バージョン 0.14.0 (2014年5月31日)#
これは0.13.1からのメジャーリリースであり、少数のAPI変更、いくつかの新機能、機能強化、パフォーマンス改善、そして多数のバグ修正が含まれています。すべてのユーザーにこのバージョンへのアップグレードを推奨します。
主な機能は以下の通りです。
Python 3.4を正式にサポート
SQLインターフェースが
sqlalchemyを使用するように更新されました。詳細はこちらを参照してください。表示インターフェースの変更。詳細はこちら
スライサーを使用したMultiIndexing。詳細はこちらを参照してください。
単一インデックスのDataFrameとMultiIndexed DataFrameを結合する機能。詳細はこちらを参照してください
groupbyの結果の一貫性が向上し、より柔軟なgroupbyの指定が可能になりました。詳細はこちらを参照してください。
祝日カレンダーが
CustomBusinessDayでサポートされるようになりました。詳細はこちらを参照してください。プロット機能にいくつかの改善が加えられました。hexbin、area、pieプロットなどです。詳細はこちらを参照してください。
I/O操作に関するパフォーマンスドキュメントセクション。詳細はこちらを参照してください。
警告
0.14.0では、すべてのNDFrameベースのコンテナが大幅な内部リファクタリングを受けました。以前は、同種のデータブロックごとに独自のラベルがあり、それらを親コンテナのラベルと同期させるには特別な注意が必要でした。これにより、ユーザー/APIの動作に目に見える変更はありません(GH 6745)。
APIの変更点#
read_excelはデフォルトシートとして0を使用します(GH 6573)ilocはスライスに対して範囲外のインデクサーを受け入れるようになりました。たとえば、インデックス付けされるオブジェクトの長さを超える値です。これらは除外されます。これにより、pandasはPython/NumPyの範囲外の値のインデックス付けにさらに適合します。範囲外の単一のインデクサーでオブジェクトの次元が削除される場合は、引き続きIndexErrorが発生します(GH 6296、GH 6299)。これにより、空の軸(たとえば、空のDataFrameが返される)になる可能性があります。In [1]: dfl = pd.DataFrame(np.random.randn(5, 2), columns=list('AB')) In [2]: dfl Out[2]: A B 0 0.469112 -0.282863 1 -1.509059 -1.135632 2 1.212112 -0.173215 3 0.119209 -1.044236 4 -0.861849 -2.104569 [5 rows x 2 columns] In [3]: dfl.iloc[:, 2:3] Out[3]: Empty DataFrame Columns: [] Index: [0, 1, 2, 3, 4] [5 rows x 0 columns] In [4]: dfl.iloc[:, 1:3] Out[4]: B 0 -0.282863 1 -1.135632 2 -0.173215 3 -1.044236 4 -2.104569 [5 rows x 1 columns] In [5]: dfl.iloc[4:6] Out[5]: A B 4 -0.861849 -2.104569 [1 rows x 2 columns]
これらは範囲外の選択です
>>> dfl.iloc[[4, 5, 6]] IndexError: positional indexers are out-of-bounds >>> dfl.iloc[:, 4] IndexError: single positional indexer is out-of-bounds
負の開始値、終了値、ステップ値を持つスライスがコーナーケースをより良く処理します(GH 6531)。
df.iloc[:-len(df)]は現在空ですdf.iloc[len(df)::-1]はすべての要素を逆順で列挙するようになりました
DataFrame.interpolate()キーワードdowncastのデフォルトがinferからNoneに変更されました。これは、明示的に要求されない限り元のdtypeを保持するためです(GH 6290)。データフレームをHTMLに変換する際、以前は
Empty DataFrameが返されていました。この特殊なケースは削除され、代わりに列名を持つヘッダーが返されるようになりました(GH 6062)。SeriesとIndexは、内部でより多くの共通操作を共有するようになりました。例えば、factorize(),nunique(),value_counts()はIndex型でもサポートされるようになりました。Series.weekdayプロパティはAPIの一貫性のためにSeriesから削除されました。DatetimeIndex/PeriodIndexメソッドをSeriesで使用すると、TypeErrorが発生するようになりました。(GH 4551、GH 4056、GH 5519、GH 6380、GH 7206)。DateTimeIndex/Timestampのis_month_start、is_month_end、is_quarter_start、is_quarter_end、is_year_start、is_year_endアクセサーを追加。これらはタイムスタンプがDateTimeIndex/Timestampの頻度で定義された月/四半期/年の開始/終了であるかどうかを示すブール配列を返します(GH 4565、GH 6998)。pandas.eval()/DataFrame.eval()/DataFrame.query()でのローカル変数の使用法が変更されました(GH 5987)。DataFrameメソッドでは、2つの変更がありました。列名がローカル変数よりも優先されるようになりました
ローカル変数は明示的に参照する必要があります。つまり、列ではないローカル変数がある場合でも、
'@'プレフィックスを使用して参照する必要があります。pandasが名前aの曖昧さについて文句を言うことなく、df.query('@a < a')のような式を持つことができます。トップレベルの
pandas.eval()関数では、'@'プレフィックスを使用することはできません。使用しようとするとエラーメッセージが表示されます。NameResolutionErrorは不要になったため削除されました。
query/evalでの列名とインデックス名の順序を定義し、文書化する(GH 6676)
concatは、必要に応じてシリーズ名または列の番号付けを使用して、混合されたSeriesとDataFrameを結合するようになりました(GH 2385)。詳細はドキュメントを参照してください。IndexクラスおよびIndex.delete()、Index.drop()メソッドでのスライスおよび高度な/ブールインデックス操作は、結果のインデックスの型を変更しなくなりました(GH 6440、GH 7040)。In [6]: i = pd.Index([1, 2, 3, 'a', 'b', 'c']) In [7]: i[[0, 1, 2]] Out[7]: Index([1, 2, 3], dtype='object') In [8]: i.drop(['a', 'b', 'c']) Out[8]: Index([1, 2, 3], dtype='object')
以前は、上記の操作は
Int64Indexを返していました。手動で行いたい場合は、Index.astype()を使用してください。In [9]: i[[0, 1, 2]].astype(np.int_) Out[9]: Index([1, 2, 3], dtype='int64')
set_indexは、MultiIndexesをタプルのIndexに変換しなくなりました。例えば、古い動作ではこのケースでIndexが返されていました(GH 6459)。# Old behavior, casted MultiIndex to an Index In [10]: tuple_ind Out[10]: Index([('a', 'c'), ('a', 'd'), ('b', 'c'), ('b', 'd')], dtype='object') In [11]: df_multi.set_index(tuple_ind) Out[11]: 0 1 (a, c) 0.471435 -1.190976 (a, d) 1.432707 -0.312652 (b, c) -0.720589 0.887163 (b, d) 0.859588 -0.636524 [4 rows x 2 columns] # New behavior In [12]: mi Out[12]: MultiIndex([('a', 'c'), ('a', 'd'), ('b', 'c'), ('b', 'd')], ) In [13]: df_multi.set_index(mi) Out[13]: 0 1 a c 0.471435 -1.190976 d 1.432707 -0.312652 b c -0.720589 0.887163 d 0.859588 -0.636524 [4 rows x 2 columns]
これは、複数のインデックスを
set_indexに渡す場合にも適用されます。# Old output, 2-level MultiIndex of tuples In [14]: df_multi.set_index([df_multi.index, df_multi.index]) Out[14]: 0 1 (a, c) (a, c) 0.471435 -1.190976 (a, d) (a, d) 1.432707 -0.312652 (b, c) (b, c) -0.720589 0.887163 (b, d) (b, d) 0.859588 -0.636524 [4 rows x 2 columns] # New output, 4-level MultiIndex In [15]: df_multi.set_index([df_multi.index, df_multi.index]) Out[15]: 0 1 a c a c 0.471435 -1.190976 d a d 1.432707 -0.312652 b c b c -0.720589 0.887163 d b d 0.859588 -0.636524 [4 rows x 2 columns]
統計モーメント関数
rolling_cov、rolling_corr、ewmcov、ewmcorr、expanding_cov、expanding_corrにpairwiseキーワードが追加され、移動窓共分散および相関行列の計算が可能になりました(GH 4950)。詳細はドキュメントの移動窓ペアワイズ共分散と相関の計算を参照してください。In [1]: df = pd.DataFrame(np.random.randn(10, 4), columns=list('ABCD')) In [4]: covs = pd.rolling_cov(df[['A', 'B', 'C']], ....: df[['B', 'C', 'D']], ....: 5, ....: pairwise=True) In [5]: covs[df.index[-1]] Out[5]: B C D A 0.035310 0.326593 -0.505430 B 0.137748 -0.006888 -0.005383 C -0.006888 0.861040 0.020762
Series.iteritems()は遅延評価されるようになりました(リストではなくイテレータを返します)。これは0.14以前の文書化された動作でした。(GH 6760)Indexに一意の要素を数えるためのnuniqueおよびvalue_counts関数を追加しました。(GH 6734)stackおよびunstackは、levelキーワードがIndex内の非一意の項目を参照する場合にValueErrorを発生させるようになりました(以前はKeyErrorを発生させていました)。 (GH 6738)Series.sortから未使用のorder引数を削除; argsはSeries.orderと同じ順序になりました;Series.orderに準拠するためにna_position引数を追加(GH 6847)Series.orderのデフォルトのソートアルゴリズムは、Series.sort(およびnumpyのデフォルト)に準拠するようにquicksortになりました。Series.order/sortにinplaceキーワードを追加して、逆操作にする(GH 6859)DataFrame.sortは、na_positionパラメータに従ってNaNsをソートの最初または最後に配置するようになりました。(GH 3917)concatでTextFileReaderを受け入れるようになりました。これは一般的なユーザーの慣用表現に影響を与えていました(GH 6583)。これは0.13.1からの回帰でした。IndexとSeriesにインデクサーと一意の値を取得するためのfactorize関数を追加しました(GH 7090)。Timestampと文字列のようなオブジェクトが混在するDataFrameに対する
describeは、異なるIndexを返します(GH 7088)。以前は、インデックスは意図せずソートされていました。booldtypeのみの算術演算は、+、-、*操作ではPython空間で評価され、それ以外ではエラーが発生するという警告を出すようになりました(GH 7011、GH 6762、GH 7015、GH 7210)。>>> x = pd.Series(np.random.rand(10) > 0.5) >>> y = True >>> x + y # warning generated: should do x | y instead UserWarning: evaluating in Python space because the '+' operator is not supported by numexpr for the bool dtype, use '|' instead >>> x / y # this raises because it doesn't make sense NotImplementedError: operator '/' not implemented for bool dtypes
HDFStoreでは、キーまたはセレクターが見つからない場合、select_as_multipleは常にKeyErrorを発生させます(GH 6177)。df['col'] = valueとdf.loc[:,'col'] = valueは完全に同等になりました。以前は、.locは結果のシリーズのdtypeを強制的に変換するとは限りませんでした(GH 6149)。dtypesとftypesは、空のコンテナではdtype=objectのシリーズを返すようになりました(GH 5740)。df.to_csvは、ターゲットパスもバッファも提供されていない場合、CSVデータの文字列を返すようになりました(GH 6061)。pd.infer_freq()は、無効なSeries/Index型が与えられた場合にTypeErrorを発生させるようになりました(GH 6407、GH 6463)。DataFame.sort_indexに渡されたタプルは、タプルのリストを必要とするのではなく、インデックスのレベルとして解釈されるようになりました(GH 4370)。すべてのオフセット操作は、
Timestamp型を返すようになりました(datetimeではなく)、Business/Weekの頻度が正しくありませんでした(GH 4069)。to_excelは、np.infを文字列表現に変換するようになりました。これはinf_repキーワード引数でカスタマイズ可能です(Excelにはネイティブの無限大表現がありません)(GH 6782)。pandas.compat.scipy.scoreatpercentileをnumpy.percentileに置き換える(GH 6810)datetime[ns]シリーズでの.quantileは、np.datetime64オブジェクトではなくTimestampを返すようになりました(GH 6810)。concatに無効な型が渡された場合、AssertionErrorをTypeErrorに変更(GH 6583)DataFrameにdata引数としてイテレータが渡された場合、TypeErrorを発生させる(GH 5357)
表示の変更#
大規模なDataFrameのデフォルトの表示方法が変更されました。
max_rowsおよび/またはmax_columnsを超えるDataFrameは、pandas.Seriesの表示と一貫性のある、中央で切り詰められたビューで表示されるようになりました(GH 5603)。以前のバージョンでは、DataFrameは次元の制約に達すると切り詰められ、省略記号(…)がデータの一部が切り捨てられたことを示していました。
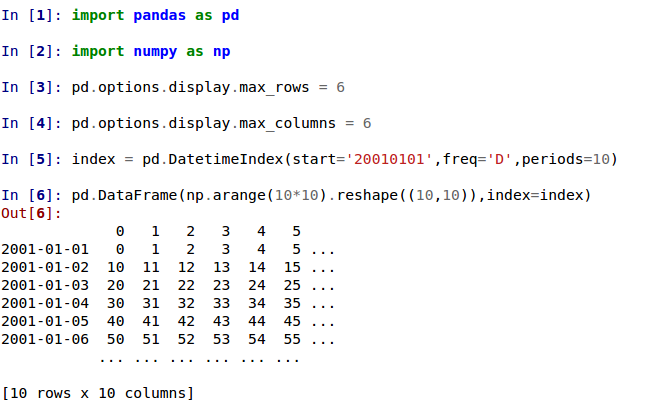
現在のバージョンでは、大きなDataFrameは中央で切り詰められ、両方の次元で先頭と末尾のプレビューが表示されます。
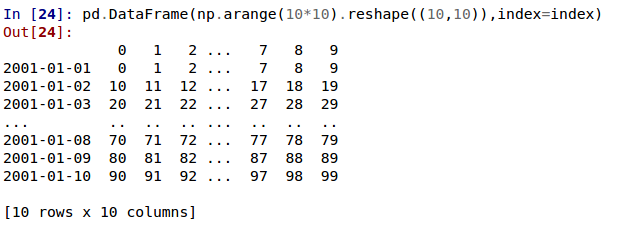
フレームが切り詰められている場合にのみ寸法を表示する
display.show_dimensionsのオプション'truncate'を許可する(GH 6547)。display.show_dimensionsのデフォルトはtruncateになりました。これはSeriesの表示長と一貫しています。In [16]: dfd = pd.DataFrame(np.arange(25).reshape(-1, 5), ....: index=[0, 1, 2, 3, 4], ....: columns=[0, 1, 2, 3, 4]) ....: # show dimensions since this is truncated In [17]: with pd.option_context('display.max_rows', 2, 'display.max_columns', 2, ....: 'display.show_dimensions', 'truncate'): ....: print(dfd) ....: 0 ... 4 0 0 ... 4 .. .. ... .. 4 20 ... 24 [5 rows x 5 columns] # will not show dimensions since it is not truncated In [18]: with pd.option_context('display.max_rows', 10, 'display.max_columns', 40, ....: 'display.show_dimensions', 'truncate'): ....: print(dfd) ....: 0 1 2 3 4 0 0 1 2 3 4 1 5 6 7 8 9 2 10 11 12 13 14 3 15 16 17 18 19 4 20 21 22 23 24
display.max_rowsがシリーズの長さよりも短い場合のMultiIndexed Seriesの表示における回帰(GH 7101)。切り詰められたSeriesまたはDataFrameのHTML表現で、
large_reprが「info」に設定されている場合にクラス名が表示されないバグを修正しました(GH 7105)。DataFrame.info()のverboseキーワードは、info表現を短縮するかどうかを制御しますが、デフォルトでNoneになりました。これはdisplay.max_info_columnsのグローバル設定に従います。グローバル設定はverbose=Trueまたはverbose=Falseで上書きできます。info表現がdisplay.max_info_columns設定を尊重しないバグを修正しました(GH 6939)。Timestamp __repr__にオフセット/頻度情報が追加されました(GH 4553)。
テキスト解析APIの変更#
read_csv()/read_table()は、無効なオプションに対して、PythonParserにフォールバックするのではなく、より多くの警告を発するようになりました。
read_csv()/read_table()でdelim_whitespace=Trueとともにsepが指定された場合、ValueErrorを発生させる(GH 6607)read_csv()/read_table()でサポートされていないオプションとともにengine='c'が指定された場合、ValueErrorを発生させる(GH 6607)Pythonパーサーへのフォールバックによってオプションが無視される場合に
ValueErrorを発生させる(GH 6607)オプションが無視されない場合にPythonパーサーにフォールバックする際、
ParserWarningを生成する(GH 6607)他のC言語非対応オプションが指定されていない場合、
read_csv()/read_table()でsep='\s+'をdelim_whitespace=Trueに変換する(GH 6607)
GroupBy APIの変更#
一部のgroupbyメソッドの動作がより一貫性を持つようになりました
groupbyの
headおよびtailは、集約ではなくfilterのような動作をするようになりましたIn [1]: df = pd.DataFrame([[1, 2], [1, 4], [5, 6]], columns=['A', 'B']) In [2]: g = df.groupby('A') In [3]: g.head(1) # filters DataFrame Out[3]: A B 0 1 2 2 5 6 In [4]: g.apply(lambda x: x.head(1)) # used to simply fall-through Out[4]: A B A 1 0 1 2 5 2 5 6
groupby headとtailは列選択を尊重します
In [19]: g[['B']].head(1) Out[19]: B 0 2 2 6 [2 rows x 1 columns]
groupby
nthはデフォルトで縮小されるようになりました。as_index=Falseを渡すことでフィルタリングを実現できます。NaNを無視するオプションのdropna引数も利用できます。詳細はドキュメントを参照してください。削減
In [19]: df = pd.DataFrame([[1, np.nan], [1, 4], [5, 6]], columns=['A', 'B']) In [20]: g = df.groupby('A') In [21]: g.nth(0) Out[21]: A B 0 1 NaN 2 5 6.0 [2 rows x 2 columns] # this is equivalent to g.first() In [22]: g.nth(0, dropna='any') Out[22]: A B 1 1 4.0 2 5 6.0 [2 rows x 2 columns] # this is equivalent to g.last() In [23]: g.nth(-1, dropna='any') Out[23]: A B 1 1 4.0 2 5 6.0 [2 rows x 2 columns]
フィルタリング
In [24]: gf = df.groupby('A', as_index=False) In [25]: gf.nth(0) Out[25]: A B 0 1 NaN 2 5 6.0 [2 rows x 2 columns] In [26]: gf.nth(0, dropna='any') Out[26]: A B 1 1 4.0 2 5 6.0 [2 rows x 2 columns]
groupbyは、Cython関数ではない場合、グループ化された列を返さなくなります(GH 5610、GH 5614、GH 6732)。これはすでにインデックスであるためです。
In [27]: df = pd.DataFrame([[1, np.nan], [1, 4], [5, 6], [5, 8]], columns=['A', 'B']) In [28]: g = df.groupby('A') In [29]: g.count() Out[29]: B A 1 1 5 2 [2 rows x 1 columns] In [30]: g.describe() Out[30]: B count mean std min 25% 50% 75% max A 1 1.0 4.0 NaN 4.0 4.0 4.0 4.0 4.0 5 2.0 7.0 1.414214 6.0 6.5 7.0 7.5 8.0 [2 rows x 8 columns]
as_indexを渡すと、グループ化された列はそのまま残ります(これは0.14.0では変更されていません)。In [31]: df = pd.DataFrame([[1, np.nan], [1, 4], [5, 6], [5, 8]], columns=['A', 'B']) In [32]: g = df.groupby('A', as_index=False) In [33]: g.count() Out[33]: A B 0 1 1 1 5 2 [2 rows x 2 columns] In [34]: g.describe() Out[34]: A B count mean std min 25% 50% 75% max 0 1 1.0 4.0 NaN 4.0 4.0 4.0 4.0 4.0 1 5 2.0 7.0 1.414214 6.0 6.5 7.0 7.5 8.0 [2 rows x 9 columns]
pd.Grouperを介して、より複雑なgroupby(時刻と文字列フィールドを同時にグループ化するなど)を指定できるようになりました。詳細はドキュメントを参照してください。(GH 3794)groupby操作を実行する際のSeries名の伝播/保持の改善
SQL#
SQLの読み書き関数は、SQLAlchemyを介してより多くのデータベースフレーバーをサポートするようになりました(GH 2717、GH 4163、GH 5950、GH 6292)。SQLAlchemyがサポートするすべてのデータベース(PostgreSQL、MySQL、Oracle、Microsoft SQL Serverなど)が使用できます(SQLAlchemyの含まれるダイアレクトに関するドキュメントを参照)。
DBAPI接続オブジェクトを提供する機能は、将来的にはsqlite3のみでサポートされます。'mysql'フレーバーは非推奨です。
新しい関数read_sql_query()とread_sql_table()が導入されました。read_sql()関数は、他の2つの便利なラッパーとして維持され、提供された入力(データベーステーブル名またはSQLクエリ)に応じて特定の関数に委譲します。
実際には、SQL関数にSQLAlchemyのengineを提供する必要があります。SQLAlchemyで接続するには、create_engine()関数を使用してデータベースURIからエンジンオブジェクトを作成します。接続するデータベースごとにエンジンを作成する必要があるのは1回だけです。インメモリのsqliteデータベースの場合
In [35]: from sqlalchemy import create_engine
# Create your connection.
In [36]: engine = create_engine('sqlite:///:memory:')
このengineは、このデータベースへのデータ書き込みまたは読み取りに使用できます。
In [37]: df = pd.DataFrame({'A': [1, 2, 3], 'B': ['a', 'b', 'c']})
In [38]: df.to_sql(name='db_table', con=engine, index=False)
Out[38]: 3
テーブル名を指定してデータベースからデータを読み取ることができます。
In [39]: pd.read_sql_table('db_table', engine)
Out[39]:
A B
0 1 a
1 2 b
2 3 c
[3 rows x 2 columns]
またはSQLクエリを指定する
In [40]: pd.read_sql_query('SELECT * FROM db_table', engine)
Out[40]:
A B
0 1 a
1 2 b
2 3 c
[3 rows x 2 columns]
SQL関数へのその他の機能強化には以下が含まれます。
インデックス書き込みのサポート。これは
indexキーワード(デフォルトはTrue)で制御できます。インデックスを書き込む際に使用する列ラベルを
index_labelで指定します。read_sql_query()およびread_sql_table()のparse_datesキーワードを使用して、datetimeとして解析する文字列列を指定します。
警告
既存の関数または関数エイリアスの一部は非推奨となり、将来のバージョンで削除されます。これには、tquery、uquery、read_frame、frame_query、write_frameが含まれます。
警告
DBAPI接続オブジェクトを使用する際の「mysql」フレーバーのサポートは非推奨となりました。MySQLは引き続きSQLAlchemyエンジンでサポートされます(GH 6900)。
スライサーを使用したマルチインデックス#
0.14.0では、MultiIndexedオブジェクトをスライスする新しい方法を追加しました。複数のインデクサーを提供することで、MultiIndexをスライスできます。
スライス、ラベルのリスト、ラベル、ブールインデクサーなど、ラベルによる選択と同様に、任意のセレクターを提供できます。
slice(None) を使用して、そのレベルのすべての内容を選択できます。より深いレベルをすべて指定する必要はありません。slice(None) として暗黙的に指定されます。
いつものように、これはラベルインデックス付けであるため、スライサーの両側が含まれます。
詳細はドキュメントを参照してください。また、以下の問題も参照してください(GH 6134、GH 4036、GH 3057、GH 2598、GH 5641、GH 7106)。
警告
.loc指定子ではすべての軸を指定する必要があります。つまり、インデックスと列の両方のインデクサーを指定します。渡されたインデクサーが、行のMultiIndexではなく、*両方*の軸をインデックス付けしていると誤解される可能性がある曖昧なケースがいくつかあります。このようにすべきです
>>> df.loc[(slice('A1', 'A3'), ...), :] # noqa: E901
rather than this:
>>> df.loc[(slice('A1', 'A3'), ...)] # noqa: E901
警告
選択軸が完全に辞書順にソートされていることを確認する必要があります!
In [41]: def mklbl(prefix, n):
....: return ["%s%s" % (prefix, i) for i in range(n)]
....:
In [42]: index = pd.MultiIndex.from_product([mklbl('A', 4),
....: mklbl('B', 2),
....: mklbl('C', 4),
....: mklbl('D', 2)])
....:
In [43]: columns = pd.MultiIndex.from_tuples([('a', 'foo'), ('a', 'bar'),
....: ('b', 'foo'), ('b', 'bah')],
....: names=['lvl0', 'lvl1'])
....:
In [44]: df = pd.DataFrame(np.arange(len(index) * len(columns)).reshape((len(index),
....: len(columns))),
....: index=index,
....: columns=columns).sort_index().sort_index(axis=1)
....:
In [45]: df
Out[45]:
lvl0 a b
lvl1 bar foo bah foo
A0 B0 C0 D0 1 0 3 2
D1 5 4 7 6
C1 D0 9 8 11 10
D1 13 12 15 14
C2 D0 17 16 19 18
... ... ... ... ...
A3 B1 C1 D1 237 236 239 238
C2 D0 241 240 243 242
D1 245 244 247 246
C3 D0 249 248 251 250
D1 253 252 255 254
[64 rows x 4 columns]
スライス、リスト、およびラベルを使用した基本的なMultiIndexスライシング。
In [46]: df.loc[(slice('A1', 'A3'), slice(None), ['C1', 'C3']), :]
Out[46]:
lvl0 a b
lvl1 bar foo bah foo
A1 B0 C1 D0 73 72 75 74
D1 77 76 79 78
C3 D0 89 88 91 90
D1 93 92 95 94
B1 C1 D0 105 104 107 106
... ... ... ... ...
A3 B0 C3 D1 221 220 223 222
B1 C1 D0 233 232 235 234
D1 237 236 239 238
C3 D0 249 248 251 250
D1 253 252 255 254
[24 rows x 4 columns]
pd.IndexSliceを使用して、これらのスライスの作成を省略できます。
In [47]: idx = pd.IndexSlice
In [48]: df.loc[idx[:, :, ['C1', 'C3']], idx[:, 'foo']]
Out[48]:
lvl0 a b
lvl1 foo foo
A0 B0 C1 D0 8 10
D1 12 14
C3 D0 24 26
D1 28 30
B1 C1 D0 40 42
... ... ...
A3 B0 C3 D1 220 222
B1 C1 D0 232 234
D1 236 238
C3 D0 248 250
D1 252 254
[32 rows x 2 columns]
この方法を使用すると、複数の軸に対して同時に非常に複雑な選択を実行できます。
In [49]: df.loc['A1', (slice(None), 'foo')]
Out[49]:
lvl0 a b
lvl1 foo foo
B0 C0 D0 64 66
D1 68 70
C1 D0 72 74
D1 76 78
C2 D0 80 82
... ... ...
B1 C1 D1 108 110
C2 D0 112 114
D1 116 118
C3 D0 120 122
D1 124 126
[16 rows x 2 columns]
In [50]: df.loc[idx[:, :, ['C1', 'C3']], idx[:, 'foo']]
Out[50]:
lvl0 a b
lvl1 foo foo
A0 B0 C1 D0 8 10
D1 12 14
C3 D0 24 26
D1 28 30
B1 C1 D0 40 42
... ... ...
A3 B0 C3 D1 220 222
B1 C1 D0 232 234
D1 236 238
C3 D0 248 250
D1 252 254
[32 rows x 2 columns]
ブールインデクサーを使用すると、値に関連する選択を提供できます。
In [51]: mask = df[('a', 'foo')] > 200
In [52]: df.loc[idx[mask, :, ['C1', 'C3']], idx[:, 'foo']]
Out[52]:
lvl0 a b
lvl1 foo foo
A3 B0 C1 D1 204 206
C3 D0 216 218
D1 220 222
B1 C1 D0 232 234
D1 236 238
C3 D0 248 250
D1 252 254
[7 rows x 2 columns]
.locのaxis引数を指定して、渡されたスライサーを単一軸で解釈することもできます。
In [53]: df.loc(axis=0)[:, :, ['C1', 'C3']]
Out[53]:
lvl0 a b
lvl1 bar foo bah foo
A0 B0 C1 D0 9 8 11 10
D1 13 12 15 14
C3 D0 25 24 27 26
D1 29 28 31 30
B1 C1 D0 41 40 43 42
... ... ... ... ...
A3 B0 C3 D1 221 220 223 222
B1 C1 D0 233 232 235 234
D1 237 236 239 238
C3 D0 249 248 251 250
D1 253 252 255 254
[32 rows x 4 columns]
さらに、これらのメソッドを使用して値を設定できます。
In [54]: df2 = df.copy()
In [55]: df2.loc(axis=0)[:, :, ['C1', 'C3']] = -10
In [56]: df2
Out[56]:
lvl0 a b
lvl1 bar foo bah foo
A0 B0 C0 D0 1 0 3 2
D1 5 4 7 6
C1 D0 -10 -10 -10 -10
D1 -10 -10 -10 -10
C2 D0 17 16 19 18
... ... ... ... ...
A3 B1 C1 D1 -10 -10 -10 -10
C2 D0 241 240 243 242
D1 245 244 247 246
C3 D0 -10 -10 -10 -10
D1 -10 -10 -10 -10
[64 rows x 4 columns]
アライン可能なオブジェクトの右側を使用することもできます。
In [57]: df2 = df.copy()
In [58]: df2.loc[idx[:, :, ['C1', 'C3']], :] = df2 * 1000
In [59]: df2
Out[59]:
lvl0 a b
lvl1 bar foo bah foo
A0 B0 C0 D0 1 0 3 2
D1 5 4 7 6
C1 D0 9000 8000 11000 10000
D1 13000 12000 15000 14000
C2 D0 17 16 19 18
... ... ... ... ...
A3 B1 C1 D1 237000 236000 239000 238000
C2 D0 241 240 243 242
D1 245 244 247 246
C3 D0 249000 248000 251000 250000
D1 253000 252000 255000 254000
[64 rows x 4 columns]
プロット#
DataFrame.plotのkind='hexbin'による六角形ビンプロット(GH 5478)、詳細はドキュメントを参照してください。DataFrame.plotとSeries.plotは、kind='area'を指定することで面積プロットをサポートするようになりました(GH 6656)。詳細はドキュメントを参照してください。Series.plotとDataFrame.plotのkind='pie'による円グラフ(GH 6976)、詳細はドキュメントを参照してください。DataFrameおよびSeriesオブジェクトの.plotメソッドで、エラーバー付きプロットがサポートされるようになりました(GH 3796、GH 6834)。詳細はドキュメントを参照してください。DataFrame.plotとSeries.plotは、matplotlib.Tableをプロットするためのtableキーワードをサポートするようになりました。詳細はドキュメントを参照してください。tableキーワードは以下の値を受け取ることができます。False: 何もしない(デフォルト)。True:DataFrameまたはSeriesのplotメソッドを呼び出してテーブルを描画します。matplotlibのデフォルトレイアウトに合わせてデータは転置されます。DataFrameまたはSeries: 渡されたデータを使用してmatplotlib.tableを描画します。データはprintメソッドで表示されるとおりに描画されます(自動的に転置されません)。また、DataFrameおよびSeriesからテーブルを作成し、matplotlib.Axesに追加するためのヘルパー関数pandas.tools.plotting.tableが追加されました。
plot(legend='reverse')は、ほとんどのプロットの種類で凡例ラベルの順序を逆にするようになりました。(GH 6014)折れ線グラフと面積グラフは
stacked=Trueで積み重ねることができます(GH 6656)。DataFrame.plot()にkind='bar'およびkind='barh'を指定した場合、以下のキーワードが受け入れられるようになりました。width: バーの幅を指定します。以前のバージョンでは、matplotlibに静的な値0.5が渡され、上書きできませんでした。(GH 6604)align: バーの配置を指定します。デフォルトはcenter(matplotlibとは異なります)。以前のバージョンでは、pandasはmatplotlibにalign='edge'を渡し、自身で位置をcenterに調整していました。その結果、alignキーワードは期待どおりに適用されませんでした。(GH 4525)position: 棒グラフのレイアウトの相対的な配置を指定します。0(左/下端)から1(右/上端)まで。デフォルトは0.5(中央)です。(GH 6604)
alignのデフォルト値が変更されたため、棒グラフの座標は整数値(0.0、1.0、2.0など)に配置されるようになりました。これは、棒グラフが折れ線グラフと同じ座標に配置されることを意図しています。ただし、set_xlim、set_ylimなどを使用して棒の位置や描画領域を手動で調整する場合、棒グラフが予期せず異なる場合があります。これらの場合、新しい座標に合わせてスクリプトを修正してください。parallel_coordinates()関数は、colorsではなくcolor引数を受け取るようになりました。古いcolors引数は将来のリリースでサポートされなくなることを警告するFutureWarningが発行されます。(GH 6956)parallel_coordinates()関数およびandrews_curves()関数は、dataではなく位置引数frameを受け取るようになりました。古いdata引数が名前で指定された場合、FutureWarningが発行されます。(GH 6956)DataFrame.boxplot()はlayoutキーワードをサポートするようになりました(GH 6769)。DataFrame.boxplot()には新しいキーワード引数return_typeがあります。'dict'、'axes'、または'both'を受け入れ、この場合、matplotlibの軸とmatplotlib Linesの辞書を含む名前付きタプルが返されます。
以前のバージョンの非推奨/変更#
以前のバージョンの非推奨事項が0.14.0から有効になっています。
DatetimeIndexを優先してDateRangeを削除する(GH 6816)DataFrame.sortからcolumnキーワードを削除(GH 4370)set_eng_float_format()からprecisionキーワードを削除(GH 395)DataFrame.to_string()、DataFrame.to_latex()、およびDataFrame.to_html()からforce_unicodeキーワードを削除します。これらの関数はデフォルトでUnicodeでエンコードします(GH 2224、GH 2225)。DataFrame.to_csv()およびDataFrame.to_string()からnanRepキーワードを削除(GH 275)HDFStore.select_column()からuniqueキーワードを削除(GH 3256)Timestamp.offset()からinferTimeRuleキーワードを削除(GH 391)get_data_yahoo()とget_data_google()からnameキーワードを削除(commit b921d1a)DatetimeIndexコンストラクタからoffsetキーワードを削除(commit 3136390)rolling_sum()のような、いくつかの移動モーメント統計関数からtime_ruleを削除する(GH 1042)。負の
-ブール演算をnumpy配列から削除し、代わりにinv~を使用します。これはnumpy 1.9で非推奨になるためです(GH 6960)。
非推奨#
pivot_table()/DataFrame.pivot_table()およびcrosstab()関数は、rowsおよびcolsではなく、indexおよびcolumns引数を受け取るようになりました。古いrowsおよびcols引数は将来のリリースでサポートされなくなることを警告するFutureWarningが発行されます(GH 5505)。DataFrame.drop_duplicates()およびDataFrame.duplicated()メソッドは、DataFrame.dropna()とより適切に整合させるため、colsではなくsubset引数を受け取るようになりました。古いcols引数は将来のリリースでサポートされなくなることを警告するFutureWarningが発行されます(GH 6680)。DataFrame.to_csv()およびDataFrame.to_excel()関数は、colsではなくcolumns引数を受け取るようになりました。古いcols引数は将来のリリースでサポートされなくなることを警告するFutureWarningが発行されます(GH 6645)。インデクサーは、スカラーインデクサーと非浮動小数点インデックスで使用される場合、
FutureWarningを警告します(GH 4892、GH 6960)。# non-floating point indexes can only be indexed by integers / labels In [1]: pd.Series(1, np.arange(5))[3.0] pandas/core/index.py:469: FutureWarning: scalar indexers for index type Int64Index should be integers and not floating point Out[1]: 1 In [2]: pd.Series(1, np.arange(5)).iloc[3.0] pandas/core/index.py:469: FutureWarning: scalar indexers for index type Int64Index should be integers and not floating point Out[2]: 1 In [3]: pd.Series(1, np.arange(5)).iloc[3.0:4] pandas/core/index.py:527: FutureWarning: slice indexers when using iloc should be integers and not floating point Out[3]: 3 1 dtype: int64 # these are Float64Indexes, so integer or floating point is acceptable In [4]: pd.Series(1, np.arange(5.))[3] Out[4]: 1 In [5]: pd.Series(1, np.arange(5.))[3.0] Out[6]: 1
Numpy 1.9の非推奨警告との互換性(GH 6960)
Panel.shift()は、DataFrame.shift()と一致する関数シグネチャを持つようになりました。以前の位置引数lagsは、デフォルト値1のキーワード引数periodsに変更されました。古い引数lagsが名前で使用された場合、FutureWarningが発行されます。(GH 6910)factorize()のorderキーワード引数は削除されます。(GH 6926)。DataFrame.xs()、Panel.major_xs()、Panel.minor_xs()からcopyキーワードを削除しました。可能な場合はビューが返され、そうでない場合はコピーが作成されます。以前は、ユーザーはcopy=Falseが常にビューを返すと考えていた可能性があります。(GH 6894)parallel_coordinates()関数は、colorsではなくcolor引数を受け取るようになりました。古いcolors引数は将来のリリースでサポートされなくなることを警告するFutureWarningが発行されます。(GH 6956)parallel_coordinates()関数およびandrews_curves()関数は、dataではなく位置引数frameを受け取るようになりました。古いdata引数が名前で指定された場合、FutureWarningが発行されます。(GH 6956)DBAPI接続オブジェクトを使用する際の「mysql」フレーバーのサポートは非推奨となりました。MySQLは引き続きSQLAlchemyエンジンでサポートされます(GH 6900)。
以下の
io.sql関数は非推奨になりました:tquery,uquery,read_frame,frame_query,write_frame。describe()のpercentile_widthキーワード引数は非推奨になりました。代わりに、表示するパーセンタイルリストを受け取るpercentilesキーワードを使用してください。デフォルトの出力は変更されていません。boxplot()のデフォルトの戻り値の型は、将来のリリースでdictからmatplotlib Axesに変更されます。return_type='axes'をboxplotに渡すことで、将来の動作を今すぐ使用できます。
既知の問題#
OpenPyXL 2.0.0で後方互換性が損なわれる(GH 7169)
機能強化#
DataFrameとSeriesは、タプル辞書が渡された場合にMultiIndexオブジェクトを作成します。詳細はドキュメントを参照してください(GH 3323)。
In [60]: pd.Series({('a', 'b'): 1, ('a', 'a'): 0, ....: ('a', 'c'): 2, ('b', 'a'): 3, ('b', 'b'): 4}) ....: Out[60]: a b 1 a 0 c 2 b a 3 b 4 Length: 5, dtype: int64 In [61]: pd.DataFrame({('a', 'b'): {('A', 'B'): 1, ('A', 'C'): 2}, ....: ('a', 'a'): {('A', 'C'): 3, ('A', 'B'): 4}, ....: ('a', 'c'): {('A', 'B'): 5, ('A', 'C'): 6}, ....: ('b', 'a'): {('A', 'C'): 7, ('A', 'B'): 8}, ....: ('b', 'b'): {('A', 'D'): 9, ('A', 'B'): 10}}) ....: Out[61]: a b b a c a b A B 1.0 4.0 5.0 8.0 10.0 C 2.0 3.0 6.0 7.0 NaN D NaN NaN NaN NaN 9.0 [3 rows x 5 columns]
Indexにsym_diffメソッドが追加されました(GH 5543)。DataFrame.to_latexは、longtableキーワードを受け取るようになりました。これがTrueの場合、longtable環境でテーブルが返されます。(GH 6617)DataFrame.to_latexでエスケープをオフにするオプションを追加(GH 6472)pd.read_clipboardは、キーワードsepが指定されていない場合、スプレッドシートからコピーされたデータを検出し、それに応じて解析しようとします。(GH 6223)単一インデックスのDataFrameとMultiIndexed DataFrameの結合(GH 3662)
詳細はドキュメントを参照してください。MultiIndex DataFrameを左右両方で結合することは、現時点ではまだサポートされていません。
In [62]: household = pd.DataFrame({'household_id': [1, 2, 3], ....: 'male': [0, 1, 0], ....: 'wealth': [196087.3, 316478.7, 294750] ....: }, ....: columns=['household_id', 'male', 'wealth'] ....: ).set_index('household_id') ....: In [63]: household Out[63]: male wealth household_id 1 0 196087.3 2 1 316478.7 3 0 294750.0 [3 rows x 2 columns] In [64]: portfolio = pd.DataFrame({'household_id': [1, 2, 2, 3, 3, 3, 4], ....: 'asset_id': ["nl0000301109", ....: "nl0000289783", ....: "gb00b03mlx29", ....: "gb00b03mlx29", ....: "lu0197800237", ....: "nl0000289965", ....: np.nan], ....: 'name': ["ABN Amro", ....: "Robeco", ....: "Royal Dutch Shell", ....: "Royal Dutch Shell", ....: "AAB Eastern Europe Equity Fund", ....: "Postbank BioTech Fonds", ....: np.nan], ....: 'share': [1.0, 0.4, 0.6, 0.15, 0.6, 0.25, 1.0] ....: }, ....: columns=['household_id', 'asset_id', 'name', 'share'] ....: ).set_index(['household_id', 'asset_id']) ....: In [65]: portfolio Out[65]: name share household_id asset_id 1 nl0000301109 ABN Amro 1.00 2 nl0000289783 Robeco 0.40 gb00b03mlx29 Royal Dutch Shell 0.60 3 gb00b03mlx29 Royal Dutch Shell 0.15 lu0197800237 AAB Eastern Europe Equity Fund 0.60 nl0000289965 Postbank BioTech Fonds 0.25 4 NaN NaN 1.00 [7 rows x 2 columns] In [66]: household.join(portfolio, how='inner') Out[66]: male ... share household_id asset_id ... 1 nl0000301109 0 ... 1.00 2 nl0000289783 1 ... 0.40 gb00b03mlx29 1 ... 0.60 3 gb00b03mlx29 0 ... 0.15 lu0197800237 0 ... 0.60 nl0000289965 0 ... 0.25 [6 rows x 4 columns]
DataFrame.to_csvを使用する際に、quotechar、doublequote、およびescapecharを指定できるようになりました(GH 5414、GH 4528)。sort_remainingブール型kwargを使用して、MultiIndexの指定されたレベルのみで部分的にソートします。(GH 3984)TimeStampおよびDatetimeIndexにto_julian_dateを追加しました。ユリウス日は主に天文学で使用され、紀元前4713年1月1日正午からの日数を示します。pandasではナノ秒を使用して時間を定義するため、使用できる日付の実際の範囲は西暦1678年から2262年までです。(GH 4041)DataFrame.to_stataはStataデータ型との互換性をチェックし、必要に応じてアップキャストするようになりました。データ損失なくアップキャストできない場合は警告が発行されます(GH 6327)。DataFrame.to_stataとStataWriterは、ファイル作成時にタイムスタンプとデータセットラベルを設定できるキーワード引数time_stampとdata_labelを受け入れるようになりました。(GH 6545)pandas.io.gbqはユニコード文字列の読み込みを正しく処理するようになりました。(GH 5940)祝日カレンダーが利用可能になり、
CustomBusinessDayオフセットで使用できるようになりました(GH 6719)。Float64Indexは、objectdtype配列ではなく、float64dtype ndarrayによってサポートされるようになりました(GH 6471)。Panel.pct_changeを実装しました(GH 6904)ローリングモーメント関数に
howオプションを追加し、リサンプリングの処理方法を指定できるようにしました。rolling_max()はデフォルトでmax、rolling_min()はデフォルトでmin、その他はデフォルトでmeanとなります(GH 6297)。CustomBusinessMonthBeginとCustomBusinessMonthEndが利用可能になりました(GH 6866)。Series.quantile()とDataFrame.quantile()は、分位点の配列を受け入れるようになりました。describe()は、要約統計量に含めるパーセンタイルの配列を受け入れるようになりました(GH 4196)。pivot_tableは、indexおよびcolumnsキーワードでGrouperを受け入れることができるようになりました(GH 6913)。In [67]: import datetime In [68]: df = pd.DataFrame({ ....: 'Branch': 'A A A A A B'.split(), ....: 'Buyer': 'Carl Mark Carl Carl Joe Joe'.split(), ....: 'Quantity': [1, 3, 5, 1, 8, 1], ....: 'Date': [datetime.datetime(2013, 11, 1, 13, 0), ....: datetime.datetime(2013, 9, 1, 13, 5), ....: datetime.datetime(2013, 10, 1, 20, 0), ....: datetime.datetime(2013, 10, 2, 10, 0), ....: datetime.datetime(2013, 11, 1, 20, 0), ....: datetime.datetime(2013, 10, 2, 10, 0)], ....: 'PayDay': [datetime.datetime(2013, 10, 4, 0, 0), ....: datetime.datetime(2013, 10, 15, 13, 5), ....: datetime.datetime(2013, 9, 5, 20, 0), ....: datetime.datetime(2013, 11, 2, 10, 0), ....: datetime.datetime(2013, 10, 7, 20, 0), ....: datetime.datetime(2013, 9, 5, 10, 0)]}) ....: In [69]: df Out[69]: Branch Buyer Quantity Date PayDay 0 A Carl 1 2013-11-01 13:00:00 2013-10-04 00:00:00 1 A Mark 3 2013-09-01 13:05:00 2013-10-15 13:05:00 2 A Carl 5 2013-10-01 20:00:00 2013-09-05 20:00:00 3 A Carl 1 2013-10-02 10:00:00 2013-11-02 10:00:00 4 A Joe 8 2013-11-01 20:00:00 2013-10-07 20:00:00 5 B Joe 1 2013-10-02 10:00:00 2013-09-05 10:00:00 [6 rows x 5 columns]
In [75]: df.pivot_table(values='Quantity', ....: index=pd.Grouper(freq='M', key='Date'), ....: columns=pd.Grouper(freq='M', key='PayDay'), ....: aggfunc="sum") Out[75]: PayDay 2013-09-30 2013-10-31 2013-11-30 Date 2013-09-30 NaN 3.0 NaN 2013-10-31 6.0 NaN 1.0 2013-11-30 NaN 9.0 NaN [3 rows x 3 columns]
文字列の配列を指定された幅で折り返すことができるようになりました(
str.wrap)(GH 6999)Seriesにnsmallest()およびSeries.nlargest()メソッドを追加しました。詳細はドキュメントを参照してください(GH 3960)。PeriodIndexは、DatetimeIndexのように部分文字列インデックス付けを完全にサポートするようになりました(GH 7043)。In [76]: prng = pd.period_range('2013-01-01 09:00', periods=100, freq='H') In [77]: ps = pd.Series(np.random.randn(len(prng)), index=prng) In [78]: ps Out[78]: 2013-01-01 09:00 0.015696 2013-01-01 10:00 -2.242685 2013-01-01 11:00 1.150036 2013-01-01 12:00 0.991946 2013-01-01 13:00 0.953324 ... 2013-01-05 08:00 0.285296 2013-01-05 09:00 0.484288 2013-01-05 10:00 1.363482 2013-01-05 11:00 -0.781105 2013-01-05 12:00 -0.468018 Freq: H, Length: 100, dtype: float64 In [79]: ps['2013-01-02'] Out[79]: 2013-01-02 00:00 0.553439 2013-01-02 01:00 1.318152 2013-01-02 02:00 -0.469305 2013-01-02 03:00 0.675554 2013-01-02 04:00 -1.817027 ... 2013-01-02 19:00 0.036142 2013-01-02 20:00 -2.074978 2013-01-02 21:00 0.247792 2013-01-02 22:00 -0.897157 2013-01-02 23:00 -0.136795 Freq: H, Length: 24, dtype: float64
read_excelは、xlrd >= 0.9.3 を使用して、Excelの日付と時刻のミリ秒を読み取れるようになりました。(GH 5945)pd.stats.moments.rolling_varは、数値安定性を向上させるためにウェルフォード法を使用するようになりました(GH 6817)。pd.expanding_applyおよびpd.rolling_applyは、funcに渡されるargsおよびkwargsを受け取るようになりました(GH 6289)。
DataFrame.rank()にパーセンテージランクオプションが追加されました(GH 5971)。Series.rank()にパーセンテージランクオプションが追加されました(GH 5971)。Series.rank()とDataFrame.rank()は、ギャップのないランクのためのmethod='dense'を受け入れるようになりました(GH 6514)。xlwtでの
encodingのサポート(GH 3710)Blockクラスをリファクタリングし、アイテム処理での重複を避けるために
Block.items属性を削除しました(GH 6745、GH 6988)。テストステートメントが特殊なassertを使用するように更新されました(GH 6175)。
パフォーマンス#
DatetimeIndexをDatetimeConverterを使用して浮動小数点序数に変換する際のパフォーマンスが向上しました(GH 6636)。DataFrame.shiftのパフォーマンス向上(GH 5609)MultiIndexed Seriesへのインデックス付けのパフォーマンス向上(GH 5567)。
単一dtypeのインデックス付けにおけるパフォーマンス改善(GH 6484)。
特定のオフセット(例:MonthEnd、BusinessMonthEnd)を持つDataFrameの構築パフォーマンスを向上させるために、誤ったキャッシュを削除しました(GH 6479)。
CustomBusinessDayのパフォーマンス改善(GH 6584)イテラブルから指定された行数を読み取る際の
DataFrame.from_recordsのパフォーマンス向上(GH 6700)。整数dtypesのtimedelta変換におけるパフォーマンス改善(GH 6754)
互換性のあるpickleのパフォーマンス向上(GH 6899)
take_2dを最適化することで、特定の再インデックス操作のパフォーマンスを向上させる(GH 6749)。GroupBy.count()がCythonで実装され、多数のグループで大幅に高速化されました(GH 7016)。
実験的#
0.14.0では実験的な変更はありません。
バグ修正#
インデックスがデータと一致しない場合のSeries ValueErrorのバグ(GH 6532)
HDFStoreテーブル形式でMultiIndexがサポートされていないことによるセグメンテーションフォールトを防止する(GH 1848)。
pd.DataFrame.sort_indexで、ascending=Falseの場合にマージソートが安定しないバグ(GH 6399)。引数に先行ゼロがある場合の
pd.tseries.frequencies.to_offsetのバグ(GH 6391)。浅いクローン/tarballからのインストールを伴う開発バージョンでのバージョン文字列生成のバグ(GH 6127)。
現在の年の
Timestamp/to_datetimeにおけるタイムゾーン解析の不整合(GH 5958)。大きな式で型プロモーションが失敗する
evalのバグ(GH 6205)。inplace=Trueでのinterpolateのバグ(GH 6281)HDFStore.removeはstartとstopを処理するようになりました(GH 6177)。HDFStore.select_as_multipleはselectと同様にstartとstopを処理します(GH 6177)。HDFStore.select_as_coordinatesおよびselect_columnは、フィルタリングを生成するwhere句で動作します(GH 6177)。非一意なインデックスの結合における回帰(GH 6329)
単一関数と混合型フレームを持つgroupby
aggに関する問題(GH 6337)DataFrame.replace()で非boolのto_replace引数を渡した場合のバグ(GH 6332)MultiIndexの割り当てにおいて異なるレベルでアラインしようとすると発生するエラーを修正(GH 3738)。
ブールインデックス付けによる複合dtypeの設定のバグ(GH 6345)
非単調なDatetimeIndexが与えられた場合にTimeGrouper/resampleが不正な結果を返すバグ(GH 4161)。
TimeGrouper/resampleにおけるインデックス名伝播のバグ(GH 4161)
TimeGrouperは、他のグルーパとより互換性のあるAPIを持つようになりました(例:
groupsが欠落していました)(GH 3881)。対象列の順序に依存するTimeGrouperでの複数グループ化のバグ(GH 6764)
'&'のようなトークンを含む文字列を解析する際のpd.evalのバグ(GH 6351)。整数0で割ったときにPanel内の
-infの配置を正しく処理するバグ(GH 6178)DataFrame.shiftにaxis=1を指定するとエラーが発生していました(GH 6371)。リリース時までクリップボードテストを無効化(ローカルでは
nosetests -A disabledで実行)(GH 6048)。DataFrame.replace()で、置換対象の値に含まれていないキーを持つネストされたdictを渡した場合のバグ(GH 6342)。str.matchがnaフラグを無視していました(GH 6609)。統合されていない重複列のあるtakeのバグ(GH 6240)。
dtypesを変更するinterpolateのバグ(GH 6290)
Series.getのバグ。バグのあるアクセス方法を使用していた (GH 6383)hdfstoreクエリの形式におけるバグ:
where=[('date', '>=', datetime(2013,1,1)), ('date', '<=', datetime(2014,1,1))](GH 6313)重複するインデックスを持つ
DataFrame.dropnaのバグ (GH 6355)0.12以降、埋め込みリストのようなものを含む連結getitemインデックスでのリグレッション (GH 6394)
NaNを含む
Float64Indexが正しく比較されない (GH 6401)@文字を含む文字列を持つeval/query式が動作するようになりました (GH 6366)。一部のNaN値を持つ
methodを指定した場合のSeries.reindexのバグで、動作が不安定でした (リサンプルで確認) (GH 6418)DataFrame.replace()のバグで、ネストされた辞書が誤って辞書キーと値の順序に依存していた (GH 5338)。空のオブジェクトとの連結におけるパフォーマンスの問題 (GH 3259)
NaN値を持つIndexオブジェクトにおけるsym_diffのソートを明確化 (GH 6444)入力として
DatetimeIndexを持つMultiIndex.from_productにおけるリグレッション (GH 6439)デフォルト以外のインデックスが渡された場合の
str.extractのバグ (GH 6348)pat=Noneとn=1が渡された場合のstr.splitのバグ (GH 6466)"F-F_Momentum_Factor"とdata_source="famafrench"が渡された場合のio.data.DataReaderのバグ (GH 6460)timedelta64[ns]シリーズのsumのバグ (GH 6462)タイムゾーンと特定のオフセットを含む
resampleのバグ (GH 6397)Seriesの重複するインデックスを持つ
iat/ilocのバグ (GH 6493)read_htmlのバグで、NaNが誤ってテキストの欠損値を示すために使用されていた。pandasの他の部分との整合性のために空文字列を使用すべきです (GH 5129)。read_htmlテストのバグで、リダイレクトされた無効なURLがテストを失敗させる原因となっていた (GH 6445)。一意でないインデックスで
.locを使用する多軸インデックスのバグ (GH 6504)DataFrameの列軸全体にわたるスライスインデックスで_ref_locs破損を引き起こすバグ (GH 6525)
Series作成時のnumpy
datetime64非ns dtypeの扱いにおける0.13からのリグレッション (GH 6529)set_indexに渡されるMultiIndexesの.names属性が保持されるようになりました (GH 6459)。重複するインデックスと位置合わせ可能なrhsを持つsetitemのバグ (GH 6541)
混合整数インデックスで
.locを使用するsetitemのバグ (GH 6546)pd.read_stataのバグで、間違ったデータ型と欠損値を使用していた (GH 6327)DataFrame.to_stataのバグで、特定のケースでデータ損失につながり、間違ったデータ型と欠損値を使用してエクスポートされる可能性があった (GH 6335)StataWriterは文字列列の欠損値を空文字列に置き換えます (GH 6802)Timestampの加算/減算における不整合な型 (GH 6543)Timestampの加算/減算における頻度保持のバグ (GH 4547)
objectdtypeでSeries.quantileが例外を発生させる (GH 6555)レベルで
nanが削除された場合の.xsのバグ (GH 6574)method='bfill/ffill'およびdatetime64[ns]dtypeを持つfillnaのバグ (GH 6587)混合dtypeを持つSQL書き込みのバグで、データ損失につながる可能性があった (GH 6509)
Series.popのバグ (GH 6600)位置インデクサーが対応する軸の
Int64Indexと一致し、並べ替えが発生しなかった場合のilocインデックスのバグ (GH 6612)limitとvalueが指定された場合のfillnaのバグ列に非文字列名がある場合の
DataFrame.to_stataのバグ (GH 4558)np.compressとの互換性のバグで、(GH 6658)で表面化したSeriesのrhsが位置合わせされていない場合の二項演算のバグ (GH 6681)
DataFrame.to_stataのバグで、nan値を誤って処理し、with_indexキーワード引数を無視していた (GH 6685)均等に割り切れる頻度を使用した場合の、余分なビンを含むリサンプルのバグ (GH 4076)
カスタム関数を渡したときのgroupby集約の一貫性のバグ (GH 6715)
how=Noneでリサンプル頻度が軸の頻度と同じ場合のリサンプルのバグ (GH 5955)空の配列でのダウンキャスティング推論のバグ (GH 6733)
疎なコンテナで
obj.blocksのバグで、同じdtypeの最後のアイテムを除くすべてのアイテムが削除されていた (GH 6748)NaT (NaTType)のアンピクリングのバグ (GH 4606)DataFrame.replace()のバグで、regex=Falseであっても正規表現のメタ文字が正規表現として扱われていた (GH 6777)。32ビットプラットフォームでのtimedelta演算のバグ (GH 6808)
.indexを介して直接tz対応インデックスを設定する際のバグ (GH 6785)expressions.pyのバグで、numexprが算術演算を評価しようとしていた (GH 6762)。
Makefileのバグで、
make cleanでCython生成のCファイルが削除されなかった (GH 6768)HDFStoreから長い文字列を読み取る際のnumpy < 1.7.2とのバグ (GH 6166)DataFrame._reduceのバグで、ブール値でない(0/1)整数がブール値に変換されていた (GH 6806)0.13からのリグレッションで、
fillnaとdatetimeのようなSeriesを伴うもの (GH 6344)タイムゾーンを持つ
DatetimeIndexにnp.timedelta64を追加すると、誤った結果が出力されるバグ (GH 6818)DataFrame.replace()のバグで、置換によってdtypeを変更すると、値の最初の出現のみが置換されていた (GH 6689)Period構築で「MS」の頻度を渡した場合のより良いエラーメッセージ (GH5332)max_rows=NoneでSeriesが1000行以上ある場合のSeries.__unicode__のバグ (GH 6863)groupby.get_groupのバグで、datelikeが常に受け入れられなかった (GH 5267)TimeGrouperによって作成されたgroupBy.get_groupがAttributeErrorを発生させるバグ (GH 6914)DatetimeIndex.tz_localizeとDatetimeIndex.tz_convertがNaTを誤って変換するバグ (GH 5546)NaTに影響を与える算術演算のバグ (GH 6873)Series.str.extractのバグで、単一グループの一致から得られたSeriesがグループ名にリネームされなかったDataFrame.to_csvのバグで、index=Falseを設定するとheaderkwargが無視された (GH 6186)DataFrame.plotとSeries.plotのバグで、同じ軸に繰り返しプロットすると凡例の動作が不一致であった (GH 6678)__finalize__のパッチ適用に関する内部テスト / mergeがfinalizeしないバグ (GH 6923, GH 6927)concatでTextFileReaderを受け入れるようになり、これは一般的なユーザーの慣用句に影響を与えていた (GH 6583)先頭の空白を含むCパーサーのバグ (GH 3374)
delim_whitespace=Trueと\r区切り行を含むCパーサーのバグカラムヘッダーの後に明示的なMultiIndexを持つ行のpythonパーサーのバグ (GH 6893)
Series.rankとDataFrame.rankのバグで、小さな浮動小数点数 (<1e-13) がすべて同じランクを受け取っていた (GH 6886)DataFrame.applyのバグで、*argsまたは**kwargsを使用し、空の結果を返す関数で発生していた (GH 6952)32ビットプラットフォームでのオーバーフロー時のsum/meanのバグ (GH 6915)
Panel.shiftをNDFrame.slice_shiftに移動し、複数のdtypeを尊重するように修正 (GH 6959)DataFrame.plotでsubplots=Trueを有効にすると単一列の場合にTypeErrorが発生し、Series.plotでAttributeErrorが発生するバグ (GH 6951)DataFrame.plotのバグで、subplotsとkind=scatterを有効にすると不要な軸が描画されていた (GH 6951)非utf-8エンコーディングのファイルシステムから
read_csvを実行する際のバグ (GH 6807)設定/位置合わせ時の
ilocのバグ (GH 6766)get_dummiesがunicode値とプレフィックスで呼び出されたときにUnicodeEncodeErrorを引き起こすバグ (GH 6885)
周波数付き時系列プロットカーソル表示のバグ (GH 5453)
Float64Indexを使用する際にgroupby.plotで表面化したバグ (GH 7025)Yahooからオプションデータをダウンロードできない場合にテストが失敗するのを止めました (GH 7034)
parallel_coordinatesとradvizのバグで、クラス列の並べ替えにより色/クラスの不一致が発生する可能性があった (GH 6956)radvizとandrews_curvesのバグで、「color」の複数の値がプロットメソッドに渡されていた (GH 6956)Float64Index.isin()のバグで、nansを含むと、インデックスがすべてのものを含んでいると主張していた (GH 7066)。DataFrame.boxplotのバグで、ax引数として渡された軸を使用できなかった (GH 3578)XlsxWriterおよびXlwtWriterの実装におけるバグで、datetime列が時刻なしで書式設定されていた (GH 7075) がプロットメソッドに渡されていたread_fwf()はcolspec内のNoneを通常のpythonスライスのように扱います。colspecにNoneが含まれている場合、行の最初から、または行の終わりまで読み取るようになりました (以前はTypeErrorを発生させていた)。連結インデックスとスライスにおけるキャッシュの一貫性のバグ。
NDFrameに_is_viewプロパティを追加してビューを正しく予測するように修正。xsのis_copyは、実際のコピーである場合のみ (ビューではない場合) マークされるように修正 (GH 7084)dayfirst=Trueを持つ文字列ndarrayからのDatetimeIndex作成のバグ (GH 5917)DatetimeIndexから作成されたMultiIndex.from_arraysがfreqとtzを保持しないバグ (GH 7090)MultiIndexにPeriodIndexが含まれている場合にunstackがValueErrorを発生させるバグ (GH 4342)boxplotとhistが不要な軸を描画するバグ (GH 6769)範囲外のインデクサーに対する
groupby.nth()におけるリグレッション (GH 6621)datetime値を持つ
quantileのバグ (GH 6965)Dataframe.set_index,reindex,pivotがDatetimeIndexとPeriodIndexの属性を保持しないバグ (GH 3950, GH 5878, GH 6631)MultiIndex.get_level_valuesがDatetimeIndexとPeriodIndexの属性を保持しないバグ (GH 7092)Groupbyがtzを保持しないバグ (GH 3950)PeriodIndexの部分文字列スライスにおけるバグ (GH 6716)切り詰められたSeriesまたはDataFrameのHTML reprで、
large_reprが「info」に設定されている場合にクラス名が表示されないバグ (GH 7105)DatetimeIndexでfreqを指定すると、渡された値が短すぎる場合にValueErrorが発生するバグ (GH 7098)info表現がdisplay.max_info_columns設定を尊重しないバグを修正しました(GH 6939)。PeriodIndexの文字列スライスで範囲外の値を持つバグ (GH 5407)大きなテーブルのリサイズ時のハッシュテーブル実装/ファクトライザーにおけるメモリエラーを修正 (GH 7157)
0次元オブジェクト配列に適用された場合の
isnullのバグ (GH 7176)query/evalのバグで、グローバル定数が正しくルックアップされなかった (GH 7178)ilocと多軸タプルインデクサーで、範囲外の位置リストインデクサーを認識する際のバグ (GH 7189)反転した演算を持つ式の評価のバグで、Series-DataFrame演算で表示されていた (GH 7198, GH 7192)
2次元を超えるndimとMultiIndexを持つ多軸インデックスのバグ (GH 7199)
無効なeval/query操作がスタックを使い果たすバグを修正 (GH 5198)
貢献者#
このリリースには合計94人がパッチを貢献しました。名前の横に「+」がある人は初めてパッチを貢献しました。
Acanthostega +
Adam Marcus +
Alex Gaudio
アレックス・ロスバーグ
AllenDowney +
Andrew Rosenfeld +
アンディ・ヘイデン
Antoine Mazières +
Benedikt Sauer
Brad Buran
クリストファー・ウィーラン
Clark Fitzgerald
DSM
Dale Jung
Dan Allan
Dan Birken
Daniel Waeber
David Jung +
David Stephens +
Douglas McNeil
Garrett Drapala
Gouthaman Balaraman +
Guillaume Poulin +
Jacob Howard +
ジェイコブ・シャアー
Jason Sexauer +
ジェフ・リーバック
Jeff Tratner
Jeffrey Starr +
John David Reaver +
John McNamara
John W. O’Brien
Jonathan Chambers
Joris Van den Bossche
Julia Evans
Júlio +
K.-Michael Aye
Katie Atkinson +
ケルシー・ジョーダル
Kevin Sheppard +
Matt Wittmann +
Matthias Kuhn +
Max Grender-Jones +
Michael E. Gruen +
Mike Kelly
Nipun Batra +
Noah Spies +
PKEuS
Patrick O’Keeffe
Phillip Cloud
Pietro Battiston +
Randy Carnevale +
Robert Gibboni +
スキッパー・シーボールド
SplashDance +
Stephan Hoyer +
Tim Cera +
Tobias Brandt
Todd Jennings +
Tom Augspurger
TomAugspurger
ヤロスラフ・ハルチェンコ
agijsberts +
akittredge
ankostis +
anomrake
anton-d +
bashtage +
benjamin +
bwignall
cgohlke +
chebee7i +
clham +
danielballan
hshimizu77 +
hugo +
immerrr
ischwabacher +
jaimefrio +
jreback
jsexauer +
kdiether +
michaelws +
mikebailey +
ojdo +
onesandzeroes +
phaebz +
ribonoous +
ロックg
sinhrks +
unutbu
westurner
y-p
zach powers