スプレッドシートとの比較#
多くの潜在的な pandas ユーザーは、Excel のようなスプレッドシートプログラムにある程度の知識があるため、このページでは、さまざまなスプレッドシート操作を pandas を使用してどのように実行するかについていくつかの例を提供することを目的としています。このページでは Excel の用語を使用し、ドキュメントにリンクしますが、Google スプレッドシート、LibreOffice Calc、Apple Numbers、およびその他の Excel 互換スプレッドシートソフトウェアでも同様/類似しています。
pandas を初めて使用する場合は、最初に10 Minutes to pandas を読んで、ライブラリに慣れておくことをお勧めします。
慣例に従い、pandas と NumPy を次のようにインポートします
In [1]: import pandas as pd
In [2]: import numpy as np
データ構造#
一般用語の翻訳#
pandas |
Excel |
|---|---|
|
ワークシート |
|
列 |
|
行見出し |
行 |
行 |
|
空のセル |
DataFrame#
pandas の DataFrame は Excel のワークシートに似ています。Excel のブックが複数のワークシートを含むことができるのに対し、pandas の DataFrame は独立して存在します。
Series#
Series は DataFrame の 1 列を表すデータ構造です。Series を操作することは、スプレッドシートの列を参照することに似ています。
Index#
すべての DataFrame および Series には Index があり、これはデータの*行*のラベルです。pandas では、インデックスが指定されない場合、デフォルトで RangeIndex が使用されます(最初の行 = 0、2番目の行 = 1、など)。これはスプレッドシートの行見出し/番号に似ています。
pandas では、インデックスを1つ(または複数)の一意の値に設定できます。これは、ワークシートで行識別子として使用される列を持つことに似ています。ほとんどのスプレッドシートとは異なり、これらの Index 値は実際に行を参照するために使用できます。(Excel の構造化参照でもこれが可能であることに注意してください。)たとえば、スプレッドシートでは、最初の行を A1:Z1 として参照しますが、pandas では populations.loc['Chicago'] を使用できます。
インデックス値も永続的であるため、DataFrame の行を並べ替えても、特定の行のラベルは変更されません。
Index を効果的に使用する方法については、インデックス作成のドキュメントを参照してください。
コピーとインプレース操作#
ほとんどの pandas 操作は、Series/DataFrame のコピーを返します。変更を「適用」するには、新しい変数に代入するか
sorted_df = df.sort_values("col1")
または元の変数を上書きする必要があります
df = df.sort_values("col1")
注
いくつかのメソッドでは inplace=True または copy=False キーワード引数が利用できます
df.replace(5, inplace=True)
replace を含むごく一部のメソッドを除き、ほとんどのメソッド (dropna など) で inplace と copy を非推奨にして削除することについて活発な議論が行われています。これらのキーワードは、Copy-on-Write のコンテキストではもはや必要ありません。提案はこちらで確認できます。
データ入出力#
値からのDataFrameの構築#
スプレッドシートでは、値をセルに直接入力できます。
pandas の DataFrame はさまざまな方法で構築できますが、少数の値の場合は、Python 辞書として指定するのが便利なことがよくあります。この場合、キーは列名、値はデータです。
In [3]: df = pd.DataFrame({"x": [1, 3, 5], "y": [2, 4, 6]})
In [4]: df
Out[4]:
x y
0 1 2
1 3 4
2 5 6
外部データの読み込み#
Excel と pandas の両方で、さまざまなソースからさまざまな形式のデータをインポートできます。
CSV#
pandas のテストデータセットである tips データセット(CSV ファイル)を読み込んで表示してみましょう。Excel では、CSV をダウンロードして開きます。pandas では、CSV ファイルの URL またはローカルパスを read_csv() に渡します。
In [5]: url = (
...: "https://raw.githubusercontent.com/pandas-dev"
...: "/pandas/main/pandas/tests/io/data/csv/tips.csv"
...: )
...:
In [6]: tips = pd.read_csv(url)
In [7]: tips
Out[7]:
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
.. ... ... ... ... ... ... ...
239 29.03 5.92 Male No Sat Dinner 3
240 27.18 2.00 Female Yes Sat Dinner 2
241 22.67 2.00 Male Yes Sat Dinner 2
242 17.82 1.75 Male No Sat Dinner 2
243 18.78 3.00 Female No Thur Dinner 2
[244 rows x 7 columns]
Excel のテキストインポートウィザードと同様に、read_csv はデータをどのように解析するかを指定する多くのパラメーターを受け取ることができます。たとえば、データがタブ区切りで列名がなかった場合、pandas のコマンドは次のようになります。
tips = pd.read_csv("tips.csv", sep="\t", header=None)
# alternatively, read_table is an alias to read_csv with tab delimiter
tips = pd.read_table("tips.csv", header=None)
Excelファイル#
Excel は、さまざまな Excel ファイル形式をダブルクリックするか、開くメニューを使用して開きます。pandas では、Excel ファイルの読み書きのための特殊なメソッドを使用します。
まず、上記の例の tips データフレームに基づいて新しい Excel ファイルを作成してみましょう
tips.to_excel("./tips.xlsx")
後で tips.xlsx ファイルのデータにアクセスしたい場合は、次のコマンドを使用してモジュールに読み込むことができます。
tips_df = pd.read_excel("./tips.xlsx", index_col=0)
pandas を使用して Excel ファイルを読み込みました!
出力の制限#
スプレッドシートプログラムは一度に1画面分のデータしか表示せず、スクロールできるので、出力制限の必要はあまりありません。pandas では、DataFrame の表示方法を制御するために、もう少し考える必要があります。
デフォルトでは、pandas は大きな DataFrame の出力を、最初と最後の行を表示するように切り詰めます。これは、pandas のオプションを変更するか、DataFrame.head() または DataFrame.tail() を使用することでオーバーライドできます。
In [8]: tips.head(5)
Out[8]:
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
データのエクスポート#
デフォルトでは、デスクトップスプレッドシートソフトウェアはそれぞれのファイル形式(.xlsx、.ods など)で保存します。しかし、他のファイル形式で保存することもできます。
pandasはExcelファイル、CSV、またはその他多数の形式を作成できます。
データ操作#
列の操作#
スプレッドシートでは、数式は個々のセルで作成され、その後ドラッグして他のセルに適用することで、他の列の計算が行われることがよくあります。pandas では、列全体に対して直接操作を実行できます。
pandas は、DataFrame 内の個々の Series を指定することで、ベクトル化された操作を提供します。新しい列も同様の方法で割り当てることができます。DataFrame.drop() メソッドは、DataFrame から列を削除します。
In [9]: tips["total_bill"] = tips["total_bill"] - 2
In [10]: tips["new_bill"] = tips["total_bill"] / 2
In [11]: tips
Out[11]:
total_bill tip sex smoker day time size new_bill
0 14.99 1.01 Female No Sun Dinner 2 7.495
1 8.34 1.66 Male No Sun Dinner 3 4.170
2 19.01 3.50 Male No Sun Dinner 3 9.505
3 21.68 3.31 Male No Sun Dinner 2 10.840
4 22.59 3.61 Female No Sun Dinner 4 11.295
.. ... ... ... ... ... ... ... ...
239 27.03 5.92 Male No Sat Dinner 3 13.515
240 25.18 2.00 Female Yes Sat Dinner 2 12.590
241 20.67 2.00 Male Yes Sat Dinner 2 10.335
242 15.82 1.75 Male No Sat Dinner 2 7.910
243 16.78 3.00 Female No Thur Dinner 2 8.390
[244 rows x 8 columns]
In [12]: tips = tips.drop("new_bill", axis=1)
この引き算をセルごとに指示する必要はなく、pandas が処理してくれることに注意してください。既存の列から新しい列を作成する方法を参照してください。
フィルタリング#
Excel では、フィルタリングはグラフィカルなメニューから行われます。
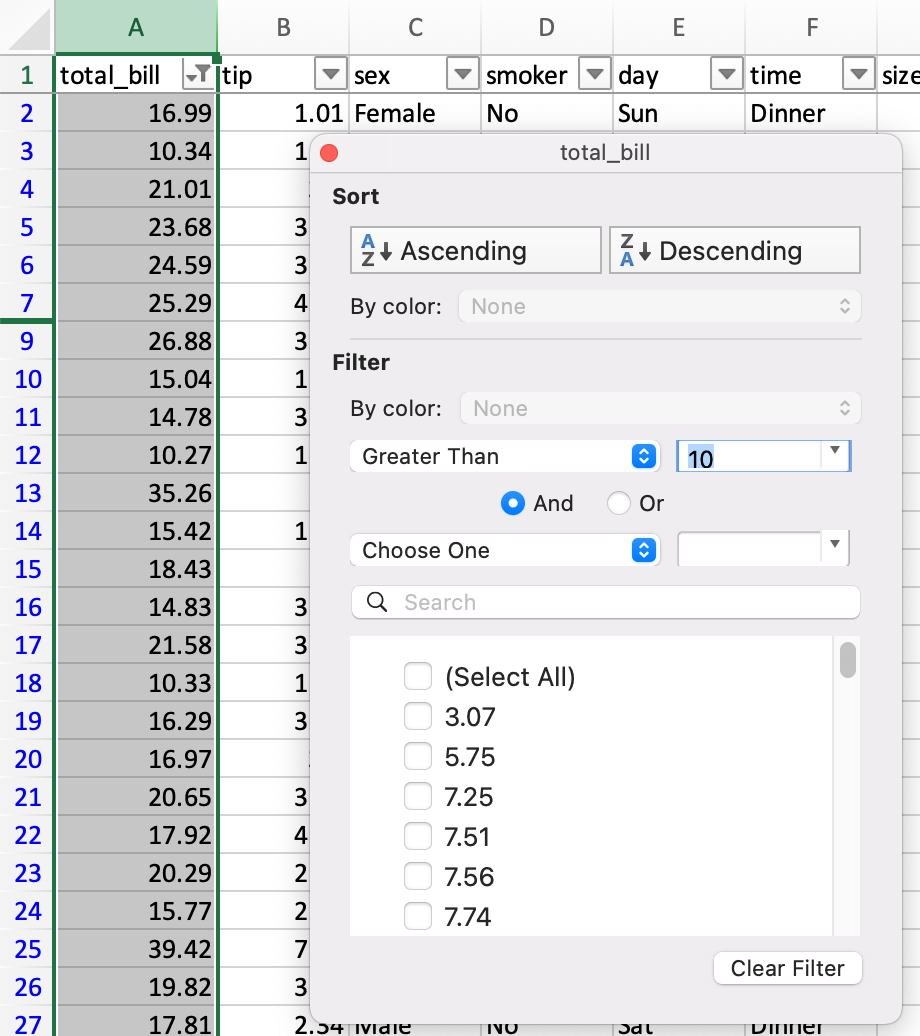
DataFrame は複数の方法でフィルタリングできますが、最も直感的な方法はブールインデックスを使用することです。
In [13]: tips[tips["total_bill"] > 10]
Out[13]:
total_bill tip sex smoker day time size
0 14.99 1.01 Female No Sun Dinner 2
2 19.01 3.50 Male No Sun Dinner 3
3 21.68 3.31 Male No Sun Dinner 2
4 22.59 3.61 Female No Sun Dinner 4
5 23.29 4.71 Male No Sun Dinner 4
.. ... ... ... ... ... ... ...
239 27.03 5.92 Male No Sat Dinner 3
240 25.18 2.00 Female Yes Sat Dinner 2
241 20.67 2.00 Male Yes Sat Dinner 2
242 15.82 1.75 Male No Sat Dinner 2
243 16.78 3.00 Female No Thur Dinner 2
[204 rows x 7 columns]
上記のステートメントは、True/False オブジェクトの Series を DataFrame に渡すだけで、True のすべての行が返されます。
In [14]: is_dinner = tips["time"] == "Dinner"
In [15]: is_dinner
Out[15]:
0 True
1 True
2 True
3 True
4 True
...
239 True
240 True
241 True
242 True
243 True
Name: time, Length: 244, dtype: bool
In [16]: is_dinner.value_counts()
Out[16]:
time
True 176
False 68
Name: count, dtype: int64
In [17]: tips[is_dinner]
Out[17]:
total_bill tip sex smoker day time size
0 14.99 1.01 Female No Sun Dinner 2
1 8.34 1.66 Male No Sun Dinner 3
2 19.01 3.50 Male No Sun Dinner 3
3 21.68 3.31 Male No Sun Dinner 2
4 22.59 3.61 Female No Sun Dinner 4
.. ... ... ... ... ... ... ...
239 27.03 5.92 Male No Sat Dinner 3
240 25.18 2.00 Female Yes Sat Dinner 2
241 20.67 2.00 Male Yes Sat Dinner 2
242 15.82 1.75 Male No Sat Dinner 2
243 16.78 3.00 Female No Thur Dinner 2
[176 rows x 7 columns]
if/then ロジック#
total_bill が 10 ドル未満かそれ以上かに基づいて、low と high の値を持つ bucket 列を作成したいとしましょう。
スプレッドシートでは、論理比較は条件付き数式で行うことができます。新しい bucket 列のすべてのセルにドラッグされる =IF(A2 < 10, "low", "high") という数式を使用します。
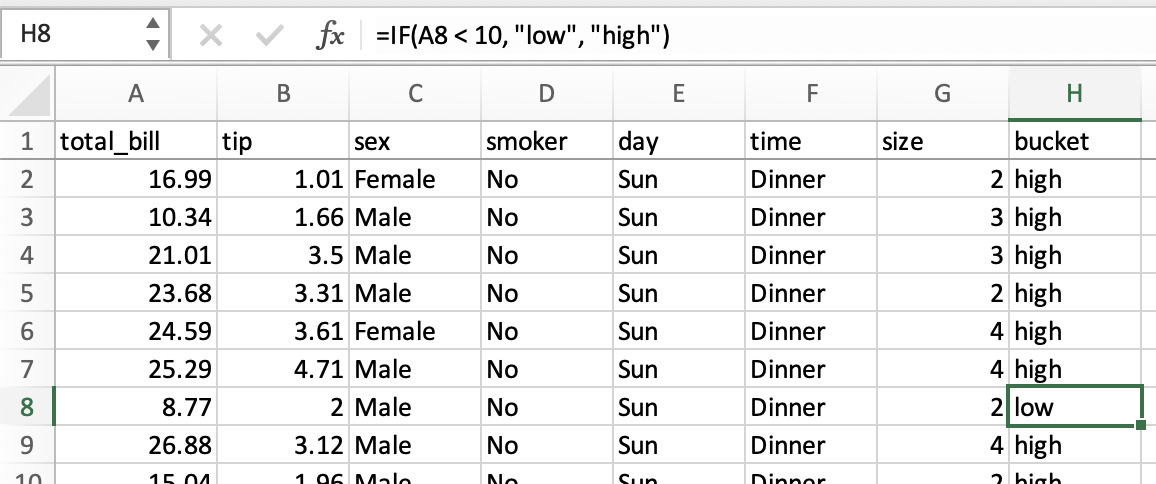
pandas では、numpy の where メソッドを使用して同じ操作を実行できます。
In [18]: tips["bucket"] = np.where(tips["total_bill"] < 10, "low", "high")
In [19]: tips
Out[19]:
total_bill tip sex smoker day time size bucket
0 14.99 1.01 Female No Sun Dinner 2 high
1 8.34 1.66 Male No Sun Dinner 3 low
2 19.01 3.50 Male No Sun Dinner 3 high
3 21.68 3.31 Male No Sun Dinner 2 high
4 22.59 3.61 Female No Sun Dinner 4 high
.. ... ... ... ... ... ... ... ...
239 27.03 5.92 Male No Sat Dinner 3 high
240 25.18 2.00 Female Yes Sat Dinner 2 high
241 20.67 2.00 Male Yes Sat Dinner 2 high
242 15.82 1.75 Male No Sat Dinner 2 high
243 16.78 3.00 Female No Thur Dinner 2 high
[244 rows x 8 columns]
日付機能#
このセクションでは「日付」について言及しますが、タイムスタンプも同様に処理されます。
日付機能は、解析と出力の2つの部分に分けられます。スプレッドシートでは、日付値は通常自動的に解析されますが、必要に応じて DATEVALUE 関数があります。pandas では、プレーンテキストを明示的に datetime オブジェクトに変換する必要があります。これは、CSV から読み込むとき、またはDataFrame 内にあるときに行います。
一旦解析されると、スプレッドシートは日付をデフォルトの形式で表示しますが、形式を変更することもできます。pandas では、日付を計算している間は通常 datetime オブジェクトとして保持したいと思うでしょう。日付の*一部*(年など)を出力するには、スプレッドシートでは日付関数、pandas ではdatetime プロパティを使用します。
スプレッドシートの列 A と B に date1 と date2 が与えられている場合、これらの数式があるかもしれません
列 |
数式 |
|---|---|
|
|
|
|
|
|
|
|
同等の pandas 操作を以下に示します。
In [20]: tips["date1"] = pd.Timestamp("2013-01-15")
In [21]: tips["date2"] = pd.Timestamp("2015-02-15")
In [22]: tips["date1_year"] = tips["date1"].dt.year
In [23]: tips["date2_month"] = tips["date2"].dt.month
In [24]: tips["date1_next"] = tips["date1"] + pd.offsets.MonthBegin()
In [25]: tips["months_between"] = tips["date2"].dt.to_period("M") - tips[
....: "date1"
....: ].dt.to_period("M")
....:
In [26]: tips[
....: ["date1", "date2", "date1_year", "date2_month", "date1_next", "months_between"]
....: ]
....:
Out[26]:
date1 date2 date1_year date2_month date1_next months_between
0 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
1 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
2 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
3 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
4 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
.. ... ... ... ... ... ...
239 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
240 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
241 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
242 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
243 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
[244 rows x 6 columns]
詳細については、時系列 / 日付機能を参照してください。
列の選択#
スプレッドシートでは、目的の列を選択できます
スプレッドシートの列は通常ヘッダー行に名前が付けられているため、列名の変更は最初のセルのテキストを変更するだけです。
同じ操作が pandas では以下のように表現されます。
特定の列を保持する#
In [27]: tips[["sex", "total_bill", "tip"]]
Out[27]:
sex total_bill tip
0 Female 14.99 1.01
1 Male 8.34 1.66
2 Male 19.01 3.50
3 Male 21.68 3.31
4 Female 22.59 3.61
.. ... ... ...
239 Male 27.03 5.92
240 Female 25.18 2.00
241 Male 20.67 2.00
242 Male 15.82 1.75
243 Female 16.78 3.00
[244 rows x 3 columns]
列を削除する#
In [28]: tips.drop("sex", axis=1)
Out[28]:
total_bill tip smoker day time size
0 14.99 1.01 No Sun Dinner 2
1 8.34 1.66 No Sun Dinner 3
2 19.01 3.50 No Sun Dinner 3
3 21.68 3.31 No Sun Dinner 2
4 22.59 3.61 No Sun Dinner 4
.. ... ... ... ... ... ...
239 27.03 5.92 No Sat Dinner 3
240 25.18 2.00 Yes Sat Dinner 2
241 20.67 2.00 Yes Sat Dinner 2
242 15.82 1.75 No Sat Dinner 2
243 16.78 3.00 No Thur Dinner 2
[244 rows x 6 columns]
列名を変更する#
In [29]: tips.rename(columns={"total_bill": "total_bill_2"})
Out[29]:
total_bill_2 tip sex smoker day time size
0 14.99 1.01 Female No Sun Dinner 2
1 8.34 1.66 Male No Sun Dinner 3
2 19.01 3.50 Male No Sun Dinner 3
3 21.68 3.31 Male No Sun Dinner 2
4 22.59 3.61 Female No Sun Dinner 4
.. ... ... ... ... ... ... ...
239 27.03 5.92 Male No Sat Dinner 3
240 25.18 2.00 Female Yes Sat Dinner 2
241 20.67 2.00 Male Yes Sat Dinner 2
242 15.82 1.75 Male No Sat Dinner 2
243 16.78 3.00 Female No Thur Dinner 2
[244 rows x 7 columns]
値による並べ替え#
スプレッドシートでの並べ替えは、並べ替えダイアログを介して行われます。
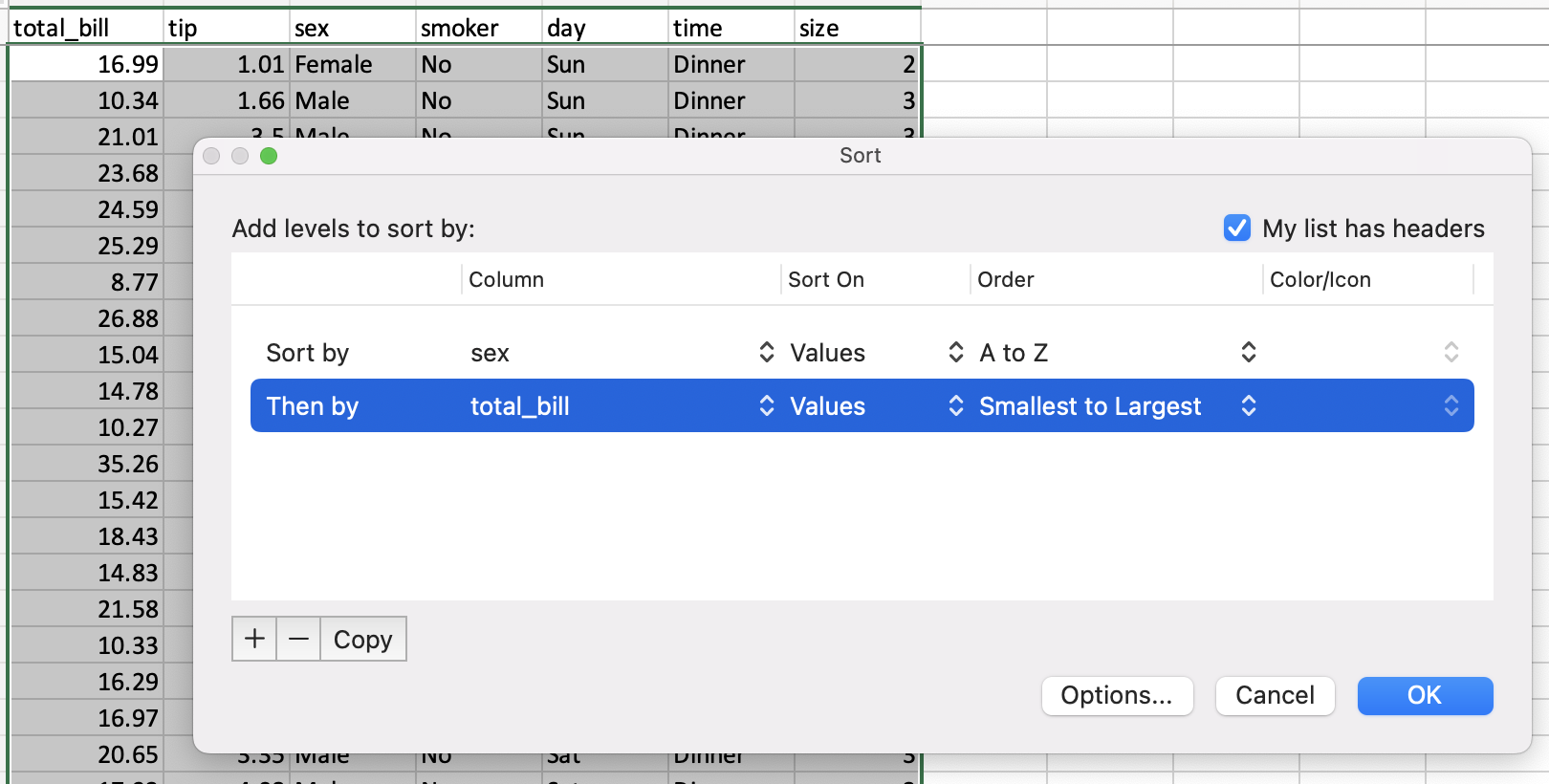
pandas には DataFrame.sort_values() メソッドがあり、これはソートする列のリストを受け取ります。
In [30]: tips = tips.sort_values(["sex", "total_bill"])
In [31]: tips
Out[31]:
total_bill tip sex smoker day time size
67 1.07 1.00 Female Yes Sat Dinner 1
92 3.75 1.00 Female Yes Fri Dinner 2
111 5.25 1.00 Female No Sat Dinner 1
145 6.35 1.50 Female No Thur Lunch 2
135 6.51 1.25 Female No Thur Lunch 2
.. ... ... ... ... ... ... ...
182 43.35 3.50 Male Yes Sun Dinner 3
156 46.17 5.00 Male No Sun Dinner 6
59 46.27 6.73 Male No Sat Dinner 4
212 46.33 9.00 Male No Sat Dinner 4
170 48.81 10.00 Male Yes Sat Dinner 3
[244 rows x 7 columns]
文字列処理#
文字列の長さを調べる#
スプレッドシートでは、テキストの文字数は LEN 関数で調べることができます。これは TRIM 関数と組み合わせて余分な空白を削除するために使用できます。
=LEN(TRIM(A2))
文字文字列の長さは Series.str.len() で調べることができます。Python 3 では、すべての文字列は Unicode 文字列です。len は末尾の空白を含みます。末尾の空白を除外するには len と rstrip を使用します。
In [32]: tips["time"].str.len()
Out[32]:
67 6
92 6
111 6
145 5
135 5
..
182 6
156 6
59 6
212 6
170 6
Name: time, Length: 244, dtype: int64
In [33]: tips["time"].str.rstrip().str.len()
Out[33]:
67 6
92 6
111 6
145 5
135 5
..
182 6
156 6
59 6
212 6
170 6
Name: time, Length: 244, dtype: int64
これには文字列内の複数のスペースが含まれるため、100% 同等ではないことに注意してください。
部分文字列の位置を検索する#
スプレッドシートの FIND 関数は部分文字列の位置を返し、最初の文字は 1 です。
文字列の列内にある文字の位置は、Series.str.find() メソッドで検索できます。find は部分文字列の最初の位置を検索します。部分文字列が見つかった場合、メソッドはその位置を返します。見つからない場合は -1 を返します。Python のインデックスはゼロベースであることに注意してください。
In [34]: tips["sex"].str.find("ale")
Out[34]:
67 3
92 3
111 3
145 3
135 3
..
182 1
156 1
59 1
212 1
170 1
Name: sex, Length: 244, dtype: int64
位置による部分文字列の抽出#
スプレッドシートには、指定された位置から部分文字列を抽出するための MID 数式があります。最初の文字を取得するには
=MID(A2,1,1)
pandas では、[] 記法を使用して、位置によって文字列から部分文字列を抽出できます。Python のインデックスがゼロベースであることに注意してください。
In [35]: tips["sex"].str[0:1]
Out[35]:
67 F
92 F
111 F
145 F
135 F
..
182 M
156 M
59 M
212 M
170 M
Name: sex, Length: 244, dtype: object
N番目の単語の抽出#
Excel では、テキストを分割して特定の列を取得するために区切り位置指定ウィザードを使用するかもしれません。(数式でも可能であることにも注意してください。)
pandas で単語を抽出する最も簡単な方法は、文字列をスペースで分割し、インデックスで単語を参照することです。より強力なアプローチが必要な場合でも、それらが存在することに注意してください。
In [36]: firstlast = pd.DataFrame({"String": ["John Smith", "Jane Cook"]})
In [37]: firstlast["First_Name"] = firstlast["String"].str.split(" ", expand=True)[0]
In [38]: firstlast["Last_Name"] = firstlast["String"].str.rsplit(" ", expand=True)[1]
In [39]: firstlast
Out[39]:
String First_Name Last_Name
0 John Smith John Smith
1 Jane Cook Jane Cook
大文字/小文字の変更#
スプレッドシートには、テキストをそれぞれ大文字、小文字、およびタイトルケースに変換するための UPPER、LOWER、および PROPER 関数が用意されています。
同等の pandas メソッドは、Series.str.upper()、Series.str.lower()、および Series.str.title() です。
In [40]: firstlast = pd.DataFrame({"string": ["John Smith", "Jane Cook"]})
In [41]: firstlast["upper"] = firstlast["string"].str.upper()
In [42]: firstlast["lower"] = firstlast["string"].str.lower()
In [43]: firstlast["title"] = firstlast["string"].str.title()
In [44]: firstlast
Out[44]:
string upper lower title
0 John Smith JOHN SMITH john smith John Smith
1 Jane Cook JANE COOK jane cook Jane Cook
結合#
以下の表は、結合の例で使用されます。
In [45]: df1 = pd.DataFrame({"key": ["A", "B", "C", "D"], "value": np.random.randn(4)})
In [46]: df1
Out[46]:
key value
0 A 0.469112
1 B -0.282863
2 C -1.509059
3 D -1.135632
In [47]: df2 = pd.DataFrame({"key": ["B", "D", "D", "E"], "value": np.random.randn(4)})
In [48]: df2
Out[48]:
key value
0 B 1.212112
1 D -0.173215
2 D 0.119209
3 E -1.044236
Excel では、VLOOKUP を介してテーブルを結合できます。
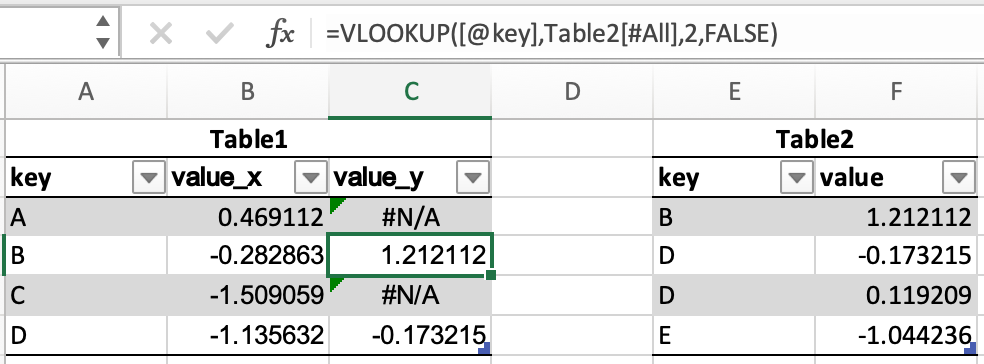
pandas の DataFrame には、同様の機能を提供する merge() メソッドがあります。データは事前にソートする必要はなく、異なる結合タイプは how キーワードを介して実現されます。
In [49]: inner_join = df1.merge(df2, on=["key"], how="inner")
In [50]: inner_join
Out[50]:
key value_x value_y
0 B -0.282863 1.212112
1 D -1.135632 -0.173215
2 D -1.135632 0.119209
In [51]: left_join = df1.merge(df2, on=["key"], how="left")
In [52]: left_join
Out[52]:
key value_x value_y
0 A 0.469112 NaN
1 B -0.282863 1.212112
2 C -1.509059 NaN
3 D -1.135632 -0.173215
4 D -1.135632 0.119209
In [53]: right_join = df1.merge(df2, on=["key"], how="right")
In [54]: right_join
Out[54]:
key value_x value_y
0 B -0.282863 1.212112
1 D -1.135632 -0.173215
2 D -1.135632 0.119209
3 E NaN -1.044236
In [55]: outer_join = df1.merge(df2, on=["key"], how="outer")
In [56]: outer_join
Out[56]:
key value_x value_y
0 A 0.469112 NaN
1 B -0.282863 1.212112
2 C -1.509059 NaN
3 D -1.135632 -0.173215
4 D -1.135632 0.119209
5 E NaN -1.044236
merge は VLOOKUP に比べていくつかの利点があります。
検索値は、検索テーブルの最初の列である必要はありません。
複数の行が一致した場合、最初の1行だけでなく、一致ごとに1行が作成されます。
指定された単一の列だけでなく、ルックアップテーブルのすべての列を含みます。
より複雑な結合操作をサポートします。
その他の考慮事項#
フィルハンドル#
特定のセル範囲に設定されたパターンに従って一連の数値を作成します。スプレッドシートでは、最初の数値を入力した後に Shift キーを押しながらドラッグするか、最初の2つまたは3つの値を入力してからドラッグすることで行われます。
これは、シリーズを作成し、目的のセルに割り当てることで実現できます。
In [57]: df = pd.DataFrame({"AAA": [1] * 8, "BBB": list(range(0, 8))})
In [58]: df
Out[58]:
AAA BBB
0 1 0
1 1 1
2 1 2
3 1 3
4 1 4
5 1 5
6 1 6
7 1 7
In [59]: series = list(range(1, 5))
In [60]: series
Out[60]: [1, 2, 3, 4]
In [61]: df.loc[2:5, "AAA"] = series
In [62]: df
Out[62]:
AAA BBB
0 1 0
1 1 1
2 1 2
3 2 3
4 3 4
5 4 5
6 1 6
7 1 7
重複の削除#
Excel には重複する値を削除する組み込み機能があります。これは pandas では drop_duplicates() を介してサポートされています。
In [63]: df = pd.DataFrame(
....: {
....: "class": ["A", "A", "A", "B", "C", "D"],
....: "student_count": [42, 35, 42, 50, 47, 45],
....: "all_pass": ["Yes", "Yes", "Yes", "No", "No", "Yes"],
....: }
....: )
....:
In [64]: df.drop_duplicates()
Out[64]:
class student_count all_pass
0 A 42 Yes
1 A 35 Yes
3 B 50 No
4 C 47 No
5 D 45 Yes
In [65]: df.drop_duplicates(["class", "student_count"])
Out[65]:
class student_count all_pass
0 A 42 Yes
1 A 35 Yes
3 B 50 No
4 C 47 No
5 D 45 Yes
ピボットテーブル#
スプレッドシートのピボットテーブルは、pandas の再形成とピボットテーブルで再現できます。再び tips データセットを使用して、パーティーのサイズとサーバーの性別ごとの平均チップ額を調べてみましょう。
Excel では、ピボットテーブルに次の構成を使用します
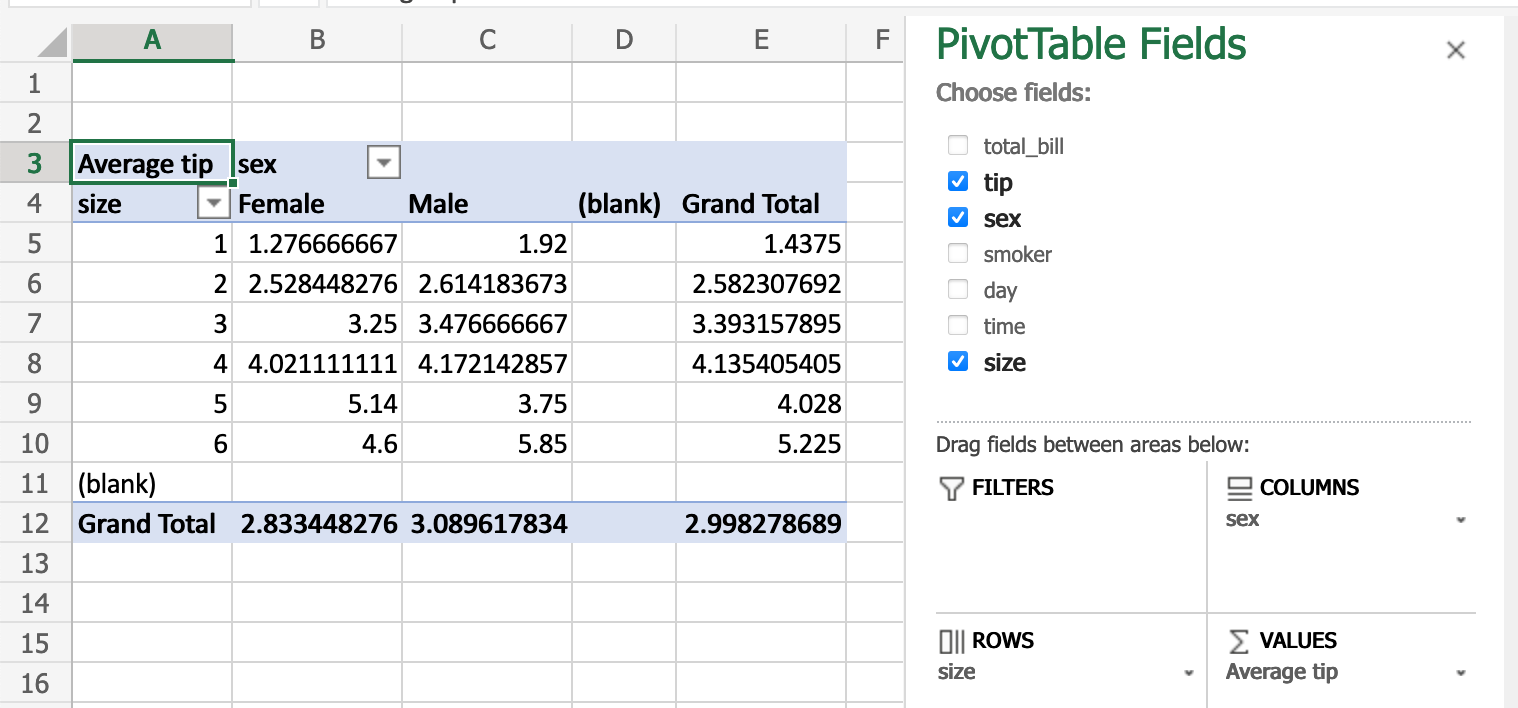
pandas での同等な操作
In [66]: pd.pivot_table(
....: tips, values="tip", index=["size"], columns=["sex"], aggfunc=np.average
....: )
....:
Out[66]:
sex Female Male
size
1 1.276667 1.920000
2 2.528448 2.614184
3 3.250000 3.476667
4 4.021111 4.172143
5 5.140000 3.750000
6 4.600000 5.850000
行の追加#
RangeIndex (番号 0, 1 など) を使用していると仮定すると、concat() を使用して DataFrame の最後に新しい行を追加できます。
In [67]: df
Out[67]:
class student_count all_pass
0 A 42 Yes
1 A 35 Yes
2 A 42 Yes
3 B 50 No
4 C 47 No
5 D 45 Yes
In [68]: new_row = pd.DataFrame([["E", 51, True]],
....: columns=["class", "student_count", "all_pass"])
....:
In [69]: pd.concat([df, new_row])
Out[69]:
class student_count all_pass
0 A 42 Yes
1 A 35 Yes
2 A 42 Yes
3 B 50 No
4 C 47 No
5 D 45 Yes
0 E 51 True
検索と置換#
Excel の検索ダイアログは、一致するセルを一つずつ表示します。pandas では、この操作は通常、条件式を介して、列全体または DataFrame 全体に対して一度に実行されます。
In [70]: tips
Out[70]:
total_bill tip sex smoker day time size
67 1.07 1.00 Female Yes Sat Dinner 1
92 3.75 1.00 Female Yes Fri Dinner 2
111 5.25 1.00 Female No Sat Dinner 1
145 6.35 1.50 Female No Thur Lunch 2
135 6.51 1.25 Female No Thur Lunch 2
.. ... ... ... ... ... ... ...
182 43.35 3.50 Male Yes Sun Dinner 3
156 46.17 5.00 Male No Sun Dinner 6
59 46.27 6.73 Male No Sat Dinner 4
212 46.33 9.00 Male No Sat Dinner 4
170 48.81 10.00 Male Yes Sat Dinner 3
[244 rows x 7 columns]
In [71]: tips == "Sun"
Out[71]:
total_bill tip sex smoker day time size
67 False False False False False False False
92 False False False False False False False
111 False False False False False False False
145 False False False False False False False
135 False False False False False False False
.. ... ... ... ... ... ... ...
182 False False False False True False False
156 False False False False True False False
59 False False False False False False False
212 False False False False False False False
170 False False False False False False False
[244 rows x 7 columns]
In [72]: tips["day"].str.contains("S")
Out[72]:
67 True
92 False
111 True
145 False
135 False
...
182 True
156 True
59 True
212 True
170 True
Name: day, Length: 244, dtype: bool
pandas の replace() は、Excel の すべて置換 に匹敵します。
In [73]: tips.replace("Thu", "Thursday")
Out[73]:
total_bill tip sex smoker day time size
67 1.07 1.00 Female Yes Sat Dinner 1
92 3.75 1.00 Female Yes Fri Dinner 2
111 5.25 1.00 Female No Sat Dinner 1
145 6.35 1.50 Female No Thur Lunch 2
135 6.51 1.25 Female No Thur Lunch 2
.. ... ... ... ... ... ... ...
182 43.35 3.50 Male Yes Sun Dinner 3
156 46.17 5.00 Male No Sun Dinner 6
59 46.27 6.73 Male No Sat Dinner 4
212 46.33 9.00 Male No Sat Dinner 4
170 48.81 10.00 Male Yes Sat Dinner 3
[244 rows x 7 columns]