バージョン 0.16.0 (2015年3月22日)#
これは 0.15.2 からのメジャーリリースであり、少数のAPI変更、いくつかの新機能、機能強化、パフォーマンス改善に加え、多数のバグ修正が含まれています。すべてのユーザーにこのバージョンへのアップグレードをお勧めします。
主な機能は以下の通りです。
DataFrame.assignメソッド、詳細はこちらを参照scipy.sparseと連携するためのSeries.to_coo/from_cooメソッド、詳細はこちらを参照Timedeltaの.seconds属性をdatetime.timedeltaに合わせるための後方互換性のない変更、詳細はこちらを参照.locスライシングAPIの変更は、.ixの動作に合わせるため、詳細はこちらを参照Categoricalコンストラクタにおける順序のデフォルト値の変更、詳細はこちらを参照文字列操作を容易にするための
.strアクセサの機能強化、詳細はこちらを参照pandas.tools.rplot、pandas.sandbox.qtpandas、およびpandas.rpyモジュールは非推奨になりました。類似または同等の機能については、seaborn、pandas-qt、rpy2などの外部パッケージを参照してください。詳細はこちら。
新機能#
DataFrame assign#
dplyrのmutate動詞に触発され、DataFrameに新しいassign()メソッドが追加されました。assignの関数シグネチャは単に**kwargsです。キーは新しいフィールドの列名で、値は挿入される値(例えばSeriesまたはNumPy配列)か、DataFrameに対して呼び出される1つの引数を持つ関数です。新しい値が挿入され、DataFrame全体(すべての元の列と新しい列を含む)が返されます。
In [1]: iris = pd.read_csv('data/iris.data')
In [2]: iris.head()
Out[2]:
SepalLength SepalWidth PetalLength PetalWidth Name
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
[5 rows x 5 columns]
In [3]: iris.assign(sepal_ratio=iris['SepalWidth'] / iris['SepalLength']).head()
Out[3]:
SepalLength SepalWidth PetalLength PetalWidth Name sepal_ratio
0 5.1 3.5 1.4 0.2 Iris-setosa 0.686275
1 4.9 3.0 1.4 0.2 Iris-setosa 0.612245
2 4.7 3.2 1.3 0.2 Iris-setosa 0.680851
3 4.6 3.1 1.5 0.2 Iris-setosa 0.673913
4 5.0 3.6 1.4 0.2 Iris-setosa 0.720000
[5 rows x 6 columns]
上記は、事前に計算された値を挿入する例でした。関数を渡して評価することもできます。
In [4]: iris.assign(sepal_ratio=lambda x: (x['SepalWidth']
...: / x['SepalLength'])).head()
...:
Out[4]:
SepalLength SepalWidth PetalLength PetalWidth Name sepal_ratio
0 5.1 3.5 1.4 0.2 Iris-setosa 0.686275
1 4.9 3.0 1.4 0.2 Iris-setosa 0.612245
2 4.7 3.2 1.3 0.2 Iris-setosa 0.680851
3 4.6 3.1 1.5 0.2 Iris-setosa 0.673913
4 5.0 3.6 1.4 0.2 Iris-setosa 0.720000
[5 rows x 6 columns]
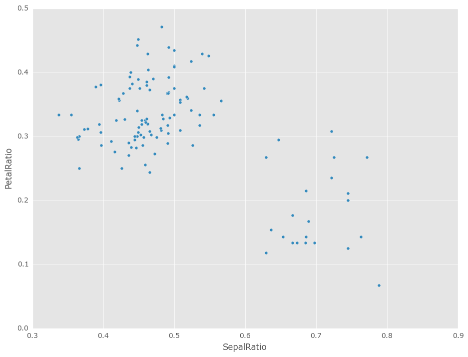
assignの威力は、一連の操作で連鎖的に使用されるときに発揮されます。例えば、DataFrameをSepal Lengthが5より大きいものに限定し、比率を計算してプロットすることができます。
In [5]: iris = pd.read_csv('data/iris.data')
In [6]: (iris.query('SepalLength > 5')
...: .assign(SepalRatio=lambda x: x.SepalWidth / x.SepalLength,
...: PetalRatio=lambda x: x.PetalWidth / x.PetalLength)
...: .plot(kind='scatter', x='SepalRatio', y='PetalRatio'))
...:
Out[6]: <Axes: xlabel='SepalRatio', ylabel='PetalRatio'>
scipy.sparseとの連携#
scipy.sparse.coo_matrixインスタンスとの間で変換するためのSparseSeries.to_coo()とSparseSeries.from_coo()メソッドが追加されました(GH 8048)(こちらを参照)。例えば、MultiIndexを持つSparseSeriesが与えられた場合、行と列のラベルをインデックスレベルとして指定することで、scipy.sparse.coo_matrixに変換できます。
s = pd.Series([3.0, np.nan, 1.0, 3.0, np.nan, np.nan])
s.index = pd.MultiIndex.from_tuples([(1, 2, 'a', 0),
(1, 2, 'a', 1),
(1, 1, 'b', 0),
(1, 1, 'b', 1),
(2, 1, 'b', 0),
(2, 1, 'b', 1)],
names=['A', 'B', 'C', 'D'])
s
# SparseSeries
ss = s.to_sparse()
ss
A, rows, columns = ss.to_coo(row_levels=['A', 'B'],
column_levels=['C', 'D'],
sort_labels=False)
A
A.todense()
rows
columns
from_cooメソッドは、scipy.sparse.coo_matrixからSparseSeriesを作成するための便利なメソッドです。
from scipy import sparse
A = sparse.coo_matrix(([3.0, 1.0, 2.0], ([1, 0, 0], [0, 2, 3])),
shape=(3, 4))
A
A.todense()
ss = pd.SparseSeries.from_coo(A)
ss
文字列メソッドの機能強化#
以下の新しいメソッドは、
.strアクセサを介してアクセスでき、関数を各値に適用します。これは、文字列の標準メソッドとの一貫性を高めることを意図しています。(GH 9282, GH 9352, GH 9386, GH 9387, GH 9439)メソッド
isalnum()isalpha()isdigit()isdigit()isspace()islower()isupper()istitle()isnumeric()isdecimal()find()rfind()ljust()rjust()zfill()In [7]: s = pd.Series(['abcd', '3456', 'EFGH']) In [8]: s.str.isalpha() Out[8]: 0 True 1 False 2 True Length: 3, dtype: bool In [9]: s.str.find('ab') Out[9]: 0 0 1 -1 2 -1 Length: 3, dtype: int64
Series.str.pad()およびSeries.str.center()は、埋め込み文字を指定するためのfillcharオプションを受け入れるようになりました (GH 9352)In [10]: s = pd.Series(['12', '300', '25']) In [11]: s.str.pad(5, fillchar='_') Out[11]: 0 ___12 1 __300 2 ___25 Length: 3, dtype: object
以前は
NotImplementedErrorを発生させていたSeries.str.slice_replace()が追加されました(GH 8888)In [12]: s = pd.Series(['ABCD', 'EFGH', 'IJK']) In [13]: s.str.slice_replace(1, 3, 'X') Out[13]: 0 AXD 1 EXH 2 IX Length: 3, dtype: object # replaced with empty char In [14]: s.str.slice_replace(0, 1) Out[14]: 0 BCD 1 FGH 2 JK Length: 3, dtype: object
その他の機能強化#
Reindexは、単調増加または減少するインデックスを持つフレームまたはシリーズに対して
method='nearest'をサポートするようになりました(GH 9258)。In [15]: df = pd.DataFrame({'x': range(5)}) In [16]: df.reindex([0.2, 1.8, 3.5], method='nearest') Out[16]: x 0.2 0 1.8 2 3.5 4 [3 rows x 1 columns]
このメソッドは、下位レベルの
Index.get_indexerおよびIndex.get_locメソッドによっても公開されています。read_excel()関数のsheetname引数は、複数のシートまたはすべてのシートを取得するためにそれぞれリストとNoneを受け入れるようになりました。複数のシートが指定された場合、辞書が返されます。(GH 9450)# Returns the 1st and 4th sheet, as a dictionary of DataFrames. pd.read_excel('path_to_file.xls', sheetname=['Sheet1', 3])
Stataファイルをイテレータでインクリメンタルに読み込めるようになりました。Stataファイルの長い文字列をサポートしています。ドキュメントはこちらを参照してください(GH 9493)。
~で始まるパスは、ユーザーのホームディレクトリで始まるように展開されるようになりました(GH 9066)。
get_data_yahooに時間間隔選択が追加されました (GH 9071)Timedelta.to_timedelta64()を補完するためにTimestamp.to_datetime64()が追加されました(GH 9255)。tseries.frequencies.to_offset()は入力としてTimedeltaを受け入れるようになりました(GH 9064)。Seriesの自己相関メソッドにラグパラメータが追加され、デフォルトはラグ-1自己相関です(GH 9192)。Timedeltaはコンストラクタでnanosecondsキーワードを受け入れるようになりました(GH 9273)。SQLコードはテーブル名と列名を安全にエスケープするようになりました(GH 8986)。
Series.str.<tab>、Series.dt.<tab>、Series.cat.<tab>のオートコンプリートが追加されました(GH 9322)。Index.get_indexerは、単調なターゲットだけでなく、任意のターゲット配列に対してもmethod='pad'とmethod='backfill'をサポートするようになりました。これらのメソッドは、単調減少インデックスと単調増加インデックスの両方で機能します (GH 9258)。Index.asofは、すべてのインデックス型で機能するようになりました (GH 9258)。io.read_excel()にverbose引数が追加され、デフォルトはFalseです。Trueに設定すると、解析時にシート名が表示されます。(GH 9450)Timestamp、DatetimeIndex、Period、PeriodIndex、およびSeries.dtにdays_in_month(互換性エイリアスdaysinmonth)プロパティが追加されました(GH 9572)。「.」以外の小数区切り文字の書式設定を提供するために、
to_csvにdecimalオプションが追加されました (GH 781)真夜中に正規化するための
Timestampのnormalizeオプションが追加されました(GH 8794)。HDF5ファイルと
rhdf5ライブラリを使用してDataFrameをRにインポートする例が追加されました。詳細についてはドキュメントを参照してください(GH 9636)。
下位互換性のない API の変更#
Timedeltaの変更点#
v0.15.0では、datetime.timedeltaのサブクラスである新しいスカラー型Timedeltaが導入されました。.secondsアクセサに関するAPI変更の通知がこちらで言及されました。意図としては、その単位に対する「自然な」値を与えるユーザーフレンドリーなアクセサセットを提供することでした。例えば、Timedelta('1 day, 10:11:12')があった場合、.secondsは12を返します。しかし、これはdatetime.timedeltaの定義と矛盾します。datetime.timedeltaは.secondsを10 * 3600 + 11 * 60 + 12 == 36672と定義しているためです。
そのため、v0.16.0では、datetime.timedeltaと一致するようにAPIを復元しています。さらに、コンポーネント値は引き続き.componentsアクセサを通じて利用できます。この変更は、.secondsと.microsecondsアクセサに影響し、.hours、.minutes、.millisecondsアクセサを削除します。これらの変更は、TimedeltaIndexとSeriesの.dtアクセサにも影響します。(GH 9185, GH 9139)
以前の動作
In [2]: t = pd.Timedelta('1 day, 10:11:12.100123')
In [3]: t.days
Out[3]: 1
In [4]: t.seconds
Out[4]: 12
In [5]: t.microseconds
Out[5]: 123
新しい動作
In [17]: t = pd.Timedelta('1 day, 10:11:12.100123')
In [18]: t.days
Out[18]: 1
In [19]: t.seconds
Out[19]: 36672
In [20]: t.microseconds
Out[20]: 100123
.componentsを使用すると、コンポーネント全体にアクセスできます。
In [21]: t.components
Out[21]: Components(days=1, hours=10, minutes=11, seconds=12, milliseconds=100, microseconds=123, nanoseconds=0)
In [22]: t.components.seconds
Out[22]: 12
インデックス変更#
.locを使用するエッジケースの小さなサブセットの動作が変更されました(GH 8613)。さらに、発生するエラーメッセージの内容が改善されました。
開始境界または停止境界がインデックスに見つからない場合の
.locによるスライシングが許可されるようになりました。以前はKeyErrorが発生していました。これにより、この場合の動作は.ixと同じになります。この変更はスライシングのみに適用され、単一のラベルでのインデックス指定には適用されません。In [23]: df = pd.DataFrame(np.random.randn(5, 4), ....: columns=list('ABCD'), ....: index=pd.date_range('20130101', periods=5)) ....: In [24]: df Out[24]: A B C D 2013-01-01 0.469112 -0.282863 -1.509059 -1.135632 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 2013-01-04 0.721555 -0.706771 -1.039575 0.271860 2013-01-05 -0.424972 0.567020 0.276232 -1.087401 [5 rows x 4 columns] In [25]: s = pd.Series(range(5), [-2, -1, 1, 2, 3]) In [26]: s Out[26]: -2 0 -1 1 1 2 2 3 3 4 Length: 5, dtype: int64
以前の動作
In [4]: df.loc['2013-01-02':'2013-01-10'] KeyError: 'stop bound [2013-01-10] is not in the [index]' In [6]: s.loc[-10:3] KeyError: 'start bound [-10] is not the [index]'
新しい動作
In [27]: df.loc['2013-01-02':'2013-01-10'] Out[27]: A B C D 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 2013-01-04 0.721555 -0.706771 -1.039575 0.271860 2013-01-05 -0.424972 0.567020 0.276232 -1.087401 [4 rows x 4 columns] In [28]: s.loc[-10:3] Out[28]: -2 0 -1 1 1 2 2 3 3 4 Length: 5, dtype: int64
.ixの場合、整数インデックスで浮動小数点数に似た値でのスライシングを許可します。以前は.locでのみ有効でした。以前の動作
In [8]: s.ix[-1.0:2] TypeError: the slice start value [-1.0] is not a proper indexer for this index type (Int64Index)
新しい動作
In [2]: s.ix[-1.0:2] Out[2]: -1 1 1 2 2 3 dtype: int64
.locを使用する際に、そのインデックスにとって無効な型でインデックスを付けると、役立つ例外を提供します。例えば、DatetimeIndex、PeriodIndex、またはTimedeltaIndex型のインデックスに対して、整数(または浮動小数点数)を使用しようとする場合です。以前の動作
In [4]: df.loc[2:3] KeyError: 'start bound [2] is not the [index]'
新しい動作
In [4]: df.loc[2:3] TypeError: Cannot do slice indexing on <class 'pandas.tseries.index.DatetimeIndex'> with <type 'int'> keys
カテゴリカル変更#
以前のバージョンでは、順序が指定されていない(つまり、orderedキーワードが渡されていない)Categoricalsは、デフォルトでordered Categoricalsとして扱われていました。今後は、CategoricalコンストラクタのorderedキーワードのデフォルトはFalseになります。順序は明示的に指定する必要があります。
さらに、以前はcat.ordered=Trueのように属性を設定するだけで、Categoricalのordered属性を変更する**ことができました**。これは現在非推奨であり、cat.as_ordered()またはcat.as_unordered()を使用する必要があります。これらはデフォルトで**新しい**オブジェクトを返し、既存のオブジェクトは変更しません。(GH 9347, GH 9190)
以前の動作
In [3]: s = pd.Series([0, 1, 2], dtype='category')
In [4]: s
Out[4]:
0 0
1 1
2 2
dtype: category
Categories (3, int64): [0 < 1 < 2]
In [5]: s.cat.ordered
Out[5]: True
In [6]: s.cat.ordered = False
In [7]: s
Out[7]:
0 0
1 1
2 2
dtype: category
Categories (3, int64): [0, 1, 2]
新しい動作
In [29]: s = pd.Series([0, 1, 2], dtype='category')
In [30]: s
Out[30]:
0 0
1 1
2 2
Length: 3, dtype: category
Categories (3, int64): [0, 1, 2]
In [31]: s.cat.ordered
Out[31]: False
In [32]: s = s.cat.as_ordered()
In [33]: s
Out[33]:
0 0
1 1
2 2
Length: 3, dtype: category
Categories (3, int64): [0 < 1 < 2]
In [34]: s.cat.ordered
Out[34]: True
# you can set in the constructor of the Categorical
In [35]: s = pd.Series(pd.Categorical([0, 1, 2], ordered=True))
In [36]: s
Out[36]:
0 0
1 1
2 2
Length: 3, dtype: category
Categories (3, int64): [0 < 1 < 2]
In [37]: s.cat.ordered
Out[37]: True
カテゴリカルデータのシリーズを簡単に作成するために、.astype()を呼び出す際にキーワードを渡せるようになりました。これらは直接コンストラクタに渡されます。
In [54]: s = pd.Series(["a", "b", "c", "a"]).astype('category', ordered=True)
In [55]: s
Out[55]:
0 a
1 b
2 c
3 a
dtype: category
Categories (3, object): [a < b < c]
In [56]: s = (pd.Series(["a", "b", "c", "a"])
....: .astype('category', categories=list('abcdef'), ordered=False))
In [57]: s
Out[57]:
0 a
1 b
2 c
3 a
dtype: category
Categories (6, object): [a, b, c, d, e, f]
その他の API の変更#
Index.duplicatedは、bool値を含むIndex(dtype=object)ではなく、np.array(dtype=bool)を返すようになりました。(GH 8875)DataFrame.to_jsonは、混合dtypeのフレームの場合、各列に対して正確な型シリアライゼーションを返すようになりました (GH 9037)以前は、データはシリアライゼーション前に共通のdtypeに強制され、例えば整数が浮動小数点数にシリアライズされていました。
In [2]: pd.DataFrame({'i': [1,2], 'f': [3.0, 4.2]}).to_json() Out[2]: '{"f":{"0":3.0,"1":4.2},"i":{"0":1.0,"1":2.0}}'
各列は正しいdtypeを使用してシリアライズされます。
In [2]: pd.DataFrame({'i': [1,2], 'f': [3.0, 4.2]}).to_json() Out[2]: '{"f":{"0":3.0,"1":4.2},"i":{"0":1,"1":2}}'
DatetimeIndex、PeriodIndex、およびTimedeltaIndex.summaryは、同じ形式で出力されるようになりました。(GH 9116)TimedeltaIndex.freqstrは、DatetimeIndexと同じ文字列形式を出力するようになりました (GH 9116)。棒グラフおよび横棒グラフは、情報軸に沿った点線を付け加えなくなりました。以前のスタイルは、matplotlibの
axhlineまたはaxvlineメソッドで実現できます(GH 9088)。シリーズに適切な型のデータが含まれていない場合、
Seriesアクセサ.dt、.cat、.strはTypeErrorではなくAttributeErrorを発生させるようになりました(GH 9617)。これにより、Pythonの組み込み例外階層により密接に準拠し、hasattr(s, 'cat')のようなテストがPython 2と3の両方で一貫性を保つようにします。Seriesは、整数型に対するビット演算をサポートするようになりました(GH 9016)。以前は、入力のdtypeが整数型であっても、出力のdtypeはboolに強制されていました。以前の動作
In [2]: pd.Series([0, 1, 2, 3], list('abcd')) | pd.Series([4, 4, 4, 4], list('abcd')) Out[2]: a True b True c True d True dtype: bool
新しい動作。入力dtypeが整数型の場合、出力dtypeも整数型になり、出力値はビット演算の結果になります。
In [2]: pd.Series([0, 1, 2, 3], list('abcd')) | pd.Series([4, 4, 4, 4], list('abcd')) Out[2]: a 4 b 5 c 6 d 7 dtype: int64
SeriesまたはDataFrameを含む除算では、0/0および0//0はnp.infではなくnp.nanを返すようになりました。(GH 9144, GH 8445)以前の動作
In [2]: p = pd.Series([0, 1]) In [3]: p / 0 Out[3]: 0 inf 1 inf dtype: float64 In [4]: p // 0 Out[4]: 0 inf 1 inf dtype: float64
新しい動作
In [38]: p = pd.Series([0, 1]) In [39]: p / 0 Out[39]: 0 NaN 1 inf Length: 2, dtype: float64 In [40]: p // 0 Out[40]: 0 NaN 1 inf Length: 2, dtype: float64
カテゴリカルデータに対する
Series.values_countsおよびSeries.describeは、NaNエントリを最後に配置するようになりました。(GH 9443)カテゴリカルデータに対する
Series.describeは、未使用のカテゴリに対して、NaNではなく0のカウントと頻度を返すようになりました(GH 9443)。バグ修正により、
DatetimeIndex.asofで部分文字列ラベルを検索する際に、部分文字列ラベルの開始後であっても、文字列に一致する値が含まれるようになりました(GH 9258)。以前の動作
In [4]: pd.to_datetime(['2000-01-31', '2000-02-28']).asof('2000-02') Out[4]: Timestamp('2000-01-31 00:00:00')
修正された動作
In [41]: pd.to_datetime(['2000-01-31', '2000-02-28']).asof('2000-02') Out[41]: Timestamp('2000-02-28 00:00:00')
以前の動作を再現するには、ラベルに精度を追加するだけです(例:
2000-02の代わりに2000-02-01を使用)。
非推奨#
rplotトレリスプロットインターフェースは非推奨となり、将来のバージョンで削除されます。より洗練された同様の機能については、seabornなどの外部パッケージを参照してください (GH 3445)。ドキュメントには、既存のコードをrplotからseabornに変換する方法の例がこちらに含まれています。pandas.sandbox.qtpandasインターフェースは非推奨となり、将来のバージョンで削除されます。ユーザーは外部パッケージpandas-qtを参照してください。(GH 9615)pandas.rpyインターフェースは非推奨となり、将来のバージョンで削除されます。同様の機能はrpy2プロジェクトを通じてアクセスできます(GH 9602)。別の
DatetimeIndex/PeriodIndexへのDatetimeIndex/PeriodIndexの追加は集合演算として非推奨になります。これは将来のバージョンでTypeErrorに変更されます。集合演算のユニオンには.union()を使用してください。(GH 9094)別の
DatetimeIndex/PeriodIndexからのDatetimeIndex/PeriodIndexの減算は、集合演算として非推奨になります。これは将来のバージョンで、TimeDeltaIndexを生成する実際の数値減算に変更されます。差集合演算には.difference()を使用してください。(GH 9094)
以前のバージョンの非推奨/変更の削除#
パフォーマンス改善#
配列またはリストライクな
.locインデックス作成のパフォーマンス低下を修正しました (GH 9126)。DataFrame.to_jsonの混合dtypeフレームのパフォーマンスが30倍向上しました。(GH 9037)MultiIndex.duplicatedにおけるパフォーマンス改善 (値の代わりにラベルで動作するように変更) (GH 9125)value_countsの代わりにuniqueを呼び出すことで、nuniqueの速度が向上しました(GH 9129, GH 7771)。同種/異種dtypeを適切に活用することで、
DataFrame.countおよびDataFrame.dropnaのパフォーマンスが最大10倍向上しました(GH 9136)。MultiIndexとlevelキーワード引数を使用する場合、DataFrame.countのパフォーマンスが最大20倍向上しました(GH 9163)。キー空間が
int64の範囲を超える場合のmergeのパフォーマンスとメモリ使用量が改善されました(GH 9151)。マルチキー
groupbyのパフォーマンスが向上しました(GH 9429)。MultiIndex.sortlevelのパフォーマンスが向上しました(GH 9445)。DataFrame.duplicatedのパフォーマンスとメモリ使用量が改善されました(GH 9398)。Cython化された
Period(GH 9440)to_hdfのメモリ使用量が減少しました(GH 9648)。
バグ修正#
.to_htmlをテーブル本文の先頭/末尾のスペースを削除するように変更しました(GH 4987)。Python 3でs3上の
read_csvを使用する際の問題を修正しました(GH 9452)。numpy.int_がnumpy.int32にデフォルト設定されるアーキテクチャに影響を与えるDatetimeIndexの互換性の問題を修正しました(GH 8943)。オブジェクトライクなものによるPanelのインデックス指定のバグ (GH 9140)
返された
Series.dt.componentsのインデックスがデフォルトのインデックスにリセットされるバグ(GH 9247)リストライクな入力でインデクサの型強制から誤った結果を得る
Categorical.__getitem__/__setitem__のバグ(GH 9469)。DatetimeIndexでの部分設定のバグ(GH 9478)
整数型およびdatetime64型カラムのgroupbyで、アグリゲータを適用したときに、数値が十分に大きい場合に値が変更されるバグ (GH 9311, GH 6620)
Timestampオブジェクト列(タイムゾーン情報を持つdatetime列)を適切なsqlalchemy型にマッピングする際のto_sqlのバグを修正しました(GH 9085)。to_sqlのdtype引数がインスタンス化されたSQLAlchemy型を受け付けないバグを修正しました(GH 9083)。np.datetime64を用いた.locの部分設定におけるバグ (GH 9516)datetimeのような見た目の
Seriesおよび.xsスライスで不正確なdtypeが推論される問題 (GH 9477)Categorical.unique()(およびsがcategoryのdtypeである場合のs.unique())の項目は、ソートされた順序ではなく、元の発見順に表示されるようになりました(GH 9331)。これは、pandasの他のdtypeの動作と一貫性があります。ビッグエンディアンプラットフォームで
StataReaderで誤った結果が生じるバグを修正しました(GH 8688)。多くのレベルを持つ場合にインデクサのオーバーフローを引き起こす
MultiIndex.has_duplicatesのバグ(GH 9075, GH 5873)。pivotおよびunstackにおけるバグで、nan値がインデックスアライメントを破壊する問題 (GH 4862, GH 7401, GH 7403, GH 7405, GH 7466, GH 9497)sort=Trueまたはヌル値を持つMultiIndexに対する左joinのバグ(GH 9210)。新しいキーを挿入できなかった
MultiIndexのバグ (GH 9250)。キー空間が
int64の範囲を超える場合のgroupbyのバグ(GH 9096)。TimedeltaIndexまたはDatetimeIndexとnull値を使用するunstackのバグ(GH 9491)。許容誤差のある浮動小数点数の比較が矛盾した動作を引き起こす
rankのバグ(GH 8365)。URLからデータをロードする際に
read_stataおよびStataReaderで発生していた文字エンコーディングのバグを修正しました(GH 9231)。offsets.Nanoを他のオフセットに追加するとTypeErrorが発生するバグ(GH 9284)。DST移行付近での
resampleにおけるバグ。これにより、オフセットクラスがDST移行で正しく動作するように修正する必要がありました。(GH 5172, GH 8744, GH 8653, GH 9173, GH 9468)。整数レベルでの二項演算子メソッド(例:
.mul())のアライメントのバグ(GH 9463)。箱ひげ図、散布図、六角形ビンプロットで不要な警告が表示されるバグ (GH 8877)
layoutkw を指定したサブプロットで不要な警告が表示されるバグ (GH 9464)ラップされた関数(例:
fillna)を使用する際に、引数(例:axis)を渡す必要があるグルーパ関数を使用する際のバグ(GH 9221)。DataFrameがコンストラクタでcopyとdtype引数を同時に適切にサポートするようになりました(GH 9099)。cエンジンで改行コードがCRのファイルに対してskiprowsを使用した場合の
read_csvのバグを修正しました(GH 9079)。isnullはPeriodIndexのNaTを検出するようになりました(GH 9129)。複数列groupbyでのgroupby
.nth()のバグ (GH 8979)DataFrame.whereとSeries.whereが数値を誤って文字列に変換するバグ(GH 9280)。DataFrame.whereおよびSeries.whereが文字列のリストライクを渡されたときにValueErrorを発生させるバグ(GH 9280)。非文字列値で
Series.strメソッドにアクセスすると、誤った結果ではなくTypeErrorが発生するようになりました(GH 9184)。インデックスに重複があり、単調増加でない場合の
DatetimeIndex.__contains__のバグ(GH 9512)。すべての値が等しい場合に
Series.kurt()で発生するゼロ除算エラーを修正しました(GH 9197)。xlsxwriterエンジンで、他の形式が適用されていない場合にセルにデフォルトの「General」形式を追加する問題を修正しました。これにより、他の行または列の形式が適用されるのを防いでいました。(GH 9167)read_csvでindex_col=Falseがusecolsも指定されている場合に発生する問題を修正しました。(GH 9082)wide_to_longが入力スタブ名リストを変更するバグ(GH 9204)。to_sqlがfloat64値を倍精度で保存しないバグ(GH 9009)。SparseSeriesおよびSparsePanelは、ゼロ引数コンストラクタ(非スパース対応のものと同じ)を受け入れるようになりました(GH 9272)。Categoricalとobjectdtypesのマージにおけるリグレッション (GH 9426)特定の不正な入力ファイルでバッファオーバーフローが発生する
read_csvのバグ(GH 9205)。Series.groupbyでMultiIndexレベルでグループ化する際にsort引数が無視されるバグを修正しました(GH 9444)。カテゴリカル列の場合に
sort=Falseが無視されるDataFrame.Groupbyのバグを修正しました。(GH 8868)Python 3でAmazon S3からCSVファイルを読み込む際にTypeErrorが発生するバグを修正しました(GH 9452)。
Google BigQueryリーダーで、クエリ結果に「jobComplete」キーが存在するもののFalseになる場合があるバグ(GH 8728)。
dropna=Trueのカテゴリ型SeriesでNaNを除外する際のSeries.values_countsのバグ(GH 9443)。DataFrame.std/var/semにおけるnumeric_onlyオプションの欠落を修正しました(GH 9201)。スカラーデータによる
PanelまたはPanel4Dの構築をサポートします(GH 8285)。Seriesのテキスト表現がmax_rows/max_columnsから切り離されました(GH 7508)。
Seriesの数値書式設定が、切り詰められた場合に一貫性がありませんでした(GH 8532)。以前の動作
In [2]: pd.options.display.max_rows = 10 In [3]: s = pd.Series([1,1,1,1,1,1,1,1,1,1,0.9999,1,1]*10) In [4]: s Out[4]: 0 1 1 1 2 1 ... 127 0.9999 128 1.0000 129 1.0000 Length: 130, dtype: float64
新しい動作
0 1.0000 1 1.0000 2 1.0000 3 1.0000 4 1.0000 ... 125 1.0000 126 1.0000 127 0.9999 128 1.0000 129 1.0000 dtype: float64
一部のケースでフレームに新しい項目を設定する際に、誤った
SettingWithCopy警告が生成されていました(GH 8730)。以下は以前、
SettingWithCopy警告を報告していました。In [42]: df1 = pd.DataFrame({'x': pd.Series(['a', 'b', 'c']), ....: 'y': pd.Series(['d', 'e', 'f'])}) ....: In [43]: df2 = df1[['x']] In [44]: df2['y'] = ['g', 'h', 'i']
貢献者#
このリリースには合計60人がパッチを貢献しました。名前に「+」が付いている人は初めてパッチを貢献しました。
Aaron Toth +
Alan Du +
Alessandro Amici +
アルテム・コルチンスキー
Ashwini Chaudhary +
Ben Schiller
Bill Letson
Brandon Bradley +
Chau Hoang +
Chris Reynolds
Chris Whelan +
Christer van der Meeren +
David Cottrell +
David Stephens
Ehsan Azarnasab +
Garrett-R +
ギョーム・ゲイ
Jake Torcasso +
Jason Sexauer
ジェフ・リーバック
John McNamara
Joris Van den Bossche
Joschka zur Jacobsmühlen +
Juarez Bochi +
Junya Hayashi +
K.-Michael Aye
Kerby Shedden +
ケビン・シェパード
Kieran O’Mahony
Kodi Arfer +
Matti Airas +
Min RK +
モルタダ・メヒヤル
Robert +
Scott E Lasley
Scott Lasley +
Sergio Pascual +
スキッパー・シーボールド
ステファン・ホイヤー
トーマス・グレンジャー
Tom Augspurger
TomAugspurger
Vladimir Filimonov +
Vyomkesh Tripathi +
Will Holmgren
Yulong Yang +
behzad nouri
bertrandhaut +
bjonen
cel4 +
clham
hsperr +
ischwabacher
jnmclarty
josham +
jreback
omtinez +
roch +
sinhrks
unutbu