欠損データの処理#
「欠損」と見なされる値#
pandas は、データ型に応じて、欠損値 (NA とも呼ばれる) を表すために異なる番兵値を使用します。
NumPy データ型の場合はnumpy.nan。NumPy データ型を使用する欠点は、元のデータ型がnp.float64またはobjectに強制されることです。
In [1]: pd.Series([1, 2], dtype=np.int64).reindex([0, 1, 2])
Out[1]:
0 1.0
1 2.0
2 NaN
dtype: float64
In [2]: pd.Series([True, False], dtype=np.bool_).reindex([0, 1, 2])
Out[2]:
0 True
1 False
2 NaN
dtype: object
NumPy のnp.datetime64、np.timedelta64、およびPeriodDtype の場合はNaT。型付けアプリケーションにはapi.types.NaTTypeを使用します。
In [3]: pd.Series([1, 2], dtype=np.dtype("timedelta64[ns]")).reindex([0, 1, 2])
Out[3]:
0 0 days 00:00:00.000000001
1 0 days 00:00:00.000000002
2 NaT
dtype: timedelta64[ns]
In [4]: pd.Series([1, 2], dtype=np.dtype("datetime64[ns]")).reindex([0, 1, 2])
Out[4]:
0 1970-01-01 00:00:00.000000001
1 1970-01-01 00:00:00.000000002
2 NaT
dtype: datetime64[ns]
In [5]: pd.Series(["2020", "2020"], dtype=pd.PeriodDtype("D")).reindex([0, 1, 2])
Out[5]:
0 2020-01-01
1 2020-01-01
2 NaT
dtype: period[D]
StringDtype、Int64Dtype (およびその他のビット幅)、Float64Dtype`(および その他の ビット 幅)、 :class:`BooleanDtype、およびArrowDtype の場合はNA。これらの型はデータの元のデータ型を維持します。型付けアプリケーションにはapi.types.NATypeを使用します。
In [6]: pd.Series([1, 2], dtype="Int64").reindex([0, 1, 2])
Out[6]:
0 1
1 2
2 <NA>
dtype: Int64
In [7]: pd.Series([True, False], dtype="boolean[pyarrow]").reindex([0, 1, 2])
Out[7]:
0 True
1 False
2 <NA>
dtype: bool[pyarrow]
これらの欠損値を検出するには、isna() または notna() メソッドを使用します。
In [8]: ser = pd.Series([pd.Timestamp("2020-01-01"), pd.NaT])
In [9]: ser
Out[9]:
0 2020-01-01
1 NaT
dtype: datetime64[ns]
In [10]: pd.isna(ser)
Out[10]:
0 False
1 True
dtype: bool
注
isna() または notna() は、None も欠損値と見なします。
In [11]: ser = pd.Series([1, None], dtype=object)
In [12]: ser
Out[12]:
0 1
1 None
dtype: object
In [13]: pd.isna(ser)
Out[13]:
0 False
1 True
dtype: bool
警告
np.nan、NaT、および NA の間の等価比較は None のようには動作しません。
In [14]: None == None # noqa: E711
Out[14]: True
In [15]: np.nan == np.nan
Out[15]: False
In [16]: pd.NaT == pd.NaT
Out[16]: False
In [17]: pd.NA == pd.NA
Out[17]: <NA>
したがって、これらの欠損値を持つ DataFrame または Series の間の等価比較は、isna() または notna() と同じ情報を提供しません。
In [18]: ser = pd.Series([True, None], dtype="boolean[pyarrow]")
In [19]: ser == pd.NA
Out[19]:
0 <NA>
1 <NA>
dtype: bool[pyarrow]
In [20]: pd.isna(ser)
Out[20]:
0 False
1 True
dtype: bool
NA セマンティクス#
警告
実験的: NA` の動作は予告なく変更される可能性があります。
pandas 1.0 以降、スカラー欠損値を表すための実験的な NA 値 (シングルトン) が利用可能です。NA の目的は、データ型に関係なく (データ型に応じて np.nan、None、または pd.NaT ではなく) データ型間で一貫して使用できる「欠損」インジケータを提供することです。
例えば、null 許容整数 dtype の Series に欠損値がある場合、それは NA を使用します。
In [21]: s = pd.Series([1, 2, None], dtype="Int64")
In [22]: s
Out[22]:
0 1
1 2
2 <NA>
dtype: Int64
In [23]: s[2]
Out[23]: <NA>
In [24]: s[2] is pd.NA
Out[24]: True
現在、pandas はデフォルトでは NA を使用するデータ型を DataFrame または Series に使用しないため、dtype を明示的に指定する必要があります。これらの dtype に変換する簡単な方法は、変換セクションで説明されています。
算術演算および比較演算における伝播#
一般に、NA を含む演算では、欠損値は 伝播します。オペランドのいずれかが不明な場合、演算の結果も不明です。
例えば、NA は np.nan と同様に算術演算で伝播します。
In [25]: pd.NA + 1
Out[25]: <NA>
In [26]: "a" * pd.NA
Out[26]: <NA>
オペランドの1つがNAであっても、結果が既知であるいくつかの特殊なケースがあります。
In [27]: pd.NA ** 0
Out[27]: 1
In [28]: 1 ** pd.NA
Out[28]: 1
等価演算と比較演算においても、NA は伝播します。これは np.nan の動作とは異なり、np.nan との比較は常に False を返します。
In [29]: pd.NA == 1
Out[29]: <NA>
In [30]: pd.NA == pd.NA
Out[30]: <NA>
In [31]: pd.NA < 2.5
Out[31]: <NA>
値が NA と等しいかどうかを確認するには、isna() を使用します。
In [32]: pd.isna(pd.NA)
Out[32]: True
注
この基本的な伝播ルールの例外は、pandas がデフォルトで欠損値をスキップする 削減 (平均や最小値など) です。詳細については、計算セクションを参照してください。
論理演算#
論理演算では、NA は 三値論理 (または R、SQL、Julia と同様に Kleene 論理) のルールに従います。この論理は、論理的に必要な場合にのみ欠損値を伝播することを意味します。
例えば、論理「OR」演算 (|) の場合、オペランドのいずれかが True であれば、他の値に関係なく (欠損値が True であろうと False であろうと)、結果は True になることがすでに分かっています。この場合、NA は伝播しません。
In [33]: True | False
Out[33]: True
In [34]: True | pd.NA
Out[34]: True
In [35]: pd.NA | True
Out[35]: True
一方、オペランドのいずれかが False の場合、結果はもう一方のオペランドの値に依存します。したがって、この場合 NA は伝播します。
In [36]: False | True
Out[36]: True
In [37]: False | False
Out[37]: False
In [38]: False | pd.NA
Out[38]: <NA>
論理「AND」演算 (&) の動作も同様の論理で導き出すことができます (この場合、オペランドのいずれかが既に False であれば NA は伝播しません)。
In [39]: False & True
Out[39]: False
In [40]: False & False
Out[40]: False
In [41]: False & pd.NA
Out[41]: False
In [42]: True & True
Out[42]: True
In [43]: True & False
Out[43]: False
In [44]: True & pd.NA
Out[44]: <NA>
ブールコンテキストでの NA#
NA の実際の値は不明であるため、NA をブール値に変換することは曖昧です。
In [45]: bool(pd.NA)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[45], line 1
----> 1 bool(pd.NA)
File ~/work/pandas/pandas/pandas/_libs/missing.pyx:392, in pandas._libs.missing.NAType.__bool__()
TypeError: boolean value of NA is ambiguous
これはまた、NA をブール値として評価されるコンテキスト (例: if condition: ... で condition が NA になる可能性がある場合) では使用できないことを意味します。このような場合、isna() を使用して NA をチェックするか、事前に欠損値を埋めるなどして condition が NA になることを避けることができます。
if ステートメントで Series または DataFrame オブジェクトを使用する場合にも同様の状況が発生します。pandas で if/真偽ステートメントを使用するを参照してください。
NumPy ufuncs#
pandas.NA は NumPy の __array_ufunc__ プロトコルを実装しています。ほとんどの ufunc は NA と連携し、一般的に NA を返します。
In [46]: np.log(pd.NA)
Out[46]: <NA>
In [47]: np.add(pd.NA, 1)
Out[47]: <NA>
警告
現在、ndarrayとNAを含むufuncは、NA値で埋められたオブジェクトdtypeを返します。
In [48]: a = np.array([1, 2, 3])
In [49]: np.greater(a, pd.NA)
Out[49]: array([<NA>, <NA>, <NA>], dtype=object)
ここでの戻り値の型は、将来的に異なる配列型を返すように変更される可能性があります。
ufuncs の詳細については、NumPy 関数との DataFrame 相互運用性を参照してください。
変換#
np.nan を使用する DataFrame または Series がある場合、Series.convert_dtypes() と DataFrame.convert_dtypes() は、NA を使用するデータ型 (例: Int64Dtype または ArrowDtype) にデータを変換できます。これは、IO メソッドからデータセットを読み込んだ後、データ型が推論された場合に特に役立ちます。
この例では、すべての列の dtype が変更されますが、最初の 10 列の結果を示します。
In [50]: import io
In [51]: data = io.StringIO("a,b\n,True\n2,")
In [52]: df = pd.read_csv(data)
In [53]: df.dtypes
Out[53]:
a float64
b object
dtype: object
In [54]: df_conv = df.convert_dtypes()
In [55]: df_conv
Out[55]:
a b
0 <NA> True
1 2 <NA>
In [56]: df_conv.dtypes
Out[56]:
a Int64
b boolean
dtype: object
欠損データの挿入#
Series または DataFrame に単に値を代入することで、欠損値を挿入できます。使用される欠損値番兵は dtype に基づいて選択されます。
In [57]: ser = pd.Series([1., 2., 3.])
In [58]: ser.loc[0] = None
In [59]: ser
Out[59]:
0 NaN
1 2.0
2 3.0
dtype: float64
In [60]: ser = pd.Series([pd.Timestamp("2021"), pd.Timestamp("2021")])
In [61]: ser.iloc[0] = np.nan
In [62]: ser
Out[62]:
0 NaT
1 2021-01-01
dtype: datetime64[ns]
In [63]: ser = pd.Series([True, False], dtype="boolean[pyarrow]")
In [64]: ser.iloc[0] = None
In [65]: ser
Out[65]:
0 <NA>
1 False
dtype: bool[pyarrow]
object型の場合、pandasは与えられた値を使用します。
In [66]: s = pd.Series(["a", "b", "c"], dtype=object)
In [67]: s.loc[0] = None
In [68]: s.loc[1] = np.nan
In [69]: s
Out[69]:
0 None
1 NaN
2 c
dtype: object
欠損データを含む計算#
欠損値は、pandas オブジェクト間の算術演算を通じて伝播します。
In [70]: ser1 = pd.Series([np.nan, np.nan, 2, 3])
In [71]: ser2 = pd.Series([np.nan, 1, np.nan, 4])
In [72]: ser1
Out[72]:
0 NaN
1 NaN
2 2.0
3 3.0
dtype: float64
In [73]: ser2
Out[73]:
0 NaN
1 1.0
2 NaN
3 4.0
dtype: float64
In [74]: ser1 + ser2
Out[74]:
0 NaN
1 NaN
2 NaN
3 7.0
dtype: float64
データ構造の概要で説明されている (そしてこちらとこちらにリストされている) 記述統計および計算メソッドはすべて、欠損データを考慮しています。
データを合計する場合、NA値または空のデータはゼロとして扱われます。
In [75]: pd.Series([np.nan]).sum()
Out[75]: 0.0
In [76]: pd.Series([], dtype="float64").sum()
Out[76]: 0.0
積を計算する場合、NA値または空のデータは1として扱われます。
In [77]: pd.Series([np.nan]).prod()
Out[77]: 1.0
In [78]: pd.Series([], dtype="float64").prod()
Out[78]: 1.0
cumsum() や cumprod() のような累積メソッドは、デフォルトで NA 値を無視し、結果にそれらを保持します。この動作は skipna で変更できます。
cumsum()やcumprod()のような累積メソッドは、デフォルトでは NA 値を無視しますが、結果の配列ではそれらを保持します。この動作を上書きして NA 値を含めるには、skipna=Falseを使用します。
In [79]: ser = pd.Series([1, np.nan, 3, np.nan])
In [80]: ser
Out[80]:
0 1.0
1 NaN
2 3.0
3 NaN
dtype: float64
In [81]: ser.cumsum()
Out[81]:
0 1.0
1 NaN
2 4.0
3 NaN
dtype: float64
In [82]: ser.cumsum(skipna=False)
Out[82]:
0 1.0
1 NaN
2 NaN
3 NaN
dtype: float64
欠損データの削除#
dropna() は、欠損データのある行または列を削除します。
In [83]: df = pd.DataFrame([[np.nan, 1, 2], [1, 2, np.nan], [1, 2, 3]])
In [84]: df
Out[84]:
0 1 2
0 NaN 1 2.0
1 1.0 2 NaN
2 1.0 2 3.0
In [85]: df.dropna()
Out[85]:
0 1 2
2 1.0 2 3.0
In [86]: df.dropna(axis=1)
Out[86]:
1
0 1
1 2
2 2
In [87]: ser = pd.Series([1, pd.NA], dtype="int64[pyarrow]")
In [88]: ser.dropna()
Out[88]:
0 1
dtype: int64[pyarrow]
欠損データの補完#
値による補完#
fillna() は NA 値を非 NA データで置き換えます。
NA をスカラー値で置換します。
In [89]: data = {"np": [1.0, np.nan, np.nan, 2], "arrow": pd.array([1.0, pd.NA, pd.NA, 2], dtype="float64[pyarrow]")}
In [90]: df = pd.DataFrame(data)
In [91]: df
Out[91]:
np arrow
0 1.0 1.0
1 NaN <NA>
2 NaN <NA>
3 2.0 2.0
In [92]: df.fillna(0)
Out[92]:
np arrow
0 1.0 1.0
1 0.0 0.0
2 0.0 0.0
3 2.0 2.0
前方または後方にギャップを埋める
In [93]: df.ffill()
Out[93]:
np arrow
0 1.0 1.0
1 1.0 1.0
2 1.0 1.0
3 2.0 2.0
In [94]: df.bfill()
Out[94]:
np arrow
0 1.0 1.0
1 2.0 2.0
2 2.0 2.0
3 2.0 2.0
埋めるNA値の数を制限する
In [95]: df.ffill(limit=1)
Out[95]:
np arrow
0 1.0 1.0
1 1.0 1.0
2 NaN <NA>
3 2.0 2.0
NA 値は、元のオブジェクトと埋められたオブジェクトの間でインデックスと列が揃っている Series または DataFrame の対応する値で置き換えることができます。
In [96]: dff = pd.DataFrame(np.arange(30, dtype=np.float64).reshape(10, 3), columns=list("ABC"))
In [97]: dff.iloc[3:5, 0] = np.nan
In [98]: dff.iloc[4:6, 1] = np.nan
In [99]: dff.iloc[5:8, 2] = np.nan
In [100]: dff
Out[100]:
A B C
0 0.0 1.0 2.0
1 3.0 4.0 5.0
2 6.0 7.0 8.0
3 NaN 10.0 11.0
4 NaN NaN 14.0
5 15.0 NaN NaN
6 18.0 19.0 NaN
7 21.0 22.0 NaN
8 24.0 25.0 26.0
9 27.0 28.0 29.0
In [101]: dff.fillna(dff.mean())
Out[101]:
A B C
0 0.00 1.0 2.000000
1 3.00 4.0 5.000000
2 6.00 7.0 8.000000
3 14.25 10.0 11.000000
4 14.25 14.5 14.000000
5 15.00 14.5 13.571429
6 18.00 19.0 13.571429
7 21.00 22.0 13.571429
8 24.00 25.0 26.000000
9 27.00 28.0 29.000000
注
DataFrame.where()もNA値を埋めるために使用できます。上記と同じ結果です。
In [102]: dff.where(pd.notna(dff), dff.mean(), axis="columns")
Out[102]:
A B C
0 0.00 1.0 2.000000
1 3.00 4.0 5.000000
2 6.00 7.0 8.000000
3 14.25 10.0 11.000000
4 14.25 14.5 14.000000
5 15.00 14.5 13.571429
6 18.00 19.0 13.571429
7 21.00 22.0 13.571429
8 24.00 25.0 26.000000
9 27.00 28.0 29.000000
補間#
DataFrame.interpolate() と Series.interpolate() は、様々な補間メソッドを使用して NA 値を補間します。
In [103]: df = pd.DataFrame(
.....: {
.....: "A": [1, 2.1, np.nan, 4.7, 5.6, 6.8],
.....: "B": [0.25, np.nan, np.nan, 4, 12.2, 14.4],
.....: }
.....: )
.....:
In [104]: df
Out[104]:
A B
0 1.0 0.25
1 2.1 NaN
2 NaN NaN
3 4.7 4.00
4 5.6 12.20
5 6.8 14.40
In [105]: df.interpolate()
Out[105]:
A B
0 1.0 0.25
1 2.1 1.50
2 3.4 2.75
3 4.7 4.00
4 5.6 12.20
5 6.8 14.40
In [106]: idx = pd.date_range("2020-01-01", periods=10, freq="D")
In [107]: data = np.random.default_rng(2).integers(0, 10, 10).astype(np.float64)
In [108]: ts = pd.Series(data, index=idx)
In [109]: ts.iloc[[1, 2, 5, 6, 9]] = np.nan
In [110]: ts
Out[110]:
2020-01-01 8.0
2020-01-02 NaN
2020-01-03 NaN
2020-01-04 2.0
2020-01-05 4.0
2020-01-06 NaN
2020-01-07 NaN
2020-01-08 0.0
2020-01-09 3.0
2020-01-10 NaN
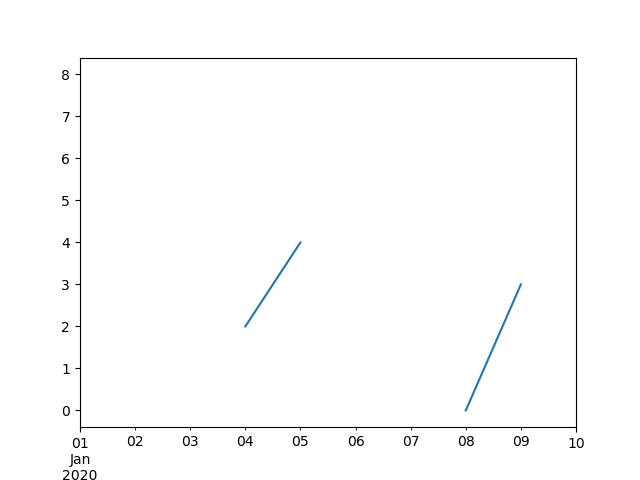
Freq: D, dtype: float64
In [111]: ts.plot()
Out[111]: <Axes: >
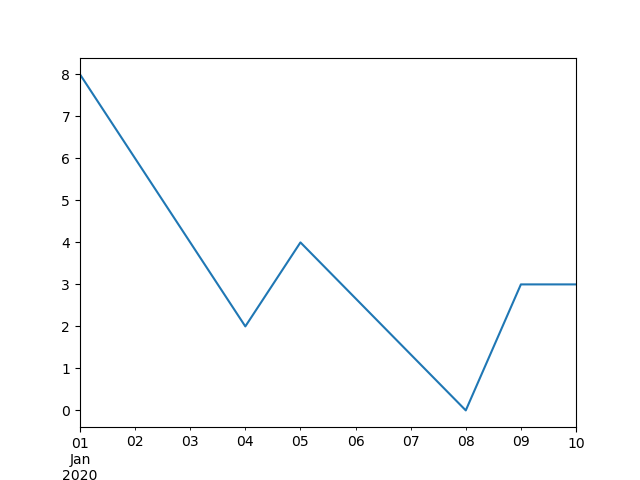
In [112]: ts.interpolate()
Out[112]:
2020-01-01 8.000000
2020-01-02 6.000000
2020-01-03 4.000000
2020-01-04 2.000000
2020-01-05 4.000000
2020-01-06 2.666667
2020-01-07 1.333333
2020-01-08 0.000000
2020-01-09 3.000000
2020-01-10 3.000000
Freq: D, dtype: float64
In [113]: ts.interpolate().plot()
Out[113]: <Axes: >
DatetimeIndex の Timestamp を基準とした補間は、method="time" を設定することで利用できます。
In [114]: ts2 = ts.iloc[[0, 1, 3, 7, 9]]
In [115]: ts2
Out[115]:
2020-01-01 8.0
2020-01-02 NaN
2020-01-04 2.0
2020-01-08 0.0
2020-01-10 NaN
dtype: float64
In [116]: ts2.interpolate()
Out[116]:
2020-01-01 8.0
2020-01-02 5.0
2020-01-04 2.0
2020-01-08 0.0
2020-01-10 0.0
dtype: float64
In [117]: ts2.interpolate(method="time")
Out[117]:
2020-01-01 8.0
2020-01-02 6.0
2020-01-04 2.0
2020-01-08 0.0
2020-01-10 0.0
dtype: float64
浮動小数点インデックスの場合、method='values' を使用します。
In [118]: idx = [0.0, 1.0, 10.0]
In [119]: ser = pd.Series([0.0, np.nan, 10.0], idx)
In [120]: ser
Out[120]:
0.0 0.0
1.0 NaN
10.0 10.0
dtype: float64
In [121]: ser.interpolate()
Out[121]:
0.0 0.0
1.0 5.0
10.0 10.0
dtype: float64
In [122]: ser.interpolate(method="values")
Out[122]:
0.0 0.0
1.0 1.0
10.0 10.0
dtype: float64
scipy がインストールされている場合、scipy 補間に関するドキュメントおよびリファレンスガイドで指定されているように、1 次元補間ルーチンの名前を method に渡すことができます。適切な補間方法はデータ型に依存します。
ヒント
増加率で成長している時系列を扱っている場合は、method='barycentric' を使用します。
累積分布関数に近似する値がある場合は、method='pchip' を使用します。
スムーズなプロットを目的として欠損値を埋める場合は、method='akima' を使用します。
In [123]: df = pd.DataFrame(
.....: {
.....: "A": [1, 2.1, np.nan, 4.7, 5.6, 6.8],
.....: "B": [0.25, np.nan, np.nan, 4, 12.2, 14.4],
.....: }
.....: )
.....:
In [124]: df
Out[124]:
A B
0 1.0 0.25
1 2.1 NaN
2 NaN NaN
3 4.7 4.00
4 5.6 12.20
5 6.8 14.40
In [125]: df.interpolate(method="barycentric")
Out[125]:
A B
0 1.00 0.250
1 2.10 -7.660
2 3.53 -4.515
3 4.70 4.000
4 5.60 12.200
5 6.80 14.400
In [126]: df.interpolate(method="pchip")
Out[126]:
A B
0 1.00000 0.250000
1 2.10000 0.672808
2 3.43454 1.928950
3 4.70000 4.000000
4 5.60000 12.200000
5 6.80000 14.400000
In [127]: df.interpolate(method="akima")
Out[127]:
A B
0 1.000000 0.250000
1 2.100000 -0.873316
2 3.406667 0.320034
3 4.700000 4.000000
4 5.600000 12.200000
5 6.800000 14.400000
多項式またはスプライン近似による補間を行う場合、近似の次数または階数を指定する必要があります。
In [128]: df.interpolate(method="spline", order=2)
Out[128]:
A B
0 1.000000 0.250000
1 2.100000 -0.428598
2 3.404545 1.206900
3 4.700000 4.000000
4 5.600000 12.200000
5 6.800000 14.400000
In [129]: df.interpolate(method="polynomial", order=2)
Out[129]:
A B
0 1.000000 0.250000
1 2.100000 -2.703846
2 3.451351 -1.453846
3 4.700000 4.000000
4 5.600000 12.200000
5 6.800000 14.400000
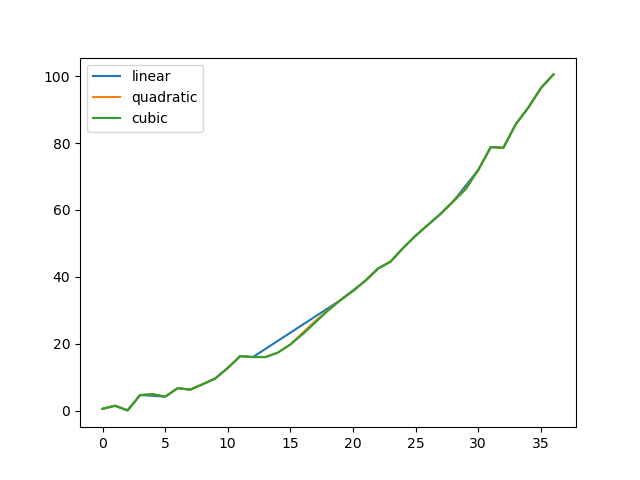
いくつかの方法を比較しています。
In [130]: np.random.seed(2)
In [131]: ser = pd.Series(np.arange(1, 10.1, 0.25) ** 2 + np.random.randn(37))
In [132]: missing = np.array([4, 13, 14, 15, 16, 17, 18, 20, 29])
In [133]: ser.iloc[missing] = np.nan
In [134]: methods = ["linear", "quadratic", "cubic"]
In [135]: df = pd.DataFrame({m: ser.interpolate(method=m) for m in methods})
In [136]: df.plot()
Out[136]: <Axes: >
Series.reindex() を用いた、拡張データからの新規観測値の補間。
In [137]: ser = pd.Series(np.sort(np.random.uniform(size=100)))
# interpolate at new_index
In [138]: new_index = ser.index.union(pd.Index([49.25, 49.5, 49.75, 50.25, 50.5, 50.75]))
In [139]: interp_s = ser.reindex(new_index).interpolate(method="pchip")
In [140]: interp_s.loc[49:51]
Out[140]:
49.00 0.471410
49.25 0.476841
49.50 0.481780
49.75 0.485998
50.00 0.489266
50.25 0.491814
50.50 0.493995
50.75 0.495763
51.00 0.497074
dtype: float64
補間制限#
interpolate() は、前回の有効な観測値以降に埋める連続する NaN 値の数を制限する limit キーワード引数を受け入れます。
In [141]: ser = pd.Series([np.nan, np.nan, 5, np.nan, np.nan, np.nan, 13, np.nan, np.nan])
In [142]: ser
Out[142]:
0 NaN
1 NaN
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 NaN
8 NaN
dtype: float64
In [143]: ser.interpolate()
Out[143]:
0 NaN
1 NaN
2 5.0
3 7.0
4 9.0
5 11.0
6 13.0
7 13.0
8 13.0
dtype: float64
In [144]: ser.interpolate(limit=1)
Out[144]:
0 NaN
1 NaN
2 5.0
3 7.0
4 NaN
5 NaN
6 13.0
7 13.0
8 NaN
dtype: float64
デフォルトでは、NaN 値は forward 方向に埋められます。limit_direction パラメータを使用して、backward または both の方向から埋めることができます。
In [145]: ser.interpolate(limit=1, limit_direction="backward")
Out[145]:
0 NaN
1 5.0
2 5.0
3 NaN
4 NaN
5 11.0
6 13.0
7 NaN
8 NaN
dtype: float64
In [146]: ser.interpolate(limit=1, limit_direction="both")
Out[146]:
0 NaN
1 5.0
2 5.0
3 7.0
4 NaN
5 11.0
6 13.0
7 13.0
8 NaN
dtype: float64
In [147]: ser.interpolate(limit_direction="both")
Out[147]:
0 5.0
1 5.0
2 5.0
3 7.0
4 9.0
5 11.0
6 13.0
7 13.0
8 13.0
dtype: float64
デフォルトでは、NaN 値は既存の有効な値に囲まれているか、既存の有効な値の外側にあるかに関わらず埋められます。limit_area パラメータは、埋め込みを内側または外側の値に制限します。
# fill one consecutive inside value in both directions
In [148]: ser.interpolate(limit_direction="both", limit_area="inside", limit=1)
Out[148]:
0 NaN
1 NaN
2 5.0
3 7.0
4 NaN
5 11.0
6 13.0
7 NaN
8 NaN
dtype: float64
# fill all consecutive outside values backward
In [149]: ser.interpolate(limit_direction="backward", limit_area="outside")
Out[149]:
0 5.0
1 5.0
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 NaN
8 NaN
dtype: float64
# fill all consecutive outside values in both directions
In [150]: ser.interpolate(limit_direction="both", limit_area="outside")
Out[150]:
0 5.0
1 5.0
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 13.0
8 13.0
dtype: float64
値の置換#
Series.replace() および DataFrame.replace() は、Series.fillna() および DataFrame.fillna() と同様に、欠損値を置き換えたり挿入したりするために使用できます。
In [151]: df = pd.DataFrame(np.eye(3))
In [152]: df
Out[152]:
0 1 2
0 1.0 0.0 0.0
1 0.0 1.0 0.0
2 0.0 0.0 1.0
In [153]: df_missing = df.replace(0, np.nan)
In [154]: df_missing
Out[154]:
0 1 2
0 1.0 NaN NaN
1 NaN 1.0 NaN
2 NaN NaN 1.0
In [155]: df_filled = df_missing.replace(np.nan, 2)
In [156]: df_filled
Out[156]:
0 1 2
0 1.0 2.0 2.0
1 2.0 1.0 2.0
2 2.0 2.0 1.0
リストを渡すことで、複数の値を置き換えることができます。
In [157]: df_filled.replace([1, 44], [2, 28])
Out[157]:
0 1 2
0 2.0 2.0 2.0
1 2.0 2.0 2.0
2 2.0 2.0 2.0
マッピング辞書を使用して置換します。
In [158]: df_filled.replace({1: 44, 2: 28})
Out[158]:
0 1 2
0 44.0 28.0 28.0
1 28.0 44.0 28.0
2 28.0 28.0 44.0
正規表現による置換#
注
r 文字をプレフィックスとする Python 文字列 (例: r'hello world') は、「生文字列」です。これらは、このプレフィックスのない文字列とはバックスラッシュに関するセマンティクスが異なります。生文字列内のバックスラッシュはエスケープされたバックスラッシュとして解釈されます (例: r'\' == '\\')。
「.」を NaN に置き換えます。
In [159]: d = {"a": list(range(4)), "b": list("ab.."), "c": ["a", "b", np.nan, "d"]}
In [160]: df = pd.DataFrame(d)
In [161]: df.replace(".", np.nan)
Out[161]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
周囲の空白を削除する正規表現で「.」をNaNに置き換えます
In [162]: df.replace(r"\s*\.\s*", np.nan, regex=True)
Out[162]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
正規表現のリストで置換します。
In [163]: df.replace([r"\.", r"(a)"], ["dot", r"\1stuff"], regex=True)
Out[163]:
a b c
0 0 astuff astuff
1 1 b b
2 2 dot NaN
3 3 dot d
マッピング辞書内の正規表現で置き換えます。
In [164]: df.replace({"b": r"\s*\.\s*"}, {"b": np.nan}, regex=True)
Out[164]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
regex キーワードを使用する正規表現のネストされた辞書を渡します。
In [165]: df.replace({"b": {"b": r""}}, regex=True)
Out[165]:
a b c
0 0 a a
1 1 b
2 2 . NaN
3 3 . d
In [166]: df.replace(regex={"b": {r"\s*\.\s*": np.nan}})
Out[166]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
In [167]: df.replace({"b": r"\s*(\.)\s*"}, {"b": r"\1ty"}, regex=True)
Out[167]:
a b c
0 0 a a
1 1 b b
2 2 .ty NaN
3 3 .ty d
一致するものをスカラーで置き換える正規表現のリストを渡します。
In [168]: df.replace([r"\s*\.\s*", r"a|b"], "placeholder", regex=True)
Out[168]:
a b c
0 0 placeholder placeholder
1 1 placeholder placeholder
2 2 placeholder NaN
3 3 placeholder d
すべての正規表現の例は、to_replace 引数として regex 引数でも渡すことができます。この場合、value 引数は明示的に名前で渡すか、regex はネストされた辞書である必要があります。
In [169]: df.replace(regex=[r"\s*\.\s*", r"a|b"], value="placeholder")
Out[169]:
a b c
0 0 placeholder placeholder
1 1 placeholder placeholder
2 2 placeholder NaN
3 3 placeholder d
注
re.compile からの正規表現オブジェクトも有効な入力です。