バージョン 0.17.0 (2015年10月9日)#
これは0.16.2からのメジャーリリースであり、いくつかのAPI変更、いくつかの新機能、機能強化、パフォーマンス改善に加え、多数のバグ修正が含まれています。すべてのユーザーにこのバージョンへのアップグレードを推奨します。
警告
pandas >= 0.17.0 は Python 3.2 との互換性をサポートしなくなります (GH 9118)
警告
pandas.io.data パッケージは非推奨となり、pandas-datareader パッケージに置き換えられます。これにより、データモジュールを pandas のインストールとは独立して更新できるようになります。pandas-datareader v0.1.1 の API は pandas v0.17.0 と全く同じです (GH 8961, GH 10861)。
pandas-datareader をインストールした後、インポートを簡単に変更できます
from pandas.io import data, wb
となります
from pandas_datareader import data, wb
主な機能は以下の通りです。
一部のcython操作でグローバルインタープリタロック (GIL) を解放します。詳細はこちらをご覧ください。
プロットメソッドは、
.plotアクセサーの属性として利用可能になりました。詳細はこちらをご覧ください。ソートAPIは、長年の矛盾を解消するために刷新されました。詳細はこちらをご覧ください。
タイムゾーンを持つ
datetime64[ns]を第一級の dtype としてサポートします。詳細はこちらをご覧ください。to_datetimeのデフォルトが、解析不可能な形式の場合にraiseするようになりました。以前は元の入力を返していました。また、日付解析関数は一貫した結果を返すようになりました。詳細はこちらをご覧ください。HDFStoreのdropnaのデフォルトがFalseに変更され、すべての行がNaNであってもデフォルトですべての行が保存されるようになりました。詳細はこちらをご覧ください。Datetimeアクセサー (
dt) は、datetimeライクなオブジェクトに対してフォーマットされた文字列を生成するSeries.dt.strftimeと、timedeltaの各期間を秒単位で生成するSeries.dt.total_secondsをサポートするようになりました。詳細はこちらをご覧ください。PeriodとPeriodIndexは、3日間に対応する3Dのような乗算されたfreqを処理できるようになりました。詳細はこちらをご覧ください。開発用にインストールされた pandas のバージョンは、
PEP440に準拠したバージョン文字列を持つようになります (GH 9518)Air Speed Velocity ライブラリによるベンチマークの開発サポート (GH 8361)
SAS xport ファイルの読み取りをサポートします。詳細はこちらをご覧ください。
SASと pandas を比較するドキュメント。詳細はこちらをご覧ください。
0.8.0以降非推奨となっていた自動 TimeSeries ブロードキャストを削除しました。詳細はこちらをご覧ください。
プレーンテキストでの表示形式は、Unicode東アジア幅に合わせてオプションで配置できるようになりました。詳細はこちらをご覧ください。
Python 3.5 との互換性 (GH 11097)
matplotlib 1.5.0 との互換性 (GH 11111)
新機能#
タイムゾーン付きDatetime#
タイムゾーン付きdatetimeをネイティブにサポートする実装を追加しています。Series または DataFrame の列は、以前はタイムゾーン付きdatetimeを割り当てることが でき 、object dtype として機能していました。これは、多数の行でパフォーマンスの問題がありました。詳細はドキュメントをご覧ください。( GH 8260, GH 10763, GH 11034 )。
新しい実装により、すべての行で単一のタイムゾーンを使用でき、パフォーマンスの高い方法で操作を実行できます。
In [1]: df = pd.DataFrame(
...: {
...: "A": pd.date_range("20130101", periods=3),
...: "B": pd.date_range("20130101", periods=3, tz="US/Eastern"),
...: "C": pd.date_range("20130101", periods=3, tz="CET"),
...: }
...: )
...:
In [2]: df
Out[2]:
A B C
0 2013-01-01 2013-01-01 00:00:00-05:00 2013-01-01 00:00:00+01:00
1 2013-01-02 2013-01-02 00:00:00-05:00 2013-01-02 00:00:00+01:00
2 2013-01-03 2013-01-03 00:00:00-05:00 2013-01-03 00:00:00+01:00
[3 rows x 3 columns]
In [3]: df.dtypes
Out[3]:
A datetime64[ns]
B datetime64[ns, US/Eastern]
C datetime64[ns, CET]
Length: 3, dtype: object
In [4]: df.B
Out[4]:
0 2013-01-01 00:00:00-05:00
1 2013-01-02 00:00:00-05:00
2 2013-01-03 00:00:00-05:00
Name: B, Length: 3, dtype: datetime64[ns, US/Eastern]
In [5]: df.B.dt.tz_localize(None)
Out[5]:
0 2013-01-01
1 2013-01-02
2 2013-01-03
Name: B, Length: 3, dtype: datetime64[ns]
これは新しいdtype表現も使用しており、numpyのいとこである datetime64[ns] と見た目も非常に似ています
In [6]: df["B"].dtype
Out[6]: datetime64[ns, US/Eastern]
In [7]: type(df["B"].dtype)
Out[7]: pandas.core.dtypes.dtypes.DatetimeTZDtype
注
dtypeの変更の結果として、基になる DatetimeIndex の文字列表現がわずかに異なりますが、機能的には同じです。
以前の動作
In [1]: pd.date_range('20130101', periods=3, tz='US/Eastern')
Out[1]: DatetimeIndex(['2013-01-01 00:00:00-05:00', '2013-01-02 00:00:00-05:00',
'2013-01-03 00:00:00-05:00'],
dtype='datetime64[ns]', freq='D', tz='US/Eastern')
In [2]: pd.date_range('20130101', periods=3, tz='US/Eastern').dtype
Out[2]: dtype('<M8[ns]')
新しい動作
In [8]: pd.date_range("20130101", periods=3, tz="US/Eastern")
Out[8]:
DatetimeIndex(['2013-01-01 00:00:00-05:00', '2013-01-02 00:00:00-05:00',
'2013-01-03 00:00:00-05:00'],
dtype='datetime64[ns, US/Eastern]', freq='D')
In [9]: pd.date_range("20130101", periods=3, tz="US/Eastern").dtype
Out[9]: datetime64[ns, US/Eastern]
GILの解放#
一部のcython操作でグローバルインタープリタロック(GIL)を解放しています。これにより、計算中に他のスレッドを同時に実行できるようになり、マルチスレッドによるパフォーマンスの向上が期待できます。特にgroupby、nsmallest、value_counts、および一部のインデックス操作がこれによる恩恵を受けます。( GH 8882 )
たとえば、次のコードのgroupby式では、ファクタリングステップ(例:df.groupby('key'))と.sum()操作の両方でGILが解放されます。
N = 1000000
ngroups = 10
df = DataFrame(
{"key": np.random.randint(0, ngroups, size=N), "data": np.random.randn(N)}
)
df.groupby("key")["data"].sum()
GILの解放は、ユーザーとの対話にスレッドを使用するアプリケーション(例:QT)や、マルチスレッド計算を実行するアプリケーションに役立つ可能性があります。これらの種類の並列計算を処理できるライブラリの好例は、daskライブラリです。
サブメソッドのプロット#
Series および DataFrame の .plot() メソッドは、kind キーワード引数を指定することで、プロットタイプをカスタマイズできます。残念ながら、これらのプロットタイプの多くは、異なる必須およびオプションのキーワード引数を使用するため、何十もの可能な引数の中から特定のプロットタイプが何を使用するのかを特定することが困難でした。
この問題を軽減するために、新しいオプションのプロットインターフェースを追加しました。これにより、各プロットタイプが .plot 属性のメソッドとして公開されます。series.plot(kind=<kind>, ...) と書く代わりに、series.plot.<kind>(...) も使用できるようになりました。
In [10]: df = pd.DataFrame(np.random.rand(10, 2), columns=['a', 'b'])
In [11]: df.plot.bar()
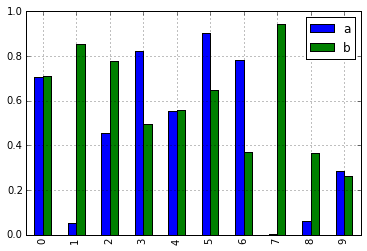
この変更の結果、これらのメソッドはすべてタブ補完で検出できるようになりました
In [12]: df.plot.<TAB> # noqa: E225, E999
df.plot.area df.plot.barh df.plot.density df.plot.hist df.plot.line df.plot.scatter
df.plot.bar df.plot.box df.plot.hexbin df.plot.kde df.plot.pie
各メソッドのシグネチャには、関連する引数のみが含まれています。現在、これらは必須引数に限定されていますが、将来的にはオプション引数も含まれる予定です。概要については、新しいプロットAPIドキュメントをご覧ください。
dt アクセサーの追加メソッド#
Series.dt.strftime#
datetime-likeなオブジェクトに対して、整形された文字列を生成する Series.dt.strftime メソッドをサポートするようになりました (GH 10110)。例:
# DatetimeIndex
In [13]: s = pd.Series(pd.date_range("20130101", periods=4))
In [14]: s
Out[14]:
0 2013-01-01
1 2013-01-02
2 2013-01-03
3 2013-01-04
Length: 4, dtype: datetime64[ns]
In [15]: s.dt.strftime("%Y/%m/%d")
Out[15]:
0 2013/01/01
1 2013/01/02
2 2013/01/03
3 2013/01/04
Length: 4, dtype: object
# PeriodIndex
In [16]: s = pd.Series(pd.period_range("20130101", periods=4))
In [17]: s
Out[17]:
0 2013-01-01
1 2013-01-02
2 2013-01-03
3 2013-01-04
Length: 4, dtype: period[D]
In [18]: s.dt.strftime("%Y/%m/%d")
Out[18]:
0 2013/01/01
1 2013/01/02
2 2013/01/03
3 2013/01/04
Length: 4, dtype: object
文字列の形式はPythonの標準ライブラリと同じであり、詳細はこちらで確認できます
Series.dt.total_seconds#
timedelta64 型の pd.Series には、timedeltaの期間を秒単位で返す新しいメソッド .dt.total_seconds() が追加されました (GH 10817)。
# TimedeltaIndex
In [19]: s = pd.Series(pd.timedelta_range("1 minutes", periods=4))
In [20]: s
Out[20]:
0 0 days 00:01:00
1 1 days 00:01:00
2 2 days 00:01:00
3 3 days 00:01:00
Length: 4, dtype: timedelta64[ns]
In [21]: s.dt.total_seconds()
Out[21]:
0 60.0
1 86460.0
2 172860.0
3 259260.0
Length: 4, dtype: float64
期間周波数の強化#
Period, PeriodIndex, period_range が乗算されたfreqを受け入れられるようになりました。また、Period.freq および PeriodIndex.freq は、DatetimeIndex のように DateOffset インスタンスとして保存されるようになり、str ではありません (GH 7811)。
乗算されたfreqは、対応する長さの期間を表します。以下の例は3日間の期間を作成します。加算と減算は、その期間をそのスパンだけシフトします。
In [22]: p = pd.Period("2015-08-01", freq="3D")
In [23]: p
Out[23]: Period('2015-08-01', '3D')
In [24]: p + 1
Out[24]: Period('2015-08-04', '3D')
In [25]: p - 2
Out[25]: Period('2015-07-26', '3D')
In [26]: p.to_timestamp()
Out[26]: Timestamp('2015-08-01 00:00:00')
In [27]: p.to_timestamp(how="E")
Out[27]: Timestamp('2015-08-03 23:59:59.999999999')
PeriodIndex と period_range で乗算されたfreqを使用できます。
In [28]: idx = pd.period_range("2015-08-01", periods=4, freq="2D")
In [29]: idx
Out[29]: PeriodIndex(['2015-08-01', '2015-08-03', '2015-08-05', '2015-08-07'], dtype='period[2D]')
In [30]: idx + 1
Out[30]: PeriodIndex(['2015-08-03', '2015-08-05', '2015-08-07', '2015-08-09'], dtype='period[2D]')
SAS XPORT ファイルのサポート#
read_sas() は SAS XPORT 形式ファイルの読み取りをサポートします。(GH 4052)。
df = pd.read_sas("sas_xport.xpt")
イテレータを取得して、XPORT ファイルを増分的に読み取ることも可能です。
for df in pd.read_sas("sas_xport.xpt", chunksize=10000):
do_something(df)
詳細はドキュメントをご覧ください。
.eval()での数学関数のサポート#
eval() は数学関数の呼び出しをサポートするようになりました (GH 4893)
df = pd.DataFrame({"a": np.random.randn(10)})
df.eval("b = sin(a)")
サポートされている数学関数は sin, cos, exp, log, expm1, log1p, sqrt, sinh, cosh, tanh, arcsin, arccos, arctan, arccosh, arcsinh, arctanh, abs, arctan2 です。
これらの関数は、NumExpr エンジンの内部関数にマップされます。Python エンジンの場合は、NumPy の呼び出しにマップされます。
MultiIndex を使用したExcelへの変更#
バージョン0.16.2では、MultiIndex 列を持つ DataFrame を to_excel 経由でExcelに書き込むことができませんでした。その機能が追加され (GH 10564)、read_excel も更新され、header と index_col パラメータで MultiIndex を構成する列/行を指定することで、情報を失うことなくデータを読み戻すことができるようになりました (GH 4679)
詳細はドキュメントをご覧ください。
In [31]: df = pd.DataFrame(
....: [[1, 2, 3, 4], [5, 6, 7, 8]],
....: columns=pd.MultiIndex.from_product(
....: [["foo", "bar"], ["a", "b"]], names=["col1", "col2"]
....: ),
....: index=pd.MultiIndex.from_product([["j"], ["l", "k"]], names=["i1", "i2"]),
....: )
....:
In [32]: df
Out[32]:
col1 foo bar
col2 a b a b
i1 i2
j l 1 2 3 4
k 5 6 7 8
[2 rows x 4 columns]
In [33]: df.to_excel("test.xlsx")
In [34]: df = pd.read_excel("test.xlsx", header=[0, 1], index_col=[0, 1])
In [35]: df
Out[35]:
col1 foo bar
col2 a b a b
i1 i2
j l 1 2 3 4
k 5 6 7 8
[2 rows x 4 columns]
以前は、シリアル化されたデータにインデックス名がある場合、read_excel の has_index_names 引数を指定する必要がありました。バージョン0.17.0では、to_excel の出力形式が変更され、このキーワードが不要になりました。変更点は以下の通りです。
旧
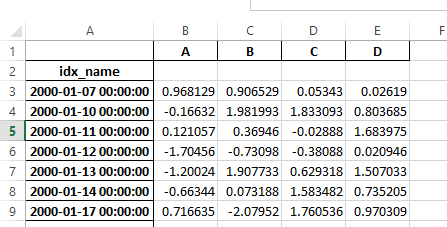
新
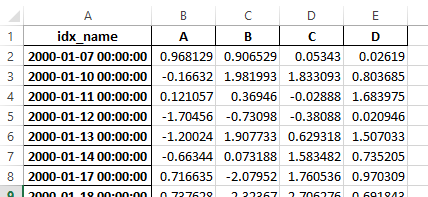
警告
バージョン 0.16.2 以前に保存された、インデックス名を持つ Excel ファイルは、引き続き読み取り可能ですが、has_index_names 引数を True に指定する必要があります。
Google BigQueryの機能強化#
宛先テーブル/データセットが存在しない場合でも、
pandas.io.gbq.to_gbq()関数を使用してテーブル/データセットを自動的に作成する機能が追加されました。( GH 8325, GH 11121 )。pandas.io.gbq.to_gbq()関数を呼び出す際に、if_exists引数を使用して既存のテーブルとスキーマを置き換える機能が追加されました。詳細はドキュメントをご覧ください (GH 8325)。gbq モジュールの
InvalidColumnOrderおよびInvalidPageTokenは、IOErrorではなくValueErrorを発生させるようになります。generate_bq_schema()関数は非推奨となり、将来のバージョンで削除されます (GH 11121)。gbqモジュールはPython 3をサポートするようになりました (GH 11094)。
Unicode東アジア幅による表示位置合わせ#
警告
このオプションを有効にすると、DataFrame と Series の印刷パフォーマンスに影響します(約2倍遅くなります)。実際に必要な場合にのみ使用してください。
東アジアの一部の国では、幅が2つのアルファベットに相当するUnicode文字を使用しています。DataFrame または Series にこれらの文字が含まれている場合、デフォルトの出力は適切に整列されません。これらの文字を正確に処理できるように、以下のオプションが追加されました。
display.unicode.east_asian_width: 表示テキストの幅を計算するためにUnicode東アジア幅を使用するかどうか。(GH 2612)display.unicode.ambiguous_as_wide: あいまいなUnicode文字をワイドとして扱うかどうか。(GH 11102)
In [36]: df = pd.DataFrame({u"国籍": ["UK", u"日本"], u"名前": ["Alice", u"しのぶ"]})
In [37]: df
Out[37]:
国籍 名前
0 UK Alice
1 日本 しのぶ
[2 rows x 2 columns]
In [38]: pd.set_option("display.unicode.east_asian_width", True)
In [39]: df
Out[39]:
国籍 名前
0 UK Alice
1 日本 しのぶ
[2 rows x 2 columns]
詳細については、こちらを参照してください。
その他の機能強化#
openpyxl>= 2.2 のサポート。スタイルのサポートAPIが安定しました (GH 10125)。mergeはindicator引数を受け入れるようになり、出力オブジェクトにカテゴリカル型の列(デフォルトでは_mergeと呼ばれる)が追加され、以下の値を取ります (GH 8790)。観測元
_mergeの値'left'フレームのみにマージキーがある場合left_only'right'フレームのみにマージキーがある場合right_only両方のフレームにマージキーがある場合
bothIn [40]: df1 = pd.DataFrame({"col1": [0, 1], "col_left": ["a", "b"]}) In [41]: df2 = pd.DataFrame({"col1": [1, 2, 2], "col_right": [2, 2, 2]}) In [42]: pd.merge(df1, df2, on="col1", how="outer", indicator=True) Out[42]: col1 col_left col_right _merge 0 0 a NaN left_only 1 1 b 2.0 both 2 2 NaN 2.0 right_only 3 2 NaN 2.0 right_only [4 rows x 4 columns]
詳細については、更新されたドキュメントを参照してください。
pd.to_numericは、文字列を数値に強制変換するための新しい関数です (強制変換を伴うこともあります) (GH 11133)。pd.mergeは、マージ対象ではない場合に重複する列名を許可するようになりました (GH 10639)。pd.pivotは、indexをNoneとして渡すことを許可するようになりました (GH 3962)。pd.concatは、提供された場合は既存のSeries名を使用するようになりました (GH 10698)。In [43]: foo = pd.Series([1, 2], name="foo") In [44]: bar = pd.Series([1, 2]) In [45]: baz = pd.Series([4, 5])
以前の動作
In [1]: pd.concat([foo, bar, baz], axis=1) Out[1]: 0 1 2 0 1 1 4 1 2 2 5
新しい動作
In [46]: pd.concat([foo, bar, baz], axis=1) Out[46]: foo 0 1 0 1 1 4 1 2 2 5 [2 rows x 3 columns]
DataFrameにnlargestおよびnsmallestメソッドが追加されました (GH 10393)。interpolateがNaN値を前方、後方、またはその両方で埋めることができるように、limitと連携するlimit_directionキーワード引数が追加されました (GH 9218, GH 10420, GH 11115)In [47]: ser = pd.Series([np.nan, np.nan, 5, np.nan, np.nan, np.nan, 13]) In [48]: ser.interpolate(limit=1, limit_direction="both") Out[48]: 0 NaN 1 5.0 2 5.0 3 7.0 4 NaN 5 11.0 6 13.0 Length: 7, dtype: float64
値を可変数の小数点以下に丸める
DataFrame.roundメソッドが追加されました (GH 10568)。In [49]: df = pd.DataFrame( ....: np.random.random([3, 3]), ....: columns=["A", "B", "C"], ....: index=["first", "second", "third"], ....: ) ....: In [50]: df Out[50]: A B C first 0.126970 0.966718 0.260476 second 0.897237 0.376750 0.336222 third 0.451376 0.840255 0.123102 [3 rows x 3 columns] In [51]: df.round(2) Out[51]: A B C first 0.13 0.97 0.26 second 0.90 0.38 0.34 third 0.45 0.84 0.12 [3 rows x 3 columns] In [52]: df.round({"A": 0, "C": 2}) Out[52]: A B C first 0.0 0.966718 0.26 second 1.0 0.376750 0.34 third 0.0 0.840255 0.12 [3 rows x 3 columns]
drop_duplicatesとduplicatedは、最初、最後、およびすべての重複を対象とするkeepキーワードを受け入れるようになりました。take_lastキーワードは非推奨になりました。詳細はこちらをご覧ください (GH 6511, GH 8505)。In [53]: s = pd.Series(["A", "B", "C", "A", "B", "D"]) In [54]: s.drop_duplicates() Out[54]: 0 A 1 B 2 C 5 D Length: 4, dtype: object In [55]: s.drop_duplicates(keep="last") Out[55]: 2 C 3 A 4 B 5 D Length: 4, dtype: object In [56]: s.drop_duplicates(keep=False) Out[56]: 2 C 5 D Length: 2, dtype: object
Reindex に
tolerance引数が追加され、再インデックス時のフィル制限をより細かく制御できるようになりました (GH 10411)。In [57]: df = pd.DataFrame({"x": range(5), "t": pd.date_range("2000-01-01", periods=5)}) In [58]: df.reindex([0.1, 1.9, 3.5], method="nearest", tolerance=0.2) Out[58]: x t 0.1 0.0 2000-01-01 1.9 2.0 2000-01-03 3.5 NaN NaT [3 rows x 2 columns]
DatetimeIndex、TimedeltaIndex、またはPeriodIndexで使用する場合、toleranceは可能であればTimedeltaに強制変換されます。これにより、文字列でtoleranceを指定できますIn [59]: df = df.set_index("t") In [60]: df.reindex(pd.to_datetime(["1999-12-31"]), method="nearest", tolerance="1 day") Out[60]: x 1999-12-31 0 [1 rows x 1 columns]
toleranceは、下位レベルのIndex.get_indexerおよびIndex.get_locメソッドでも公開されています。TimeDeltaIndexをリサンプリングする際にbase引数を使用する機能が追加されました (GH 10530)。DatetimeIndexはNaTを含む文字列を使用してインスタンス化できるようになりました (GH 7599)。to_datetimeはyearfirstキーワードを受け入れるようになりました (GH 7599)。pandas.tseries.offsetsのDayオフセットよりも大きいオフセットをSeriesとの加算/減算に使用できるようになりました (GH 10699)。詳細はドキュメントをご覧ください。pd.Timedelta.total_seconds()は Timedelta の期間をナノ秒精度で返すようになりました(以前はマイクロ秒精度でした)(GH 10939)。PeriodIndexはnp.ndarrayとの算術演算をサポートするようになりました (GH 10638)。Periodオブジェクトのピクル化をサポートします (GH 10439)。.as_blocksはcopyオプション引数を受け入れるようになり、データのコピーを返します。デフォルトはコピーです(以前のバージョンからの動作変更はありません)。(GH 9607)DataFrame.filterのregex引数は、ValueErrorを発生させる代わりに、数値の列名を処理するようになりました (GH 10384)。URL経由でのgzip圧縮ファイルの読み込みを有効にしました。圧縮パラメータを明示的に設定するか、レスポンスのHTTP Content-Encodingヘッダの存在から推測することによって行えます (GH 8685)
StringIO/BytesIO を使用して メモリ内 で Excel ファイルを書き込むことを有効にしました (GH 7074)。
ExcelWriterでリストと辞書を文字列にシリアル化することを有効にしました (GH 8188)。SQL IO 関数は SQLAlchemy の接続可能なオブジェクトを受け入れるようになりました。( GH 7877 )
pd.read_sqlおよびto_sqlは、conパラメータとしてデータベース URI を受け入れるようになりました (GH 10214)。read_sql_tableはビューからの読み取りを許可するようになりました (GH 10750)。table形式を使用する場合、複雑な値をHDFStoresに書き込むことを有効にしました (GH 10447)。HDF ファイルが単一のデータセットを含んでいる場合、キーを指定せずに
pd.read_hdfを使用できるようにしました (GH 10443)。pd.read_stataは Stata 118 タイプのファイルを読み取るようになりました。(GH 9882)。msgpackサブモジュールが後方互換性を持って 0.4.6 に更新されました (GH 10581)。DataFrame.to_dictはorient='index'キーワード引数を受け入れるようになりました (GH 10844)。DataFrame.applyは、渡された関数が辞書を返し、reduce=Trueの場合に、辞書の Series を返します (GH 8735)。補間メソッドに
kwargsを渡せるようになりました (GH 10378)。Dataframeオブジェクトの空のイテラブルを結合する際のエラーメッセージが改善されました (GH 9157)pd.read_csvは、bz2圧縮ファイルを増分的に読み込めるようになり、CパーサーはAWS S3からbz2圧縮ファイルを読み込めるようになりました (GH 11070, GH 11072)。pd.read_csvで、s3n://とs3a://の URL を S3 ファイルストレージを指定するものとして認識するようになりました (GH 11070, GH 11071)。AWS S3 ストレージから CSV ファイルを読み込む際に、ファイル全体を最初にダウンロードするのではなく、増分的に読み込むようになりました。(Python 2 の圧縮ファイルでは、ファイル全体をダウンロードする必要がまだあります。) (GH 11070, GH 11073)
pd.read_csvは、AWS S3 ストレージから読み込まれたファイルの圧縮タイプを推測できるようになりました (GH 11070, GH 11074)。
下位互換性のない API の変更#
ソートAPIの変更#
ソートAPIには、長らくいくつかの不整合がありました。( GH 9816, GH 8239 )。
0.17.0 以前 の API の概要を以下に示します
Series.sortは インプレース であり、DataFrame.sortは新しいオブジェクトを返します。Series.orderは新しいオブジェクトを返しますSeries/DataFrame.sort_indexを使用して、byキーワードを渡すことで 値 でソートすることが可能でした。Series/DataFrame.sortlevelは、インデックスによるソートの場合にのみMultiIndexで機能しました。
これらの問題に対処するため、API を刷新しました。
値 のソートを処理するために、
DataFrame.sort()、Series.sort()、およびSeries.order()を統合した新しいメソッドDataFrame.sort_values()を導入しました。既存のメソッド
Series.sort()、Series.order()、およびDataFrame.sort()は非推奨となり、将来のバージョンで削除されます。DataFrame.sort_index()のby引数は非推奨となり、将来のバージョンで削除されます。既存のメソッド
.sort_index()には、レベルソートを可能にするlevelキーワードが追加されます。
これで、2つの明確で重複しないソート方法があります。* は FutureWarning を表示する項目を示します。
値 でソートするには
以前 |
代替 |
|---|---|
* |
|
* |
|
* |
|
インデックス でソートするには
以前 |
代替 |
|---|---|
|
|
|
|
|
|
|
|
* |
|
Index と Categorical の2つの Series-like クラスで、同様のメソッドも非推奨となり変更されました。
以前 |
代替 |
|---|---|
* |
|
* |
|
to_datetimeとto_timedeltaの変更#
エラー処理#
pd.to_datetime のエラー処理のデフォルトが errors='raise' に変更されました。以前のバージョンでは errors='ignore' でした。さらに、coerce 引数は errors='coerce' に有利なため非推奨になりました。これは、無効な解析が以前のバージョンのように元の入力を返すのではなく、エラーを発生させることを意味します。( GH 10636 )
以前の動作
In [2]: pd.to_datetime(['2009-07-31', 'asd'])
Out[2]: array(['2009-07-31', 'asd'], dtype=object)
新しい動作
In [3]: pd.to_datetime(['2009-07-31', 'asd'])
ValueError: Unknown string format
もちろん、これを強制することもできます。
In [61]: pd.to_datetime(["2009-07-31", "asd"], errors="coerce")
Out[61]: DatetimeIndex(['2009-07-31', 'NaT'], dtype='datetime64[ns]', freq=None)
以前の動作を維持するには、errors='ignore' を使用できます
In [4]: pd.to_datetime(["2009-07-31", "asd"], errors="ignore")
Out[4]: Index(['2009-07-31', 'asd'], dtype='object')
さらに、pd.to_timedelta にも同様のAPI errors='raise'|'ignore'|'coerce' が追加され、coerce キーワードは errors='coerce' に有利なため非推奨になりました。
一貫した解析#
to_datetime, Timestamp, DatetimeIndex の文字列解析が一貫したものになりました。( GH 7599 )
v0.17.0 以前では、Timestamp と to_datetime は年のみの datetime 文字列を今日の誤った日付で解析する可能性があり、一方 DatetimeIndex は年の初めを使用しました。Timestamp と to_datetime は、四半期文字列など、DatetimeIndex が解析できる一部の種類の datetime 文字列で ValueError を発生させる可能性がありました。
以前の動作
In [1]: pd.Timestamp('2012Q2')
Traceback
...
ValueError: Unable to parse 2012Q2
# Results in today's date.
In [2]: pd.Timestamp('2014')
Out [2]: 2014-08-12 00:00:00
v0.17.0 はこれらを以下のように解析できます。DatetimeIndex でも機能します。
新しい動作
In [62]: pd.Timestamp("2012Q2")
Out[62]: Timestamp('2012-04-01 00:00:00')
In [63]: pd.Timestamp("2014")
Out[63]: Timestamp('2014-01-01 00:00:00')
In [64]: pd.DatetimeIndex(["2012Q2", "2014"])
Out[64]: DatetimeIndex(['2012-04-01', '2014-01-01'], dtype='datetime64[ns]', freq=None)
注
今日の日付に基づいて計算を実行したい場合は、Timestamp.now() と pandas.tseries.offsets を使用してください。
In [65]: import pandas.tseries.offsets as offsets
In [66]: pd.Timestamp.now()
Out[66]: Timestamp('2025-06-05 02:18:37.974955')
In [67]: pd.Timestamp.now() + offsets.DateOffset(years=1)
Out[67]: Timestamp('2026-06-05 02:18:37.975720')
Index比較の変更#
Index の等価演算子は Series と同様の動作をすべきです (GH 9947, GH 10637)。
v0.17.0 から、異なる長さの Index オブジェクトを比較すると ValueError が発生するようになります。これは Series の動作と一貫性を持たせるためです。
以前の動作
In [2]: pd.Index([1, 2, 3]) == pd.Index([1, 4, 5])
Out[2]: array([ True, False, False], dtype=bool)
In [3]: pd.Index([1, 2, 3]) == pd.Index([2])
Out[3]: array([False, True, False], dtype=bool)
In [4]: pd.Index([1, 2, 3]) == pd.Index([1, 2])
Out[4]: False
新しい動作
In [8]: pd.Index([1, 2, 3]) == pd.Index([1, 4, 5])
Out[8]: array([ True, False, False], dtype=bool)
In [9]: pd.Index([1, 2, 3]) == pd.Index([2])
ValueError: Lengths must match to compare
In [10]: pd.Index([1, 2, 3]) == pd.Index([1, 2])
ValueError: Lengths must match to compare
これは、比較がブロードキャストできる numpy の動作とは異なります
In [68]: np.array([1, 2, 3]) == np.array([1])
Out[68]: array([ True, False, False])
あるいは、ブロードキャストできない場合はFalseを返します
In [11]: np.array([1, 2, 3]) == np.array([1, 2])
Out[11]: False
Noneとのブール比較の変更#
Series と None のブール比較は、TypeError を発生させる代わりに、np.nan との比較と同等になります。( GH 1079 )。
In [69]: s = pd.Series(range(3), dtype="float")
In [70]: s.iloc[1] = None
In [71]: s
Out[71]:
0 0.0
1 NaN
2 2.0
Length: 3, dtype: float64
以前の動作
In [5]: s == None
TypeError: Could not compare <type 'NoneType'> type with Series
新しい動作
In [72]: s == None
Out[72]:
0 False
1 False
2 False
Length: 3, dtype: bool
通常、どの値がNULLであるかを知りたいだけでしょう。
In [73]: s.isnull()
Out[73]:
0 False
1 True
2 False
Length: 3, dtype: bool
警告
通常、これらの種類の比較には isnull/notnull を使用することになります。なぜなら isnull/notnull はどの要素が null であるかを教えてくれるからです。注意すべきは、nan's は等しく比較されないが、None's は等しく比較されることです。pandas/numpy は np.nan != np.nan という事実を利用し、None を np.nan と同じように扱います。
In [74]: None == None
Out[74]: True
In [75]: np.nan == np.nan
Out[75]: False
HDFStore dropnaの動作#
format='table' を使用する HDFStore 書き込み関数のデフォルトの動作は、すべての値が欠損している行を保持するようになりました。以前は、インデックス以外のすべての値が欠損している行は削除されていました。以前の動作は dropna=True オプションを使用することで再現できます。( GH 9382 )
以前の動作
In [76]: df_with_missing = pd.DataFrame(
....: {"col1": [0, np.nan, 2], "col2": [1, np.nan, np.nan]}
....: )
....:
In [77]: df_with_missing
Out[77]:
col1 col2
0 0.0 1.0
1 NaN NaN
2 2.0 NaN
[3 rows x 2 columns]
In [27]:
df_with_missing.to_hdf('file.h5',
key='df_with_missing',
format='table',
mode='w')
In [28]: pd.read_hdf('file.h5', 'df_with_missing')
Out [28]:
col1 col2
0 0 1
2 2 NaN
新しい動作
In [78]: df_with_missing.to_hdf("file.h5", key="df_with_missing", format="table", mode="w")
In [79]: pd.read_hdf("file.h5", "df_with_missing")
Out[79]:
col1 col2
0 0.0 1.0
1 NaN NaN
2 2.0 NaN
[3 rows x 2 columns]
詳細はドキュメントをご覧ください。
display.precision オプションの変更#
display.precision オプションは小数点以下を指すように明確化されました (GH 10451)。
以前のバージョンの pandas では、浮動小数点数は display.precision の値よりも小数点以下が1桁少なくフォーマットされていました。
In [1]: pd.set_option('display.precision', 2)
In [2]: pd.DataFrame({'x': [123.456789]})
Out[2]:
x
0 123.5
「有効数字」として精度を解釈すると、これは科学表記法には機能しましたが、同じ解釈は標準的な書式設定の数値には機能しませんでした。また、numpyが書式設定を処理する方法とも一致しませんでした。
今後は、display.precision の値は、通常の書式設定と科学表記法の両方で、小数点以下の桁数を直接制御します。これは numpy の precision 印刷オプションの動作に似ています。
In [80]: pd.set_option("display.precision", 2)
In [81]: pd.DataFrame({"x": [123.456789]})
Out[81]:
x
0 123.46
[1 rows x 1 columns]
以前のバージョンとの出力動作を維持するため、display.precision のデフォルト値は 7 から 6 に減らされました。
Categorical.unique の変更#
Categorical.unique は、np.array を返す代わりに、categories と codes が一意の新しい Categoricals を返すようになりました (GH 10508)。
順序なしカテゴリ: 値とカテゴリは出現順にソートされます。
順序付きカテゴリ: 値は出現順にソートされ、カテゴリは既存の順序を保持します。
In [82]: cat = pd.Categorical(["C", "A", "B", "C"], categories=["A", "B", "C"], ordered=True)
In [83]: cat
Out[83]:
['C', 'A', 'B', 'C']
Categories (3, object): ['A' < 'B' < 'C']
In [84]: cat.unique()
Out[84]:
['C', 'A', 'B']
Categories (3, object): ['A' < 'B' < 'C']
In [85]: cat = pd.Categorical(["C", "A", "B", "C"], categories=["A", "B", "C"])
In [86]: cat
Out[86]:
['C', 'A', 'B', 'C']
Categories (3, object): ['A', 'B', 'C']
In [87]: cat.unique()
Out[87]:
['C', 'A', 'B']
Categories (3, object): ['A', 'B', 'C']
パーサーで header として渡される bool の変更#
以前のバージョンの pandas では、read_csv、read_excel、または read_html の header 引数に bool が渡されると、暗黙的に整数に変換され、False の場合は header=0、True の場合は header=1 となっていました (GH 6113)
header への bool 入力は TypeError を発生させるようになりました
In [29]: df = pd.read_csv('data.csv', header=False)
TypeError: Passing a bool to header is invalid. Use header=None for no header or
header=int or list-like of ints to specify the row(s) making up the column names
その他の API の変更#
subplots=Trueの line および kde プロットは、すべて黒ではなく、デフォルトの色を使用するようになりました。すべての線を黒で描画するにはcolor='k'を指定してください (GH 9894)。categoricaldtype を持つ Series で.value_counts()メソッドを呼び出すと、CategoricalIndexを持つ Series が返されるようになりました (GH 10704)。pandas オブジェクトのサブクラスのメタデータプロパティがシリアル化されるようになりました (GH 10553)。
Categoricalを使用するgroupbyは、上記のCategorical.uniqueと同じルールに従います (GH 10508)。以前は、
complex64dtype の配列でDataFrameを構築すると、対応する列が自動的にcomplex128dtype に昇格されていました。pandas は、複雑なデータに対して入力の itemsize を保持するようになりました (GH 10952)。一部の数値削減演算子は、文字列と数値を含むオブジェクト型に対して
TypeErrorではなくValueErrorを返していました (GH 11131)。現在サポートされていない
chunksize引数をread_excelまたはExcelFile.parseに渡すと、NotImplementedErrorが発生するようになりました (GH 8011)。ExcelFileオブジェクトをread_excelに渡せるようになりました (GH 11198)。DatetimeIndex.unionは、selfと入力がNoneをfreqとして持っている場合、freqを推測しません (GH 11086)。NaTのメソッドは、ValueErrorを発生させるか、np.nanまたはNaTを返すようになりました (GH 9513)。動作
メソッド
np.nanを返すweekday,isoweekdayNaTを返すdate,now,replace,to_datetime,todaynp.datetime64('NaT')を返すto_datetime64(変更なし)ValueErrorを発生させるその他のすべての公開メソッド (アンダースコアで始まらない名前)
非推奨#
Seriesについては、以下のインデックス関数が非推奨になりました (GH 10177)。非推奨の関数
代替
.irow(i).iloc[i]または.iat[i].iget(i).iloc[i]または.iat[i].iget_value(i).iloc[i]または.iat[i]DataFrameについては、以下のインデックス関数が非推奨になりました (GH 10177)。非推奨の関数
代替
.irow(i).iloc[i].iget_value(i, j).iloc[i, j]または.iat[i, j].icol(j).iloc[:, j]
注
これらのインデックス関数は、0.11.0 以降、ドキュメントで非推奨とされてきました。
Categorical.nameは、Categoricalをよりnumpy.ndarrayのようにするために非推奨になりました。代わりにSeries(cat, name="whatever")を使用してください (GH 10482)。Categoricalのcategoriesに欠損値 (NaN) を設定すると警告が表示されます (GH 10748)。valuesには欠損値を含めることができます。drop_duplicatesおよびduplicatedのtake_lastキーワードは、keepに有利なため非推奨になりました。( GH 6511, GH 8505 )Series.nsmallestおよびnlargestのtake_lastキーワードは、keepに有利なため非推奨になりました。( GH 10792 )DataFrame.combineAddおよびDataFrame.combineMultは非推奨になりました。addおよびmulメソッド、具体的にはDataFrame.add(other, fill_value=0)およびDataFrame.mul(other, fill_value=1.)を使用することで簡単に置き換えることができます (GH 10735)。TimeSeriesはSeriesに有利なため非推奨になりました(これは0.13.0以降のエイリアスであったことに注意してください)。(GH 10890)SparsePanelは非推奨となり、将来のバージョンで削除されます (GH 11157)。Series.is_time_seriesはSeries.index.is_all_datesに有利なため非推奨になりました (GH 11135)。レガシーオフセット(
'A@JAN'など)は非推奨になりました(これは0.8.0以降のエイリアスであったことに注意してください)(GH 10878)WidePanelはPanelに、LongPanelはDataFrameに有利なため非推奨になりました(これらは < 0.11.0 以降のエイリアスであったことに注意してください)。(GH 10892)DataFrame.convert_objectsは、型固有の関数pd.to_datetime、pd.to_timestamp、およびpd.to_numeric(0.17.0 で新規) に有利なため非推奨になりました (GH 11133)。
以前のバージョンの非推奨/変更の削除#
Series.order()およびSeries.sort()からna_lastパラメータを削除し、na_positionを優先します。( GH 5231 ).describe()からpercentile_widthを削除し、percentilesを優先します。( GH 7088 )DataFrame.to_string()からcolSpaceパラメータを削除し、約 0.8.0 バージョンからcol_spaceを優先します。自動時系列ブロードキャストの削除 (GH 2304)
In [88]: np.random.seed(1234) In [89]: df = pd.DataFrame( ....: np.random.randn(5, 2), ....: columns=list("AB"), ....: index=pd.date_range("2013-01-01", periods=5), ....: ) ....: In [90]: df Out[90]: A B 2013-01-01 0.471435 -1.190976 2013-01-02 1.432707 -0.312652 2013-01-03 -0.720589 0.887163 2013-01-04 0.859588 -0.636524 2013-01-05 0.015696 -2.242685 [5 rows x 2 columns]
以前
In [3]: df + df.A FutureWarning: TimeSeries broadcasting along DataFrame index by default is deprecated. Please use DataFrame.<op> to explicitly broadcast arithmetic operations along the index Out[3]: A B 2013-01-01 0.942870 -0.719541 2013-01-02 2.865414 1.120055 2013-01-03 -1.441177 0.166574 2013-01-04 1.719177 0.223065 2013-01-05 0.031393 -2.226989
現在
In [91]: df.add(df.A, axis="index") Out[91]: A B 2013-01-01 0.942870 -0.719541 2013-01-02 2.865414 1.120055 2013-01-03 -1.441177 0.166574 2013-01-04 1.719177 0.223065 2013-01-05 0.031393 -2.226989 [5 rows x 2 columns]
HDFStore.put/appendのtableキーワードを削除し、format=を優先します (GH 4645)。read_excel/ExcelFileのkindを未使用のため削除 (GH 4712)Series.tshift/shiftのoffsetおよびtimeRuleキーワードを削除し、freqを優先します (GH 4853, GH 4864)。pd.load/pd.saveエイリアスをpd.to_pickle/pd.read_pickleに有利なため削除 (GH 3787)
パフォーマンス改善#
Air Speed Velocity ライブラリによるベンチマークの開発サポート (GH 8361)
代替の ExcelWriter エンジンと Excel ファイルの読み込みのための vbench ベンチマークが追加されました (GH 7171)。
Categorical.value_countsのパフォーマンスが向上しました (GH 10804)。SeriesGroupBy.nuniqueおよびSeriesGroupBy.value_countsおよびSeriesGroupby.transformのパフォーマンスが向上しました (GH 10820, GH 11077)。整数 dtype を持つ
DataFrame.drop_duplicatesのパフォーマンスが向上しました (GH 10917)。広範なフレームを持つ
DataFrame.duplicatedのパフォーマンスが向上しました。( GH 10161, GH 11180 )timedelta64およびdatetime64操作が8倍向上しました (GH 6755)。スライサーによる
MultiIndexのインデックス作成のパフォーマンスが大幅に向上しました (GH 10287)。リストのような入力を使用する
ilocの性能が8倍向上しました (GH 10791)。datetimelike/整数 Series の
Series.isinのパフォーマンスが向上しました (GH 10287)。カテゴリが同じ場合にカテゴリカルの
concatのパフォーマンスが20倍向上しました (GH 10587)。指定されたフォーマット文字列が ISO8601 の場合、
to_datetimeのパフォーマンスが向上しました (GH 10178)。float dtype の
Series.value_countsのパフォーマンスが2倍向上しました (GH 10821)。日付コンポーネントに0パディングがない場合、
to_datetimeでinfer_datetime_formatを有効にしました (GH 11142)。ネストされた辞書から
DataFrameを構築する際の 0.16.1 からの回帰バグ (GH 11084)DateOffsetとSeriesまたはDatetimeIndexの加算/減算操作のパフォーマンスが向上しました (GH 10744, GH 11205)。
バグ修正#
オーバーフローによる
timedelta64[ns]の.mean()の計算が誤っているバグ (GH 9442)古いnumpyでの
.isinのバグ (GH 11232)DataFrame.to_html(index=False)が不要なname行を表示するバグ (GH 10344)DataFrame.to_latex()でcolumn_format引数を渡せなかったバグ (GH 9402)DatetimeIndexでNaTを使用してローカライズする際のバグ (GH 10477)Series.dt演算でメタデータを保持する際のバグ (GH 10477)その他無効な
to_datetime構築で渡された場合にNaTが保持されないバグ (GH 10477)関数がカテゴリカル Series を返す場合の
DataFrame.applyのバグ (GH 9573)。無効な日付と形式が指定された場合の
to_datetimeのバグ (GH 10154)Index.drop_duplicatesが名前を削除するバグ (GH 10115)。Series.quantileが名前を削除するバグ (GH 10881)。インデックスに頻度がある空の
Seriesに値を設定する場合のpd.Seriesのバグ (GH 10193)。pd.Series.interpolateのorderキーワード値が不正な場合のバグ (GH 10633)。色名が複数文字で指定された場合に
DataFrame.plotがValueErrorを発生させるバグ (GH 10387)タプルの混合リストによる
Index構築のバグ (GH 10697)インデックスに
NaTが含まれる場合のDataFrame.reset_indexのバグ (GH 10388)ワークシートが空の場合の
ExcelReaderのバグ (GH 6403)返される値が基本クラスと互換性がない場合の
BinGrouper.group_infoのバグ (GH 10914)DataFrame.popでキャッシュをクリアし、その後のインプレース操作におけるバグ (GH 10912)混合整数
Indexを使用したインデックス作成がImportErrorを引き起こすバグ (GH 10610)インデックスに null がある場合の
Series.countのバグ (GH 10946)非正規頻度の
DatetimeIndexのピクル化におけるバグ (GH 11002)フレームが対称形状の場合に
DataFrame.whereがaxisパラメーターを尊重しないバグ。 (GH 9736)名前が保持されない場合の
Table.select_columnのバグ (GH 10392)startとendがoffsetよりも細かい精度を持つ場合のoffsets.generate_rangeのバグ (GH 9907)pd.rolling_*で出力においてSeries.nameが失われるバグ (GH 10565)インデックスまたは列が一意でない場合の
stackのバグ。 (GH 10417)軸に MultiIndex がある場合の
Panelの設定におけるバグ (GH 10360)USMemorialDayとUSMartinLutherKingJrが間違っていた場合のUSFederalHolidayCalendarのバグ (GH 10278 および GH 9760 ).sample()で返されるオブジェクトが設定されている場合、不必要なSettingWithCopyWarningを出すバグ (GH 10738).sample()でSeriesとして渡された重みが、位置的に扱われる前に軸に沿って整列されず、重みインデックスがサンプリングされたオブジェクトと整列していなかった場合に問題を引き起こす可能性のあるバグ。 (GH 10738)回帰が修正された (GH 9311, GH 6620, GH 9345)、特定の集計器で datetime-like が float に変換される groupby におけるバグ (GH 10979)
axis=1およびinplace=Trueを使用したDataFrame.interpolateのバグ (GH 10395)複数の列を主キーとして指定した場合の
io.sql.get_schemaのバグ (GH 10385)。datetime-like
Categoricalを使用したgroupby(sort=False)がValueErrorを発生させるバグ (GH 10505)filter()を使用したgroupby(axis=1)がIndexErrorをスローするバグ (GH 11041)ビッグエンディアンビルド上の
test_categoricalのバグ (GH 10425)Series.shiftとDataFrame.shiftがカテゴリデータに対応していないバグ (GH 9416)カテゴリ
Seriesを使用したSeries.mapがAttributeErrorを発生させるバグ (GH 10324)Categoricalを含むMultiIndex.get_level_valuesがAttributeErrorを発生させるバグ (GH 10460)sparse=Trueを使用したpd.get_dummiesがSparseDataFrameを返さないバグ (GH 10531)Indexサブタイプ (PeriodIndexなど) が.dropおよび.insertメソッドで自身のタイプを返さないバグ (GH 10620)right配列が空の場合のalgos.outer_join_indexerのバグ (GH 10618)複数のキーでグループ化する場合の
filter(0.16.0 からの回帰) とtransformのバグ (そのうちの1つはdatetime-like) (GH 10114)to_datetimeとto_timedeltaがIndex名を失わせるバグ (GH 10875)NaN のみを含む列がある場合に
len(DataFrame.groupby)がIndexErrorを引き起こすバグ (GH 11016)空の Series をリサンプリングするとセグメンテーション違反が発生するバグ (GH 10228)
DatetimeIndexとPeriodIndex.value_countsがその結果から名前をリセットするが、結果のIndexには保持するバグ。 (GH 10150)numexprエンジンを使用したpd.evalが 1 要素の numpy 配列をスカラに強制するバグ (GH 10546)列が dtype
categoryの場合にaxis=0を使用したpd.concatのバグ (GH 10177)index_col=False、index_col=['a', 'b']またはdtypeの kwargs を使用したpd.read_csvのバグ (GH 10413, GH 10467, GH 10577)headerkwarg がSeries.nameまたはSeries.index.nameを設定しないSeries.from_csvのバグ (GH 10483)小さな浮動小数点値の分散が不正確になる原因となった
groupby.varのバグ (GH 10448)Series.plot(kind='hist')の Y ラベルが情報不足であるバグ (GH 10485)uint8型を生成するコンバーターを使用する際のread_csvのバグ (GH 9266)時系列の折れ線グラフと面グラフでメモリリークを引き起こすバグ (GH 9003)
右辺が
DataFrameの場合に、メジャー軸またはマイナー軸に沿ってスライスされたPanelを設定する際のバグ (GH 11014)Panelの演算子関数 (例:.add) が実装されていない場合に、Noneを返し、NotImplementedErrorを発生させないバグ (GH 7692)subplots=Trueの場合に、折れ線グラフとkdeプロットが複数の色を受け入れられないバグ (GH 9894)色名が複数文字で指定された場合に
DataFrame.plotがValueErrorを発生させるバグ (GH 10387)MultiIndexを持つSeriesの左右のalignが逆になる可能性のあるバグ (GH 10665)MultiIndexを持つ結合の左右が逆になる可能性のあるバグ (GH 10741)columnsで異なる順序が設定されたファイルを読み込む際のread_stataのバグ (GH 10757)カテゴリに
tzまたはPeriodが含まれている場合にCategoricalが適切に表現されない可能性のあるバグ (GH 10713)Categorical.__iter__が正しいdatetimeとPeriodを返さない可能性のあるバグ (GH 10713)PeriodIndexを持つオブジェクトでPeriodIndexを使用したインデックス作成のバグ (GH 4125)engine='c'を使用したread_csvのバグ: コメント、空行などが先行する EOF が正しく処理されなかった (GH 10728, GH 10548)ウェブサイトのURLが変更されたため、
DataReader経由で「famafrench」データを読み込むとHTTP 404エラーが発生するバグ (GH 10591)。デコードする DataFrame に重複する列名がある場合の
read_msgpackのバグ (GH 9618)バケットにユーザーが読み取り権限を持たないキーも含まれている場合に、有効な S3 ファイルの読み取りが失敗する原因となった
io.common.get_filepath_or_bufferのバグ (GH 10604)Python の
datetime.dateと numpy のdatetime64を使用したタイムスタンプ列のベクトル化された設定のバグ (GH 10408, GH 10412)Index.takeが不要なfreq属性を追加する可能性のあるバグ (GH 10791)空の
DataFrameとのmergeがIndexErrorを発生させる可能性のあるバグ (GH 10824)to_latexのバグで、一部の文書化された引数に対して予期しないキーワード引数が発生する (GH 10888)大きな
DataFrameのインデックス作成でIndexErrorが捕捉されないバグ (GH 10645 および GH 10692)ファイルにヘッダー行しかない場合に
nrowsまたはchunksizeパラメーターを使用する際のread_csvのバグ (GH 9535)代替エンコーディングが存在する場合の HDF5 での
category型のシリアライゼーションのバグ。 (GH 10366)文字列 dtype を持つ空の DataFrame を構築する際の
pd.DataFrameのバグ (GH 9428)DataFrame が統合されていない場合の
pd.DataFrame.diffのバグ (GH 10907)datetime64またはtimedelta64dtype を持つ配列のpd.uniqueのバグで、元の dtype の代わりにオブジェクト dtype の配列が返されることを意味していた (GH 9431)0秒からのスライス時にエラーを発生させる
Timedeltaのバグ (GH 10583)DatetimeIndex.takeとTimedeltaIndex.takeが無効なインデックスに対してIndexErrorを発生させない可能性のあるバグ (GH 10295)Series([np.nan]).astype('M8[ms]')のバグで、現在はSeries([pd.NaT])を返す (GH 10747)PeriodIndex.orderが freq をリセットするバグ (GH 10295)freqがナノ秒としてendを割る場合のdate_rangeのバグ (GH 10885)ilocが負の整数で Series の境界外のメモリにアクセスすることを許可するバグ (GH 10779)エンコーディングが尊重されない
read_msgpackのバグ (GH 10581)適切な負の整数を含むリストで
ilocを使用する際に、最初のインデックスへのアクセスを妨げるバグ (GH 10547, GH 10779)TimedeltaIndexを持つDataFrameをto_csvで保存しようとするとエラーが発生するTimedeltaIndexフォーマッタのバグ (GH 10833)Bigquery がゼロ行を返した場合に
pd.read_gbqがValueErrorをスローするバグ (GH 10273)0ランクの ndarray をシリアライズする際にセグメンテーション違反を引き起こしていた
to_jsonのバグ (GH 9576)GridSpecにプロットされた場合にプロット関数がIndexErrorを発生させる可能性のあるバグ (GH 10819)プロット結果が不必要な補助目盛りラベルを表示する可能性のあるバグ (GH 10657)
NaTを含むDataFrameの集計 (first、last、minなど) でgroupbyの計算が正しくないバグ。 (GH 10590, GH 11010)スカラー値のみの辞書を渡し、列を指定した場合にエラーが発生しなかった
DataFrame構築時のバグ (GH 10856)非常に類似した値に対して丸め誤差を引き起こす
.var()のバグ (GH 10242)重複する列を持つ
DataFrame.plot(subplots=True)が誤った結果を出力するバグ (GH 10962)Index算術が誤ったクラスを返す可能性のあるバグ (GH 10638)freq が負の年間、四半期、月間である場合に
date_rangeが空の結果を返すバグ (GH 11018)DatetimeIndexが負の freq を推測できないバグ (GH 11018)主にテストにおいて、一部の非推奨の numpy 比較演算子の使用を削除しました。 (GH 10569)
Indexdtype が適切に適用されない可能性のあるバグ (GH 11017)最小の Google API クライアントバージョンをテストする際の
io.gbqのバグ (GH 10652)timedeltaキーを持つネストされたdictからDataFrameを構築する際のバグ (GH 11129)データに datetime dtype が含まれている場合に
.fillnaがTypeErrorを発生させる可能性のあるバグ (GH 7095, GH 11153)グループ化するキーの数がインデックスの長さと同じ場合に
.groupbyのバグ (GH 11185)すべてが null で
coerceの場合に、変換された値が返されない可能性のあるconvert_objectsのバグ (GH 9589)copyキーワードが尊重されないconvert_objectsのバグ (GH 9589)
貢献者#
このリリースには合計112名がパッチを貢献しました。「+」が付いている名前の人は今回初めてパッチを貢献しました。
アレックス・ロスバーグ
アンドレア・ベディーニ +
アンドリュー・ローゼンフェルド
アンディ・ヘイデン
アンディ・リー +
アンソニオス・パルテニウ +
アルテム・コルチンスキー
バーナード・ウィラーズ
チャーリー・クラーク +
クリス +
クリス・ウィーラン
クリストフ・ゴールケ +
クリストファー・ウィーラン
クラーク・フィッツジェラルド
クリアフィールド・クリストファー +
ダン・リングウォルト +
ダニエル・ニー +
データ&コードエキスパート データでコードを実験中 +
デビッド・コットレル
デビッド・ジョン・ガーニュ +
デビッド・ケリー +
ETF +
エドゥアルド・シェッティーノ +
エゴール +
エゴール・パンフィロフ +
エヴァン・ライト
フランク・ピンター +
ガブリエル・アラウホ +
ギャレット-R
ジャンルカ・ロッシ +
ギョーム・ゲイ
ギョーム・プーリン
ハーシュ・ニサール +
イアン・ヘンリクセン +
イアン・ホーゲン +
ジャイデヴ・デシュパンデ +
ヤン・ルドルフ +
ヤン・シュルツ
ジェイソン・スウェイルズ +
ジェフ・リーバック
ヨナス・バイル +
Joris Van den Bossche
ジョリス・ヴァンカーシャバー +
ジョシュ・レヴィ=クレイマー +
ジュリアン・ダンジュー
カ・ウォ・チェン
キャリー・キーホー +
ケルシー・ジョーダル
カービー・シェデン
ケビン・シェパード
ラーズ・ビューティンク
リーフ・ジョンソン +
ルイス・オルティス +
マック +
マット・ガンボギ +
マット・サヴォイエ +
マシュー・ギルバート +
マキシミリアン・ルース +
ミケランジェロ・ダゴスティーノ +
モルタダ・メヒヤル
Nick Eubank
ニプン・バトラ
オンドレイ・チェルティーク
Phillip Cloud
プラタップ・ヴァルダン +
ラファル・スコラシンスキー +
リチャード・ルイス +
リノック・ジョンソン +
ロブ・レヴィ
ロバート・ギーセケ
サフィア・アブダラ +
サミュエル・デニー +
サウミトラ・シャハプール +
セバスチャン・ポエルステル +
セバスチャン・ルバート +
シェパード、ケビン +
Sinhrks
シウ・クワン・ラム +
スキッパー・シーボールド
スペンサー・カルッチュ +
ステファン・ホイヤー
スティーブン・フーバー +
スティーブン・パスコ +
テリー・サンテゴッズ +
トーマス・グレンジャー
チャーク・サンテゴッズ +
Tom Augspurger
ヴィンセント・デイビス +
ウィンターフラワー +
ヤロスラフ・ハルチェンコ
ユアン・タン(テリー) +
agijsberts
ajcr +
behzad nouri
cel4
chris-b1 +
cyrusmaher +
davidovitch +
ganego +
jreback
juricast +
larvian +
maximilianr +
msund +
rekcahpassyla
robertzk +
scls19fr
seth-p
sinhrks
springcoil +
terrytangyuan +
tzinckgraf +