schurov +
Iván Vallés Pérez
Jackie Leng +
Jaehoon Hwang +
James Draper +
James Goppert +
James McBride +
James Santucci +
ヤン・シュルツ
Jeff Carey
ジェフ・リーバック
JennaVergeynst +
Jim +
Jim Crist
Joe Jevnik
Joel Nothman +
John +
John Tucker +
John W. O’Brien
John Zwinck
Jon M. Mease
Jon Mease
Jonathan Whitmore +
Jonathan de Bruin +
Joost Kranendonk +
Joris Van den Bossche
Joshua Bradt +
Julian Santander
Julien Marrec +
Jun Kim +
Justin Solinsky +
Kacawi +
Kamal Kamalaldin +
カービー・シェデン
Kernc
Keshav Ramaswamy
ケビン・シェパード
Kyle Kelley
Larry Ren
Leon Yin +
Line Pedersen +
Lorenzo Cestaro +
Luca Scarabello
Lukasz +
Mahmoud Lababidi
Mark Mandel +
Matt Roeschke
Matthew Brett
Matthew Roeschke +
Matti Picus
Maximilian Roos
Michael Charlton +
Michael Felt
Michael Lamparski +
Michiel Stock +
Mikolaj Chwalisz +
Min RK
Miroslav Šedivý +
Mykola Golubyev
Nate Yoder
Nathalie Rud +
Nicholas Ver Halen
Nick Chmura +
Nolan Nichols +
Pankaj Pandey +
Pawel Kordek
Pete Huang +
Peter +
Peter Csizsek +
Petio Petrov +
Phil Ruffwind +
ピエトロ・バティストン
Piotr Chromiec
Prasanjit Prakash +
Rob Forgione +
Robert Bradshaw
Robin +
Rodolfo Fernandez
ロジャー・トーマス
Rouz Azari +
Sahil Dua
Sam Foo +
Sami Salonen +
Sarah Bird +
Sarma Tangirala +
Scott Sanderson
Sebastian Bank
Sebastian Gsänger +
Shawn Heide
Shyam Saladi +
Sinhrks
Stephen Rauch +
Sébastien de Menten +
Tara Adiseshan
Thiago Serafim
Thoralf Gutierrez +
Thrasibule +
Tobias Gustafsson +
Tom Augspurger
Tong SHEN +
Tong Shen +
TrigonaMinima +
Uwe +
ウェス・ターナー
Wiktor Tomczak +
WillAyd
ヤロスラフ・ハルチェンコ
Yimeng Zhang +
abaldenko +
adrian-stepien +
alexandercbooth +
atbd +
bastewart +
bmagnusson +
carlosdanielcsantos +
chaimdemulder +
クリス・B1
dickreuter +
discort +
dr-leo +
dubourg
dwkenefick +
funnycrab +
ジーエフヤング
goldenbull +
hesham.shabana@hotmail.com
jojomdt +
linebp +
manu +
manuels +
mattip +
maxalbert +
mcocdawc +
nuffe +
paul-mannino
pbreach +
sakkemo +
scls19fr
sinhrks
stijnvanhoey +
the-nose-knows +
themrmax +
tomrod +
tzinckgraf
wandersoncferreira
watercrossing +
wcwagner
xgdgsc +
yui-knk