In [1]: import pandas as pd
- タイタニック号のデータ
このチュートリアルでは、CSV として保存されているタイタニック号のデータセットを使用します。データは次のデータ列で構成されています。
PassengerId: 各乗客のID。
Survived: 乗客が生存したかどうかを示す。生存した場合は
0、生存しなかった場合は1。Pclass: 3つのチケットクラスのうちの1つ: Class
1、Class2、Class3。Name: 乗客の名前。
Sex: 乗客の性別。
Age: 乗客の年齢 (年単位)。
SibSp: 乗船していた兄弟姉妹または配偶者の数。
Parch: 乗船していた両親または子供の数。
Ticket: 乗客のチケット番号。
Fare: 運賃を示す。
Cabin: 乗客の客室番号。
Embarked: 乗船港。
In [2]: titanic = pd.read_csv("data/titanic.csv") In [3]: titanic.head() Out[3]: PassengerId Survived Pclass ... Fare Cabin Embarked 0 1 0 3 ... 7.2500 NaN S 1 2 1 1 ... 71.2833 C85 C 2 3 1 3 ... 7.9250 NaN S 3 4 1 1 ... 53.1000 C123 S 4 5 0 3 ... 8.0500 NaN S [5 rows x 12 columns]
-
大気質データ
このチュートリアルでは、OpenAQ から提供され、py-openaq パッケージを使用している、\(NO_2\) と 2.5マイクロメートル未満の粒子状物質に関する大気質データを使用します。
air_quality_long.csvデータセットは、パリ、アントワープ、ロンドンの測定ステーション FR04014、BETR801、London Westminster について、それぞれ \(NO_2\) と \(PM_{25}\) の値を提供します。大気質データセットには以下の列があります
city: センサーが使用されている都市、パリ、アントワープ、またはロンドン
country: センサーが使用されている国、FR、BE、またはGB
location: センサーのID、FR04014、BETR801、またはLondon Westminster
parameter: センサーによって測定されたパラメータ、\(NO_2\) または粒子状物質
value: 測定値
unit: 測定されたパラメータの単位、この場合は「µg/m³」
そして
DataFrameのインデックスはdatetimeで、測定の datetime です。生データへ注
大気質データは、各観測値が別々の行に、各変数がデータテーブルの別々の列にある、いわゆる ロングフォーマット のデータ表現で提供されます。ロング/ナローフォーマットは、tidyデータフォーマット としても知られています。
In [4]: air_quality = pd.read_csv( ...: "data/air_quality_long.csv", index_col="date.utc", parse_dates=True ...: ) ...: In [5]: air_quality.head() Out[5]: city country location parameter value unit date.utc 2019-06-18 06:00:00+00:00 Antwerpen BE BETR801 pm25 18.0 µg/m³ 2019-06-17 08:00:00+00:00 Antwerpen BE BETR801 pm25 6.5 µg/m³ 2019-06-17 07:00:00+00:00 Antwerpen BE BETR801 pm25 18.5 µg/m³ 2019-06-17 06:00:00+00:00 Antwerpen BE BETR801 pm25 16.0 µg/m³ 2019-06-17 05:00:00+00:00 Antwerpen BE BETR801 pm25 7.5 µg/m³
テーブルのレイアウトを再形成する方法#
テーブルの行を並べ替える#
タイタニック号のデータを乗客の年齢順に並べ替えたい。
In [6]: titanic.sort_values(by="Age").head() Out[6]: PassengerId Survived Pclass ... Fare Cabin Embarked 803 804 1 3 ... 8.5167 NaN C 755 756 1 2 ... 14.5000 NaN S 644 645 1 3 ... 19.2583 NaN C 469 470 1 3 ... 19.2583 NaN C 78 79 1 2 ... 29.0000 NaN S [5 rows x 12 columns]
タイタニック号のデータを客室クラスと年齢の降順で並べ替えたい。
In [7]: titanic.sort_values(by=['Pclass', 'Age'], ascending=False).head() Out[7]: PassengerId Survived Pclass ... Fare Cabin Embarked 851 852 0 3 ... 7.7750 NaN S 116 117 0 3 ... 7.7500 NaN Q 280 281 0 3 ... 7.7500 NaN Q 483 484 1 3 ... 9.5875 NaN S 326 327 0 3 ... 6.2375 NaN S [5 rows x 12 columns]
DataFrame.sort_values()を使用すると、テーブルの行が定義された列に基づいて並べ替えられます。インデックスは行の順序に従います。
テーブルの並べ替えに関する詳細は、ユーザーガイドのデータの並べ替えセクションに記載されています。
ロング形式からワイド形式へのテーブル形式変換#
大気質データセットの小さなサブセットを使用してみましょう。私たちは \(NO_2\) データに焦点を当て、各場所の最初の2つの測定値のみを使用します (つまり、各グループの先頭)。データのサブセットは no2_subset と呼ばれます。
# filter for no2 data only
In [8]: no2 = air_quality[air_quality["parameter"] == "no2"]
# use 2 measurements (head) for each location (groupby)
In [9]: no2_subset = no2.sort_index().groupby(["location"]).head(2)
In [10]: no2_subset
Out[10]:
city country ... value unit
date.utc ...
2019-04-09 01:00:00+00:00 Antwerpen BE ... 22.5 µg/m³
2019-04-09 01:00:00+00:00 Paris FR ... 24.4 µg/m³
2019-04-09 02:00:00+00:00 London GB ... 67.0 µg/m³
2019-04-09 02:00:00+00:00 Antwerpen BE ... 53.5 µg/m³
2019-04-09 02:00:00+00:00 Paris FR ... 27.4 µg/m³
2019-04-09 03:00:00+00:00 London GB ... 67.0 µg/m³
[6 rows x 6 columns]

3つのステーションの値を、隣接する別々の列として表示したい。
In [11]: no2_subset.pivot(columns="location", values="value") Out[11]: location BETR801 FR04014 London Westminster date.utc 2019-04-09 01:00:00+00:00 22.5 24.4 NaN 2019-04-09 02:00:00+00:00 53.5 27.4 67.0 2019-04-09 03:00:00+00:00 NaN NaN 67.0
pivot()関数はデータを純粋に再形成するものです。各インデックス/列の組み合わせに対して単一の値が必要です。
pandasは複数の列のプロットを標準でサポートしているため(プロットチュートリアルを参照)、ロングからワイドテーブル形式への変換により、異なる時系列を同時にプロットできるようになります。
In [12]: no2.head()
Out[12]:
city country location parameter value unit
date.utc
2019-06-21 00:00:00+00:00 Paris FR FR04014 no2 20.0 µg/m³
2019-06-20 23:00:00+00:00 Paris FR FR04014 no2 21.8 µg/m³
2019-06-20 22:00:00+00:00 Paris FR FR04014 no2 26.5 µg/m³
2019-06-20 21:00:00+00:00 Paris FR FR04014 no2 24.9 µg/m³
2019-06-20 20:00:00+00:00 Paris FR FR04014 no2 21.4 µg/m³
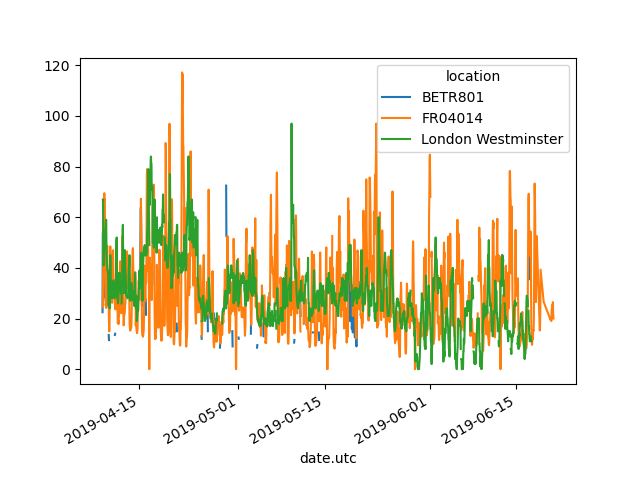
In [13]: no2.pivot(columns="location", values="value").plot()
Out[13]: <Axes: xlabel='date.utc'>
注
index パラメータが定義されていない場合、既存のインデックス(行ラベル)が使用されます。
pivot() の詳細については、ユーザーガイドのDataFrameオブジェクトのピボットセクションを参照してください。
ピボットテーブル#

各観測所の\(NO_2\)および\(PM_{2.5}\)の平均濃度をテーブル形式で知りたい。
In [14]: air_quality.pivot_table( ....: values="value", index="location", columns="parameter", aggfunc="mean" ....: ) ....: Out[14]: parameter no2 pm25 location BETR801 26.950920 23.169492 FR04014 29.374284 NaN London Westminster 29.740050 13.443568
pivot()の場合、データは単に並べ替えられます。複数の値を集計する必要がある場合(この特定のケースでは、異なるタイムステップでの値)、pivot_table()を使用して、これらの値を結合する方法(例:平均)の集計関数を提供できます。
ピボットテーブルはスプレッドシートソフトウェアでよく知られた概念です。各変数に行/列の余白(小計)に関心がある場合は、margins パラメータを True に設定します。
In [15]: air_quality.pivot_table(
....: values="value",
....: index="location",
....: columns="parameter",
....: aggfunc="mean",
....: margins=True,
....: )
....:
Out[15]:
parameter no2 pm25 All
location
BETR801 26.950920 23.169492 24.982353
FR04014 29.374284 NaN 29.374284
London Westminster 29.740050 13.443568 21.491708
All 29.430316 14.386849 24.222743
pivot_table() の詳細については、ユーザーガイドのピボットテーブルのセクションを参照してください。
注
もし疑問に思われるのであれば、pivot_table() は実際には groupby() に直接関連しています。同じ結果は、parameter と location の両方でグループ化することによって導き出すことができます。
air_quality.groupby(["parameter", "location"])[["value"]].mean()
ワイド形式からロング形式への変換#
前のセクションで作成したワイド形式のテーブルから再度始め、reset_index() を使用して新しいインデックスを DataFrame に追加します。
In [16]: no2_pivoted = no2.pivot(columns="location", values="value").reset_index()
In [17]: no2_pivoted.head()
Out[17]:
location date.utc BETR801 FR04014 London Westminster
0 2019-04-09 01:00:00+00:00 22.5 24.4 NaN
1 2019-04-09 02:00:00+00:00 53.5 27.4 67.0
2 2019-04-09 03:00:00+00:00 54.5 34.2 67.0
3 2019-04-09 04:00:00+00:00 34.5 48.5 41.0
4 2019-04-09 05:00:00+00:00 46.5 59.5 41.0

すべての空気質 \(NO_2\) 測定値を単一の列(ロング形式)に集約したい。
In [18]: no_2 = no2_pivoted.melt(id_vars="date.utc") In [19]: no_2.head() Out[19]: date.utc location value 0 2019-04-09 01:00:00+00:00 BETR801 22.5 1 2019-04-09 02:00:00+00:00 BETR801 53.5 2 2019-04-09 03:00:00+00:00 BETR801 54.5 3 2019-04-09 04:00:00+00:00 BETR801 34.5 4 2019-04-09 05:00:00+00:00 BETR801 46.5
DataFrameのpandas.melt()メソッドは、データテーブルをワイド形式からロング形式に変換します。列ヘッダーは新しく作成された列の変数名になります。
この解決策は、pandas.melt() を適用する方法の短縮版です。id_vars で言及されていないすべての列を2つの列に「melt」します。つまり、列ヘッダー名を持つ列と、値自体を持つ列です。後者の列には、デフォルトで value という名前が付けられます。
pandas.melt() に渡されるパラメータは、より詳細に定義できます。
In [20]: no_2 = no2_pivoted.melt(
....: id_vars="date.utc",
....: value_vars=["BETR801", "FR04014", "London Westminster"],
....: value_name="NO_2",
....: var_name="id_location",
....: )
....:
In [21]: no_2.head()
Out[21]:
date.utc id_location NO_2
0 2019-04-09 01:00:00+00:00 BETR801 22.5
1 2019-04-09 02:00:00+00:00 BETR801 53.5
2 2019-04-09 03:00:00+00:00 BETR801 54.5
3 2019-04-09 04:00:00+00:00 BETR801 34.5
4 2019-04-09 05:00:00+00:00 BETR801 46.5
追加のパラメータは以下の効果を持ちます
value_varsは、どの列を「溶融」するかを定義します。value_nameは、デフォルトの列名valueの代わりに、値列にカスタムの列名を提供します。var_nameは、列ヘッダー名を収集する列にカスタム列名を提供します。そうでない場合は、インデックス名またはデフォルトのvariableを取ります。
したがって、引数 value_name と var_name は、生成された2つの列に対するユーザー定義の名前です。溶融する列は id_vars と value_vars によって定義されます。
pandas.melt() を使用したワイド形式からロング形式への変換は、ユーザーガイドのmeltによる再形成のセクションで説明されています。
覚えておいてください
1つ以上の列によるソートは
sort_valuesでサポートされています。pivot関数は純粋にデータの再構築であり、pivot_tableは集計をサポートします。pivotの逆(ロング形式からワイド形式)はmelt(ワイド形式からロング形式)です。
完全な概要は、ユーザーガイドの再形成とピボットのページで利用できます。