0.23.0の新機能 (2018年5月15日)#
これは0.22.0からのメジャーリリースで、多数のバグ修正に加え、APIの変更、非推奨機能、新機能、機能強化、パフォーマンス改善が含まれています。すべてのユーザーにこのバージョンへのアップグレードをお勧めします。
主な機能は以下の通りです。
警告
2019年1月1日以降、pandasの機能リリースはPython 3のみをサポートします。詳細については、Python 2.7のサポート終了を参照してください。
新機能#
JSONの読み書きのラウンドトリップとorient='table'#
DataFrameは、orient='table'引数を使用することで、メタデータを保持しながらJSONに書き込み、その後読み戻すことができるようになりました(GH 18912およびGH 9146参照)。以前は、利用可能なorientの値のどれも、dtypesやインデックス名などのメタデータの保持を保証していませんでした。
In [1]: df = pd.DataFrame({'foo': [1, 2, 3, 4],
...: 'bar': ['a', 'b', 'c', 'd'],
...: 'baz': pd.date_range('2018-01-01', freq='d', periods=4),
...: 'qux': pd.Categorical(['a', 'b', 'c', 'c'])},
...: index=pd.Index(range(4), name='idx'))
...:
In [2]: df
Out[2]:
foo bar baz qux
idx
0 1 a 2018-01-01 a
1 2 b 2018-01-02 b
2 3 c 2018-01-03 c
3 4 d 2018-01-04 c
[4 rows x 4 columns]
In [3]: df.dtypes
Out[3]:
foo int64
bar object
baz datetime64[ns]
qux category
Length: 4, dtype: object
In [4]: df.to_json('test.json', orient='table')
In [5]: new_df = pd.read_json('test.json', orient='table')
In [6]: new_df
Out[6]:
foo bar baz qux
idx
0 1 a 2018-01-01 a
1 2 b 2018-01-02 b
2 3 c 2018-01-03 c
3 4 d 2018-01-04 c
[4 rows x 4 columns]
In [7]: new_df.dtypes
Out[7]:
foo int64
bar object
baz datetime64[ns]
qux category
Length: 4, dtype: object
文字列indexはラウンドトリップ形式ではサポートされていないことに注意してください。write_jsonでデフォルトで欠損インデックス名を示すために使用されるためです。
In [8]: df.index.name = 'index'
In [9]: df.to_json('test.json', orient='table')
In [10]: new_df = pd.read_json('test.json', orient='table')
In [11]: new_df
Out[11]:
foo bar baz qux
0 1 a 2018-01-01 a
1 2 b 2018-01-02 b
2 3 c 2018-01-03 c
3 4 d 2018-01-04 c
[4 rows x 4 columns]
In [12]: new_df.dtypes
Out[12]:
foo int64
bar object
baz datetime64[ns]
qux category
Length: 4, dtype: object
メソッド.assign()が依存引数を受け入れるようになりました#
DataFrame.assign()は、Pythonバージョン3.6以降で依存キーワード引数を受け入れるようになりました(PEP 468も参照)。後続のキーワード引数は、引数が呼び出し可能オブジェクトである場合、以前の引数を参照できるようになりました。詳細については、こちらのドキュメントを参照してください(GH 14207)。
In [13]: df = pd.DataFrame({'A': [1, 2, 3]})
In [14]: df
Out[14]:
A
0 1
1 2
2 3
[3 rows x 1 columns]
In [15]: df.assign(B=df.A, C=lambda x: x['A'] + x['B'])
Out[15]:
A B C
0 1 1 2
1 2 2 4
2 3 3 6
[3 rows x 3 columns]
警告
これにより、既存の列を更新するために.assign()を使用している場合、コードの動作が微妙に変わる可能性があります。以前は、更新されている他の変数を参照する呼び出し可能オブジェクトは「古い」値を取得していました。
以前の動作
In [2]: df = pd.DataFrame({"A": [1, 2, 3]})
In [3]: df.assign(A=lambda df: df.A + 1, C=lambda df: df.A * -1)
Out[3]:
A C
0 2 -1
1 3 -2
2 4 -3
新しい動作
In [16]: df.assign(A=df.A + 1, C=lambda df: df.A * -1)
Out[16]:
A C
0 2 -2
1 3 -3
2 4 -4
[3 rows x 2 columns]
列とインデックスレベルの組み合わせでのマージ#
DataFrame.merge()にon、left_on、right_onパラメータとして渡される文字列は、列名またはインデックスレベル名のいずれかを参照できるようになりました。これにより、インデックスをリセットすることなく、インデックスレベルと列の組み合わせでDataFrameインスタンスをマージすることができます。詳細は、列とレベルでのマージのドキュメントセクションを参照してください。(GH 14355)
In [17]: left_index = pd.Index(['K0', 'K0', 'K1', 'K2'], name='key1')
In [18]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3'],
....: 'key2': ['K0', 'K1', 'K0', 'K1']},
....: index=left_index)
....:
In [19]: right_index = pd.Index(['K0', 'K1', 'K2', 'K2'], name='key1')
In [20]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3'],
....: 'key2': ['K0', 'K0', 'K0', 'K1']},
....: index=right_index)
....:
In [21]: left.merge(right, on=['key1', 'key2'])
Out[21]:
A B key2 C D
key1
K0 A0 B0 K0 C0 D0
K1 A2 B2 K0 C1 D1
K2 A3 B3 K1 C3 D3
[3 rows x 5 columns]
列とインデックスレベルの組み合わせでのソート#
DataFrame.sort_values()にbyパラメータとして渡される文字列は、列名またはインデックスレベル名のいずれかを参照できるようになりました。これにより、インデックスをリセットすることなく、インデックスレベルと列の組み合わせでDataFrameインスタンスをソートすることができます。詳細は、インデックスと値によるソートのドキュメントセクションを参照してください。(GH 14353)
# Build MultiIndex
In [22]: idx = pd.MultiIndex.from_tuples([('a', 1), ('a', 2), ('a', 2),
....: ('b', 2), ('b', 1), ('b', 1)])
....:
In [23]: idx.names = ['first', 'second']
# Build DataFrame
In [24]: df_multi = pd.DataFrame({'A': np.arange(6, 0, -1)},
....: index=idx)
....:
In [25]: df_multi
Out[25]:
A
first second
a 1 6
2 5
2 4
b 2 3
1 2
1 1
[6 rows x 1 columns]
# Sort by 'second' (index) and 'A' (column)
In [26]: df_multi.sort_values(by=['second', 'A'])
Out[26]:
A
first second
b 1 1
1 2
a 1 6
b 2 3
a 2 4
2 5
[6 rows x 1 columns]
カスタム型でpandasを拡張(実験的)#
pandasは、必ずしも1次元のNumPy配列ではない配列ライクなオブジェクトを、DataFrameの列またはSeriesの値として保存することをサポートするようになりました。これにより、サードパーティライブラリは、pandasがカテゴリカル、タイムゾーン付きの日時、期間、間隔を実装したのと同様に、NumPyの型に対する拡張を実装することができます。
デモンストレーションとして、IPアドレスを保存するためのIPArray型を提供するcyberpandasを使用します。
In [1]: from cyberpandas import IPArray
In [2]: values = IPArray([
...: 0,
...: 3232235777,
...: 42540766452641154071740215577757643572
...: ])
...:
...:
IPArrayは通常の1次元NumPy配列ではありませんが、pandasのExtensionArrayであるため、pandasのコンテナ内に適切に保存できます。
In [3]: ser = pd.Series(values)
In [4]: ser
Out[4]:
0 0.0.0.0
1 192.168.1.1
2 2001:db8:85a3::8a2e:370:7334
dtype: ip
dtypeがipであることに注目してください。基盤となる配列の欠損値セマンティクスが尊重されます。
In [5]: ser.isna()
Out[5]:
0 True
1 False
2 False
dtype: bool
詳細については、拡張型のドキュメントを参照してください。拡張配列を構築した場合は、エコシステムページで公開してください。
GroupByで未観測カテゴリを除外するための新しいキーワードobserved#
カテゴリカルによるグループ化は、未観測カテゴリを出力に含めます。複数のカテゴリカル列でグループ化する場合、これはすべてのカテゴリのデカルト積を取得することを意味し、観測値がない組み合わせも含まれるため、多数のグループが生成される可能性があります。この動作を制御するためにキーワードobservedを追加しました。下位互換性のためにデフォルトはobserved=Falseです。(GH 14942、GH 8138、GH 15217、GH 17594、GH 8669、GH 20583、GH 20902)
In [27]: cat1 = pd.Categorical(["a", "a", "b", "b"],
....: categories=["a", "b", "z"], ordered=True)
....:
In [28]: cat2 = pd.Categorical(["c", "d", "c", "d"],
....: categories=["c", "d", "y"], ordered=True)
....:
In [29]: df = pd.DataFrame({"A": cat1, "B": cat2, "values": [1, 2, 3, 4]})
In [30]: df['C'] = ['foo', 'bar'] * 2
In [31]: df
Out[31]:
A B values C
0 a c 1 foo
1 a d 2 bar
2 b c 3 foo
3 b d 4 bar
[4 rows x 4 columns]
すべての値を表示する場合(以前の動作)
In [32]: df.groupby(['A', 'B', 'C'], observed=False).count()
Out[32]:
values
A B C
a c bar 0
foo 1
d bar 1
foo 0
y bar 0
... ...
z c foo 0
d bar 0
foo 0
y bar 0
foo 0
[18 rows x 1 columns]
観測された値のみを表示する場合
In [33]: df.groupby(['A', 'B', 'C'], observed=True).count()
Out[33]:
values
A B C
a c foo 1
d bar 1
b c foo 1
d bar 1
[4 rows x 1 columns]
ピボット操作の場合、この動作はdropnaキーワードによってすでに制御されています。
In [34]: cat1 = pd.Categorical(["a", "a", "b", "b"],
....: categories=["a", "b", "z"], ordered=True)
....:
In [35]: cat2 = pd.Categorical(["c", "d", "c", "d"],
....: categories=["c", "d", "y"], ordered=True)
....:
In [36]: df = pd.DataFrame({"A": cat1, "B": cat2, "values": [1, 2, 3, 4]})
In [37]: df
Out[37]:
A B values
0 a c 1
1 a d 2
2 b c 3
3 b d 4
[4 rows x 3 columns]
In [1]: pd.pivot_table(df, values='values', index=['A', 'B'], dropna=True)
Out[1]:
values
A B
a c 1.0
d 2.0
b c 3.0
d 4.0
In [2]: pd.pivot_table(df, values='values', index=['A', 'B'], dropna=False)
Out[2]:
values
A B
a c 1.0
d 2.0
y NaN
b c 3.0
d 4.0
y NaN
z c NaN
d NaN
y NaN
Rolling/Expanding.apply()がraw=Falseを受け入れ、関数にSeriesを渡すように#
Series.rolling().apply()、DataFrame.rolling().apply()、Series.expanding().apply()、およびDataFrame.expanding().apply()にraw=Noneパラメータが追加されました。これはDataFame.apply()と同様です。このパラメータがTrueの場合、適用される関数にnp.ndarrayを送信できます。Falseの場合、Seriesが渡されます。デフォルトはNoneで、これは下位互換性を保持するため、Trueにデフォルト設定され、np.ndarrayが送信されます。将来のバージョンでは、デフォルトはFalseに変更され、Seriesが送信されます。(GH 5071、GH 20584)
In [38]: s = pd.Series(np.arange(5), np.arange(5) + 1)
In [39]: s
Out[39]:
1 0
2 1
3 2
4 3
5 4
Length: 5, dtype: int64
Seriesを渡す
In [40]: s.rolling(2, min_periods=1).apply(lambda x: x.iloc[-1], raw=False)
Out[40]:
1 0.0
2 1.0
3 2.0
4 3.0
5 4.0
Length: 5, dtype: float64
ndarrayを渡す元の動作を模倣する
In [41]: s.rolling(2, min_periods=1).apply(lambda x: x[-1], raw=True)
Out[41]:
1 0.0
2 1.0
3 2.0
4 3.0
5 4.0
Length: 5, dtype: float64
DataFrame.interpolateにlimit_areaキーワード引数が追加されました#
DataFrame.interpolate()に、置き換えられるNaNをさらに制御するためのlimit_areaパラメータが追加されました。limit_area='inside'を使用すると、有効な値に囲まれたNaNのみを埋め、limit_area='outside'を使用すると、既存の有効な値の外側のNaNのみを埋め、内側のNaNは保持します。(GH 16284)詳細については、こちらの完全なドキュメントを参照してください。
In [42]: ser = pd.Series([np.nan, np.nan, 5, np.nan, np.nan,
....: np.nan, 13, np.nan, np.nan])
....:
In [43]: ser
Out[43]:
0 NaN
1 NaN
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 NaN
8 NaN
Length: 9, dtype: float64
両方向に1つの連続した内部値を埋める
In [44]: ser.interpolate(limit_direction='both', limit_area='inside', limit=1)
Out[44]:
0 NaN
1 NaN
2 5.0
3 7.0
4 NaN
5 11.0
6 13.0
7 NaN
8 NaN
Length: 9, dtype: float64
すべての連続した外部値を逆方向に埋める
In [45]: ser.interpolate(limit_direction='backward', limit_area='outside')
Out[45]:
0 5.0
1 5.0
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 NaN
8 NaN
Length: 9, dtype: float64
すべての連続した外部値を両方向に埋める
In [46]: ser.interpolate(limit_direction='both', limit_area='outside')
Out[46]:
0 5.0
1 5.0
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 13.0
8 13.0
Length: 9, dtype: float64
関数get_dummiesがdtype引数をサポートするようになりました#
get_dummies()は、新しい列のdtypeを指定するdtype引数を受け入れるようになりました。デフォルトはuint8のままです。(GH 18330)
In [47]: df = pd.DataFrame({'a': [1, 2], 'b': [3, 4], 'c': [5, 6]})
In [48]: pd.get_dummies(df, columns=['c']).dtypes
Out[48]:
a int64
b int64
c_5 bool
c_6 bool
Length: 4, dtype: object
In [49]: pd.get_dummies(df, columns=['c'], dtype=bool).dtypes
Out[49]:
a int64
b int64
c_5 bool
c_6 bool
Length: 4, dtype: object
Timedeltaのmodメソッド#
mod (%) および divmod 演算が、timedelta-like または数値引数で操作する場合に Timedelta オブジェクトで定義されるようになりました。詳細については、こちらのドキュメントを参照してください。(GH 19365)
In [50]: td = pd.Timedelta(hours=37)
In [51]: td % pd.Timedelta(minutes=45)
Out[51]: Timedelta('0 days 00:15:00')
メソッド.rank()がNaNが存在する場合でもinf値を処理するようになりました#
以前のバージョンでは、.rank()はinf要素にNaNをランクとして割り当てていました。現在はランクが正しく計算されます。(GH 6945)
In [52]: s = pd.Series([-np.inf, 0, 1, np.nan, np.inf])
In [53]: s
Out[53]:
0 -inf
1 0.0
2 1.0
3 NaN
4 inf
Length: 5, dtype: float64
以前の動作
In [11]: s.rank()
Out[11]:
0 1.0
1 2.0
2 3.0
3 NaN
4 NaN
dtype: float64
現在の動作
In [54]: s.rank()
Out[54]:
0 1.0
1 2.0
2 3.0
3 NaN
4 4.0
Length: 5, dtype: float64
さらに、以前はinfまたは-inf値とNaN値を一緒にランク付けすると、'top'または'bottom'引数を使用した場合にNaNと無限大を区別できませんでした。
In [55]: s = pd.Series([np.nan, np.nan, -np.inf, -np.inf])
In [56]: s
Out[56]:
0 NaN
1 NaN
2 -inf
3 -inf
Length: 4, dtype: float64
以前の動作
In [15]: s.rank(na_option='top')
Out[15]:
0 2.5
1 2.5
2 2.5
3 2.5
dtype: float64
現在の動作
In [57]: s.rank(na_option='top')
Out[57]:
0 1.5
1 1.5
2 3.5
3 3.5
Length: 4, dtype: float64
これらのバグは修正されました
DataFrame.rank()およびSeries.rank()で、method='dense'およびpct=Trueの場合に、パーセンタイルランクが個別の観測値の数で使われていなかったバグ (GH 15630)Series.rank()およびDataFrame.rank()で、ascending='False'がNaNが存在する場合に無限大に対して正しいランクを返せなかったバグ (GH 19538)DataFrameGroupBy.rank()で、無限大とNaNの両方が存在する場合にランクが正しくなかったバグ (GH 20561)
Series.str.catにjoinキーワード引数が追加されました#
以前は、Series.str.cat()は、ほとんどのpandasとは対照的に、連結前にSeriesをインデックスで揃えませんでした(GH 18657参照)。このメソッドには、アライメントの方法を制御するためのキーワードjoinが追加されました。以下の例とこちらを参照してください。
v.0.23ではjoinのデフォルトはNone(アライメントなしを意味します)ですが、将来のバージョンのpandasではこのデフォルトは'left'に変更されます。
In [58]: s = pd.Series(['a', 'b', 'c', 'd'])
In [59]: t = pd.Series(['b', 'd', 'e', 'c'], index=[1, 3, 4, 2])
In [60]: s.str.cat(t)
Out[60]:
0 NaN
1 bb
2 cc
3 dd
Length: 4, dtype: object
In [61]: s.str.cat(t, join='left', na_rep='-')
Out[61]:
0 a-
1 bb
2 cc
3 dd
Length: 4, dtype: object
さらに、Series.str.cat()はCategoricalIndexでも動作するようになりました(以前はValueErrorが発生していました。GH 20842参照)。
DataFrame.astypeがCategoricalへの列ごとの変換を実行するようになりました#
DataFrame.astype()は、文字列'category'またはCategoricalDtypeを指定することで、Categoricalへの列ごとの変換を実行できるようになりました。以前は、これを試みるとNotImplementedErrorが発生していました。詳細および例については、ドキュメントのオブジェクト作成セクションを参照してください。(GH 12860、GH 18099)
文字列'category'を指定すると、列ごとの変換が実行され、特定の列に表示されるラベルのみがカテゴリとして設定されます。
In [62]: df = pd.DataFrame({'A': list('abca'), 'B': list('bccd')})
In [63]: df = df.astype('category')
In [64]: df['A'].dtype
Out[64]: CategoricalDtype(categories=['a', 'b', 'c'], ordered=False, categories_dtype=object)
In [65]: df['B'].dtype
Out[65]: CategoricalDtype(categories=['b', 'c', 'd'], ordered=False, categories_dtype=object)
CategoricalDtypeを指定すると、各列のカテゴリは指定されたdtypeと一致するようになります。
In [66]: from pandas.api.types import CategoricalDtype
In [67]: df = pd.DataFrame({'A': list('abca'), 'B': list('bccd')})
In [68]: cdt = CategoricalDtype(categories=list('abcd'), ordered=True)
In [69]: df = df.astype(cdt)
In [70]: df['A'].dtype
Out[70]: CategoricalDtype(categories=['a', 'b', 'c', 'd'], ordered=True, categories_dtype=object)
In [71]: df['B'].dtype
Out[71]: CategoricalDtype(categories=['a', 'b', 'c', 'd'], ordered=True, categories_dtype=object)
その他の機能強化#
単項
+が数値演算子としてSeriesとDataFrameで許可されるようになりました(GH 16073)xlsxwriterエンジンを使用したto_excel()出力のサポートが改善されました。(GH 16149)pandas.tseries.frequencies.to_offset()が先行する「+」記号、例:「+1h」を受け入れるようになりました。(GH 18171)MultiIndex.unique()がlevel=引数をサポートし、特定のインデックスレベルから一意の値を取得できるようになりました(GH 17896)pandas.io.formats.style.Stylerに、インデックスが出力にレンダリングされるかどうかを決定するメソッドhide_index()が追加されました(GH 14194)pandas.io.formats.style.Stylerに、列が出力で非表示になるかどうかを決定するメソッドhide_columns()が追加されました(GH 14194)to_datetime()でunit=が変換不可能な値で渡された場合に発生するValueErrorの文言が改善されました(GH 14350)Series.fillna()がカテゴリカルdtypeのvalueとしてSeriesまたは辞書を受け入れるようになりました(GH 17033)pandas.read_clipboard()がqtpyを使用するように更新され、PyQt5、次にPyQt4にフォールバックすることで、Python3と複数のpython-qtバインディングとの互換性が追加されました(GH 17722)read_csv()でusecols引数がすべての列と一致しない場合に発生するValueErrorの文言が改善されました。(GH 17301)DataFrame.corrwith()は、Seriesが渡されたときに非数値列をサイレントに削除するようになりました。以前は例外が発生していました(GH 18570)。IntervalIndexがタイムゾーン認識のIntervalオブジェクトをサポートするようになりました(GH 18537、GH 18538)Series()/DataFrame()のタブ補完が、MultiIndex()の最初のレベルの識別子も返すようになりました。(GH 16326)read_excel()にnrowsパラメータが追加されました(GH 16645)DataFrame.append()は、呼び出し元のデータフレームの列の型をより多くのケースで保持できるようになりました(例:両方がCategoricalIndexの場合)。 (GH 18359)DataFrame.to_json()とSeries.to_json()がindex引数を受け入れるようになり、ユーザーはJSON出力からインデックスを除外できるようになりました(GH 17394)IntervalIndex.to_tuples()にna_tupleパラメータが追加され、NAをタプルのNAとして返すか、NA自体として返すかを制御できるようになりました(GH 18756)Categorical.rename_categories、CategoricalIndex.rename_categories、およびSeries.cat.rename_categoriesが引数として呼び出し可能オブジェクトを受け入れるようになりました(GH 18862)IntervalとIntervalIndexにlength属性が追加されました(GH 18789)Resamplerオブジェクトに、機能するResampler.pipeメソッドが追加されました。以前は、pipeへの呼び出しはmeanメソッドに転送されていました(GH 17905)。is_scalar()はDateOffsetオブジェクトに対してTrueを返すようになりました(GH 18943)。DataFrame.pivot()はvalues=キーワード引数としてリストを受け入れるようになりました(GH 17160)。pandas.api.extensions.register_dataframe_accessor()、pandas.api.extensions.register_series_accessor()、およびpandas.api.extensions.register_index_accessor()が追加されました。これらは、pandasオブジェクトに.catのようなカスタムアクセサを登録するためのpandas下流ライブラリ用アクセサです。詳細については、カスタムアクセサの登録を参照してください(GH 14781)。IntervalIndex.astypeがIntervalDtypeを渡された場合にサブタイプ間の変換をサポートするようになりました(GH 19197)IntervalIndexとその関連コンストラクタメソッド(from_arrays、from_breaks、from_tuples)にdtypeパラメータが追加されました(GH 19262)SeriesGroupBy.is_monotonic_increasing()およびSeriesGroupBy.is_monotonic_decreasing()が追加されました(GH 17015)サブクラス化された
DataFramesの場合、DataFrame.apply()は、データを適用された関数に渡す際に、Seriesサブクラス(定義されている場合)を保持するようになりました(GH 19822)DataFrame.from_dict()がcolumns引数を受け入れるようになりました。これは、orient='index'が使用される場合に列名を指定するために使用できます(GH 18529)オプション
display.html.use_mathjaxが追加され、Jupyterノートブックでテーブルをレンダリングする際にMathJaxを無効にできるようになりました(GH 19856、GH 19824)DataFrame.replace()がmethodパラメータをサポートするようになりました。これは、to_replaceがスカラ、リスト、またはタプルで、valueがNoneの場合に置換方法を指定するために使用できます(GH 19632)Timestamp.month_name()、DatetimeIndex.month_name()、およびSeries.dt.month_name()が利用可能になりました(GH 12805)Timestamp.day_name()およびDatetimeIndex.day_name()が利用可能になり、指定されたロケールで曜日名を返すようになりました(GH 12806)DataFrame.to_sql()は、基盤となる接続がサポートしていれば、行ごとに挿入するのではなく、複数値挿入を実行するようになりました。SQLAlchemyの複数値挿入をサポートする方言には、mysql、postgresql、sqlite、およびsupports_multivalues_insertを持つすべての方言が含まれます。(GH 14315、GH 8953)read_html()がdisplayed_onlyキーワード引数を受け入れるようになり、非表示要素が解析されるかどうかを制御します(デフォルトはTrue)。(GH 20027)read_html()は、最初の<tbody>要素だけでなく、<table>内のすべての<tbody>要素を読み取るようになりました。(GH 20690)Rolling.quantile()およびExpanding.quantile()がinterpolationキーワードを受け入れるようになり、デフォルトはlinearです(GH 20497)DataFrame.to_pickle()、Series.to_pickle()、DataFrame.to_csv()、Series.to_csv()、DataFrame.to_json()、Series.to_json()でcompression=zipを介してzip圧縮がサポートされました。(GH 17778)WeekOfMonthコンストラクタがn=0をサポートするようになりました(GH 20517)。DataFrameおよびSeriesが、Python>=3.5で行列乗算(@)演算子をサポートするようになりました(GH 10259)DataFrame.to_gbq()およびpandas.read_gbq()のシグネチャとドキュメントが、pandas-gbqライブラリバージョン0.4.0の変更を反映するように更新されました。pandas-gbqライブラリへのintersphinxマッピングが追加されました。(GH 20564)バージョン117でStata dtaファイルをエクスポートするための新しいライター、
StataWriter117が追加されました。この形式は、最大2,000,000文字の長さの文字列のエクスポートをサポートします(GH 16450)to_hdf()およびread_hdf()が、エンコーディングエラー処理を制御するためのerrorsキーワード引数を受け入れるようになりました(GH 20835)cut()がduplicates='raise'|'drop'オプションを獲得し、重複するエッジでエラーを発生させるか制御できるようになりました(GH 20947)date_range()、timedelta_range()、およびinterval_range()は、start、stop、periodsが指定され、freqが指定されていない場合、線形間隔のインデックスを返すようになりました。(GH 20808、GH 20983、GH 20976)
下位互換性のない API の変更#
依存関係の最小バージョンが上がりました#
依存関係のサポートされる最小バージョンを更新しました(GH 15184)。インストールされている場合、現在は以下が必要です。
パッケージ |
最小バージョン |
必須 |
問題 |
|---|---|---|---|
python-dateutil |
2.5.0 |
X |
|
openpyxl |
2.4.0 |
||
beautifulsoup4 |
4.2.1 |
||
setuptools |
24.2.0 |
Python 3.6+での辞書からのインスタンス化は、辞書の挿入順序を保持します#
Python 3.6までは、Pythonの辞書には正式に定義された順序がありませんでした。Python 3.6以降のバージョンでは、辞書は挿入順序によって並べ替えられます(PEP 468を参照)。Python 3.6以降のバージョンを使用している場合、pandasは辞書からSeriesまたはDataFrameを作成する際に、辞書の挿入順序を使用します。(GH 19884)
以前の動作(およびPython < 3.6での現在の動作)
In [16]: pd.Series({'Income': 2000,
....: 'Expenses': -1500,
....: 'Taxes': -200,
....: 'Net result': 300})
Out[16]:
Expenses -1500
Income 2000
Net result 300
Taxes -200
dtype: int64
上記のSeriesは、インデックス値によってアルファベット順に並べ替えられていることに注目してください。
新しい動作(Python >= 3.6の場合)
In [72]: pd.Series({'Income': 2000,
....: 'Expenses': -1500,
....: 'Taxes': -200,
....: 'Net result': 300})
....:
Out[72]:
Income 2000
Expenses -1500
Taxes -200
Net result 300
Length: 4, dtype: int64
Seriesが挿入順序で並べ替えられていることに注目してください。この新しい動作は、すべての関連するpandas型(Series、DataFrame、SparseSeries、SparseDataFrame)で使用されます。
Python >= 3.6を使用しながら古い動作を保持したい場合は、.sort_index()を使用できます。
In [73]: pd.Series({'Income': 2000,
....: 'Expenses': -1500,
....: 'Taxes': -200,
....: 'Net result': 300}).sort_index()
....:
Out[73]:
Expenses -1500
Income 2000
Net result 300
Taxes -200
Length: 4, dtype: int64
Panelを非推奨化#
Panelは0.20.xリリースで非推奨となり、DeprecationWarningとして表示されていました。Panelを使用すると、今後はFutureWarningが表示されます。3次元データを表現する推奨される方法は、to_frame()を介してDataFrame上にMultiIndexを使用するか、xarrayパッケージを使用することです。pandasは、この変換を自動化するためのto_xarray()メソッドを提供します(GH 13563、GH 18324)。
In [75]: import pandas._testing as tm
In [76]: p = tm.makePanel()
In [77]: p
Out[77]:
<class 'pandas.core.panel.Panel'>
Dimensions: 3 (items) x 3 (major_axis) x 4 (minor_axis)
Items axis: ItemA to ItemC
Major_axis axis: 2000-01-03 00:00:00 to 2000-01-05 00:00:00
Minor_axis axis: A to D
MultiIndex DataFrameに変換
In [78]: p.to_frame()
Out[78]:
ItemA ItemB ItemC
major minor
2000-01-03 A 0.469112 0.721555 0.404705
B -1.135632 0.271860 -1.039268
C 0.119209 0.276232 -1.344312
D -2.104569 0.113648 -0.109050
2000-01-04 A -0.282863 -0.706771 0.577046
B 1.212112 -0.424972 -0.370647
C -1.044236 -1.087401 0.844885
D -0.494929 -1.478427 1.643563
2000-01-05 A -1.509059 -1.039575 -1.715002
B -0.173215 0.567020 -1.157892
C -0.861849 -0.673690 1.075770
D 1.071804 0.524988 -1.469388
[12 rows x 3 columns]
xarray DataArrayに変換
In [79]: p.to_xarray()
Out[79]:
<xarray.DataArray (items: 3, major_axis: 3, minor_axis: 4)>
array([[[ 0.469112, -1.135632, 0.119209, -2.104569],
[-0.282863, 1.212112, -1.044236, -0.494929],
[-1.509059, -0.173215, -0.861849, 1.071804]],
[[ 0.721555, 0.27186 , 0.276232, 0.113648],
[-0.706771, -0.424972, -1.087401, -1.478427],
[-1.039575, 0.56702 , -0.67369 , 0.524988]],
[[ 0.404705, -1.039268, -1.344312, -0.10905 ],
[ 0.577046, -0.370647, 0.844885, 1.643563],
[-1.715002, -1.157892, 1.07577 , -1.469388]]])
Coordinates:
* items (items) object 'ItemA' 'ItemB' 'ItemC'
* major_axis (major_axis) datetime64[ns] 2000-01-03 2000-01-04 2000-01-05
* minor_axis (minor_axis) object 'A' 'B' 'C' 'D'
pandas.core.commonの削除#
以下のエラー&警告メッセージがpandas.core.commonから削除されました(GH 13634、GH 19769)
PerformanceWarningUnsupportedFunctionCallUnsortedIndexErrorAbstractMethodError
これらはpandas.errorsからインポートして利用できます (0.19.0以降)。
DataFrame.applyの出力を統一するための変更#
DataFrame.apply()は、axis=1でリストライクなものを返す任意のユーザー定義関数を適用する場合に一貫性がありませんでした。いくつかのバグと不整合が解決されました。適用される関数がSeriesを返す場合、pandasはDataFrameを返します。それ以外の場合、Seriesが返され、これにはリストライクなもの(例:tupleまたはlistが返される場合)も含まれます。(GH 16353、GH 17437、GH 17970、GH 17348、GH 17892、GH 18573、GH 17602、GH 18775、GH 18901、GH 18919)。
In [74]: df = pd.DataFrame(np.tile(np.arange(3), 6).reshape(6, -1) + 1,
....: columns=['A', 'B', 'C'])
....:
In [75]: df
Out[75]:
A B C
0 1 2 3
1 1 2 3
2 1 2 3
3 1 2 3
4 1 2 3
5 1 2 3
[6 rows x 3 columns]
以前の動作: 戻り値の形状が元の列の長さと一致する場合、DataFrameが返されました。戻り値の形状が一致しない場合、リストを含むSeriesが返されました。
In [3]: df.apply(lambda x: [1, 2, 3], axis=1)
Out[3]:
A B C
0 1 2 3
1 1 2 3
2 1 2 3
3 1 2 3
4 1 2 3
5 1 2 3
In [4]: df.apply(lambda x: [1, 2], axis=1)
Out[4]:
0 [1, 2]
1 [1, 2]
2 [1, 2]
3 [1, 2]
4 [1, 2]
5 [1, 2]
dtype: object
新しい動作: 適用される関数がリストライクなものを返す場合、常にSeriesを返すようになります。
In [76]: df.apply(lambda x: [1, 2, 3], axis=1)
Out[76]:
0 [1, 2, 3]
1 [1, 2, 3]
2 [1, 2, 3]
3 [1, 2, 3]
4 [1, 2, 3]
5 [1, 2, 3]
Length: 6, dtype: object
In [77]: df.apply(lambda x: [1, 2], axis=1)
Out[77]:
0 [1, 2]
1 [1, 2]
2 [1, 2]
3 [1, 2]
4 [1, 2]
5 [1, 2]
Length: 6, dtype: object
列を展開するには、result_type='expand'を使用できます。
In [78]: df.apply(lambda x: [1, 2, 3], axis=1, result_type='expand')
Out[78]:
0 1 2
0 1 2 3
1 1 2 3
2 1 2 3
3 1 2 3
4 1 2 3
5 1 2 3
[6 rows x 3 columns]
元の列全体に結果をブロードキャストする(正しい長さのリストライクなもののための古い動作)には、result_type='broadcast'を使用できます。形状は元の列と一致する必要があります。
In [79]: df.apply(lambda x: [1, 2, 3], axis=1, result_type='broadcast')
Out[79]:
A B C
0 1 2 3
1 1 2 3
2 1 2 3
3 1 2 3
4 1 2 3
5 1 2 3
[6 rows x 3 columns]
Seriesを返すことで、正確な戻り構造と列名を制御できます。
In [80]: df.apply(lambda x: pd.Series([1, 2, 3], index=['D', 'E', 'F']), axis=1)
Out[80]:
D E F
0 1 2 3
1 1 2 3
2 1 2 3
3 1 2 3
4 1 2 3
5 1 2 3
[6 rows x 3 columns]
連結はソートされなくなります#
将来のバージョンのpandasでは、pandas.concat()は、非連結軸がすでに整列されていない場合、その軸をソートしなくなります。現在の動作は以前と同じ(ソート)ですが、sortが指定されておらず、非連結軸が整列されていない場合に警告が発行されます(GH 4588)。
In [81]: df1 = pd.DataFrame({"a": [1, 2], "b": [1, 2]}, columns=['b', 'a'])
In [82]: df2 = pd.DataFrame({"a": [4, 5]})
In [83]: pd.concat([df1, df2])
Out[83]:
b a
0 1.0 1
1 2.0 2
0 NaN 4
1 NaN 5
[4 rows x 2 columns]
以前の動作(ソート)を維持し、警告を抑制するには、sort=Trueを渡します。
In [84]: pd.concat([df1, df2], sort=True)
Out[84]:
a b
0 1 1.0
1 2 2.0
0 4 NaN
1 5 NaN
[4 rows x 2 columns]
将来の動作(ソートしない)を受け入れるには、sort=Falseを渡します。
この変更はDataFrame.append()にも適用されることに注意してください。このメソッドには、この動作を制御するためのsortキーワードも追加されています。
ビルドの変更#
インデックスのゼロ除算が正しく埋められる#
Indexとそのサブクラスに対する除算演算では、正の数をゼロで割るとnp.inf、負の数をゼロで割ると-np.inf、0 / 0はnp.nanで埋められるようになりました。これは既存のSeriesの動作と一致します。(GH 19322、GH 19347)
以前の動作
In [6]: index = pd.Int64Index([-1, 0, 1])
In [7]: index / 0
Out[7]: Int64Index([0, 0, 0], dtype='int64')
# Previous behavior yielded different results depending on the type of zero in the divisor
In [8]: index / 0.0
Out[8]: Float64Index([-inf, nan, inf], dtype='float64')
In [9]: index = pd.UInt64Index([0, 1])
In [10]: index / np.array([0, 0], dtype=np.uint64)
Out[10]: UInt64Index([0, 0], dtype='uint64')
In [11]: pd.RangeIndex(1, 5) / 0
ZeroDivisionError: integer division or modulo by zero
現在の動作
In [12]: index = pd.Int64Index([-1, 0, 1])
# division by zero gives -infinity where negative,
# +infinity where positive, and NaN for 0 / 0
In [13]: index / 0
# The result of division by zero should not depend on
# whether the zero is int or float
In [14]: index / 0.0
In [15]: index = pd.UInt64Index([0, 1])
In [16]: index / np.array([0, 0], dtype=np.uint64)
In [17]: pd.RangeIndex(1, 5) / 0
文字列からの一致パターンの抽出#
以前は、str.extract()で文字列から一致するパターンを抽出する場合、単一のグループが抽出されるとSeriesが返され(複数のグループが抽出されるとDataFrameが返されました)。pandas 0.23.0以降、str.extract()は、expandがFalseに設定されていない限り、常にDataFrameを返します。最後に、Noneはexpandパラメータの許容値でしたが(これはFalseと同等でした)、現在はValueErrorが発生します。(GH 11386)
以前の動作
In [1]: s = pd.Series(['number 10', '12 eggs'])
In [2]: extracted = s.str.extract(r'.*(\d\d).*')
In [3]: extracted
Out [3]:
0 10
1 12
dtype: object
In [4]: type(extracted)
Out [4]:
pandas.core.series.Series
新しい動作
In [85]: s = pd.Series(['number 10', '12 eggs'])
In [86]: extracted = s.str.extract(r'.*(\d\d).*')
In [87]: extracted
Out[87]:
0
0 10
1 12
[2 rows x 1 columns]
In [88]: type(extracted)
Out[88]: pandas.core.frame.DataFrame
以前の動作を復元するには、expandをFalseに設定するだけです。
In [89]: s = pd.Series(['number 10', '12 eggs'])
In [90]: extracted = s.str.extract(r'.*(\d\d).*', expand=False)
In [91]: extracted
Out[91]:
0 10
1 12
Length: 2, dtype: object
In [92]: type(extracted)
Out[92]: pandas.core.series.Series
CategoricalDtypeのorderedパラメータのデフォルト値#
CategoricalDtypeのorderedパラメータのデフォルト値がFalseからNoneに変更され、orderedに影響を与えずにcategoriesを更新できるようになりました。Categoricalなどの下流オブジェクトの動作は一貫しているはずです(GH 18790)。
以前のバージョンでは、orderedパラメータのデフォルト値はFalseでした。これにより、ユーザーがorderedが明示的に指定されていない場合にcategoriesを更新しようとすると、orderedパラメータが意図せずにTrueからFalseに変更される可能性がありました。これは、暗黙的にFalseにデフォルト設定されていたためです。ordered=Noneの新しい動作は、orderedの既存の値を保持することです。
新しい動作
In [2]: from pandas.api.types import CategoricalDtype
In [3]: cat = pd.Categorical(list('abcaba'), ordered=True, categories=list('cba'))
In [4]: cat
Out[4]:
[a, b, c, a, b, a]
Categories (3, object): [c < b < a]
In [5]: cdt = CategoricalDtype(categories=list('cbad'))
In [6]: cat.astype(cdt)
Out[6]:
[a, b, c, a, b, a]
Categories (4, object): [c < b < a < d]
上記の例では、変換されたCategoricalがordered=Trueを保持していることに注目してください。orderedのデフォルト値がFalseのままであった場合、ordered=Falseが明示的に指定されていなかったにもかかわらず、変換されたCategoricalは順序なしになっていたでしょう。orderedの値を変更するには、新しいdtypeに明示的に渡してください。例:CategoricalDtype(categories=list('cbad'), ordered=False)。
上記で議論したorderedの意図しない変換は、astypeがカテゴリからカテゴリへの変換を行うのを妨げていた別のバグ(GH 10696、GH 18593)のため、以前のバージョンでは発生しませんでした。これらのバグはこのリリースで修正され、orderedのデフォルト値の変更を促しました。
ターミナルでのDataFrameのより良い整形出力#
以前は、最大列数のデフォルト値はpd.options.display.max_columns=20でした。これは、比較的幅の広いデータフレームがターミナルの幅に収まらず、pandasがこれらの20列を表示するために改行を導入することを意味していました。これにより、比較的読みにくい出力になっていました。
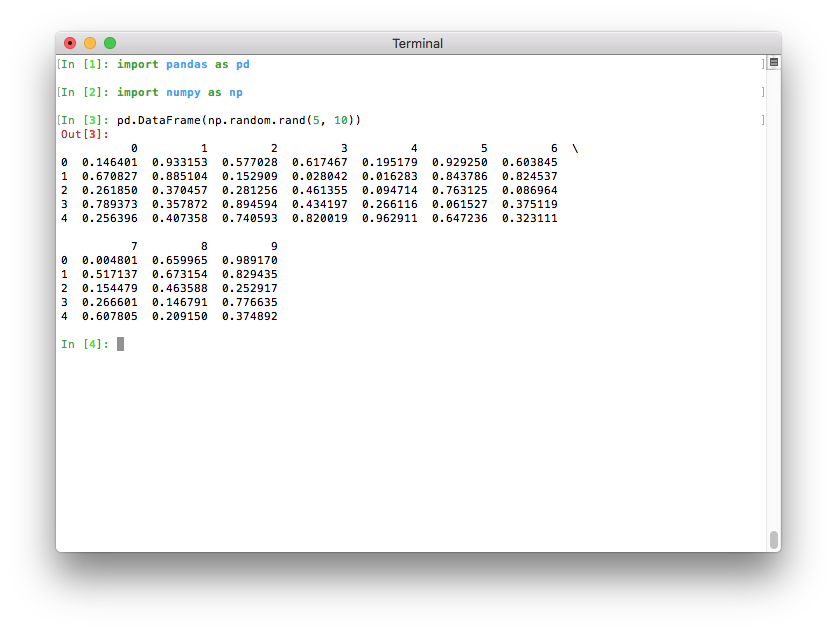
Pythonがターミナルで実行されている場合、印刷されるデータフレームが現在のターミナル幅に収まるように、最大列数が自動的に決定されるようになりました(pd.options.display.max_columns=0)(GH 17023)。PythonがJupyterカーネル(Jupyter QtConsoleやJupyterノートブック、多くのIDEなど)として実行されている場合、この値は自動的に推測できないため、以前のバージョンと同様に20に設定されます。ターミナルでは、これによりはるかに見やすい出力が得られます。
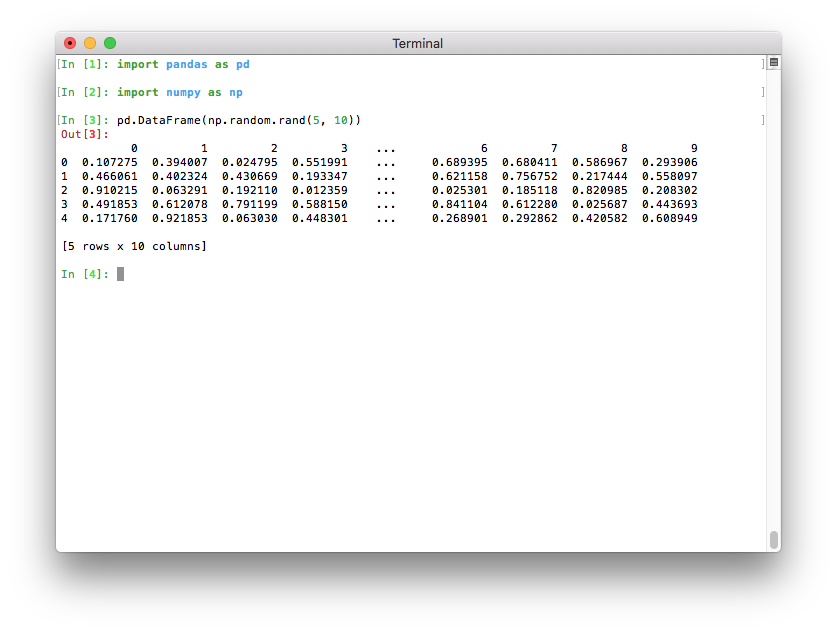
新しいデフォルトが気に入らない場合でも、常にこのオプションを自分で設定できることに注意してください。古い設定に戻すには、この行を実行できます。
pd.options.display.max_columns = 20
Datetimelike APIの変更#
デフォルトの
Timedeltaコンストラクタが引数としてISO 8601 Duration文字列を受け入れるようになりました(GH 19040)dtype='datetime64[ns]'のSeriesからNaTを減算すると、dtype='datetime64[ns]'の代わりにdtype='timedelta64[ns]'のSeriesが返されるようになりました(GH 18808)TimedeltaIndexからNaTの加算または減算は、DatetimeIndexではなくTimedeltaIndexを返します(GH 19124)DatetimeIndex.shift()とTimedeltaIndex.shift()は、インデックスオブジェクトの周波数がNoneの場合に、NullFrequencyError(以前のバージョンで発生していたValueErrorのサブクラス)を発生させるようになりました(GH 19147)dtype='timedelta64[ns]'のSeriesからのNaNの加算または減算は、NaNをNaTとして扱うのではなく、TypeErrorを発生させるようになりました(GH 19274)NaTとdatetime.timedeltaの除算は、例外を発生させるのではなく、NaNを返すようになりました(GH 17876)dtype='datetime64[ns]'のSeriesとPeriodIndex間の操作は、正しくTypeErrorを発生させるようになりました(GH 18850)タイムゾーン対応の
dtype='datetime64[ns]'を持つSeriesの減算で、タイムゾーンが不一致の場合、ValueErrorではなくTypeErrorが発生するようになりました(GH 18817)Timestampは、未使用または無効なtzまたはtzinfoキーワード引数を黙って無視しなくなりました(GH 17690)CacheableOffsetおよびWeekDayは、pandas.tseries.offsetsモジュールで利用できなくなりました(GH 17830)pandas.tseries.frequencies.get_freq_group()とpandas.tseries.frequencies.DAYSは公開APIから削除されました(GH 18034)Series.truncate()およびDataFrame.truncate()は、インデックスがソートされていない場合に、役に立たないKeyErrorではなく、ValueErrorを発生させるようになりました(GH 17935)Series.firstおよびDataFrame.firstは、インデックスがDatetimeIndexではない場合に、NotImplementedErrorではなくTypeErrorを発生させるようになりました(GH 20725)。Series.lastおよびDataFrame.lastは、インデックスがDatetimeIndexではない場合に、NotImplementedErrorではなくTypeErrorを発生させるようになりました(GH 20725)。DateOffsetキーワード引数が制限されました。以前は、DateOffsetのサブクラスは任意のキーワード引数を許可しており、予期しない動作につながる可能性がありました。現在は、有効な引数のみが受け入れられます。(GH 17176、GH 18226)。pandas.merge()は、タイムゾーン対応とタイムゾーン非対応の列をマージしようとした場合に、より情報量の多いエラーメッセージを提供するようになりました(GH 15800)freq=NoneのDatetimeIndexおよびTimedeltaIndexにおいて、整数型の配列またはIndexの加算または減算は、TypeErrorではなくNullFrequencyErrorを発生させるようになりました(GH 19895)Timestampコンストラクタが、nanosecondキーワード引数または位置引数を受け入れるようになりました(GH 18898)DatetimeIndexは、インスタンス化後にtz属性が設定された場合、AttributeErrorを発生させるようになりました(GH 3746)pytzタイムゾーンを持つDatetimeIndexは、一貫したpytzタイムゾーンを返すようになりました(GH 18595)
その他の API の変更#
Series.astype()およびIndex.astype()は、互換性のないdtypeを使用した場合、ValueErrorではなくTypeErrorを発生させるようになりました(GH 18231)objectdtypedのタイムゾーン対応日時とdtype=objectが指定されたSeriesの構築は、以前は日時dtypeを推論していましたが、現在はobjectdtypedのSeriesを返すようになりました(GH 18231)空の
dictから構築されたdtype=categoryのSeriesは、空のリストが渡された場合と一貫して、dtype=float64ではなくdtype=objectのカテゴリを持つようになります(GH 18515)。MultiIndex内のすべてのNaNレベルは、objectdtypeではなくfloatdtypeが割り当てられるようになり、Indexとの一貫性が促進されます(GH 17929)。MultiIndexのレベル名(Noneでない場合)は一意であることが必須になりました。重複した名前でMultiIndexを作成しようとすると、ValueErrorが発生します(GH 18872)。ハッシュ不可能な
name/namesを持つIndex/MultiIndexの構築と名前変更の両方で、TypeErrorが発生するようになりました(GH 20527)。Index.map()は、Seriesおよび辞書入力オブジェクトを受け入れるようになりました(GH 12756、GH 18482、GH 18509)。DataFrame.unstack()は、objectカラムの場合、デフォルトでnp.nanで埋めるようになりました(GH 12815)。IntervalIndexコンストラクタは、closedパラメーターが入力データの閉じ方が推論されたものと矛盾する場合にエラーを発生させます(GH 18421)。インデックスに欠損値を挿入する機能は、あらゆる種類のインデックスで機能し、渡された型に関係なく、正しい種類の欠損値(
NaN、NaTなど)を自動的に挿入するようになります(GH 18295)。重複するラベルで作成された場合、
MultiIndexはValueErrorを発生させるようになりました(GH 17464)。Series.fillna()は、valueとしてリスト、タプル、またはDataFrameが渡された場合に、ValueErrorの代わりにTypeErrorを発生させるようになりました(GH 18293)。pandas.DataFrame.merge()は、intとfloatの列で結合する場合に、float列をobjectにキャストしなくなりました(GH 16572)。pandas.merge()は、互換性のないデータ型で結合しようとするとValueErrorを発生させるようになりました(GH 9780)。UInt64IndexのデフォルトのNA値が0からNaNに変更されました。これは、UInt64Index.where()などのNAでマスクするメソッドに影響します(GH 18398)。setup.pyがリファクタリングされ、すべてのサブパッケージを明示的にリストする代わりにfind_packagesを使用するようになりました(GH 18535)。read_excel()のキーワード引数の順序がread_csv()と一致するように変更されました(GH 16672)。wide_to_long()は以前、数値のようなサフィックスをobjectdtypeとして保持していました。現在、可能な場合は数値にキャストされます(GH 17627)。read_excel()では、comment引数が名前付きパラメータとして公開されるようになりました(GH 18735)。read_excel()のキーワード引数の順序がread_csv()と一致するように変更されました(GH 16672)。オプション
html.borderとmode.use_inf_as_nullは以前のバージョンで非推奨でしたが、これらはDeprecationWarningではなくFutureWarningを表示するようになります(GH 19003)。IntervalIndexとIntervalDtypeは、カテゴリカル、オブジェクト、文字列のサブタイプをサポートしなくなりました(GH 19016)。IntervalDtypeは、サブタイプに関係なく'interval'と比較されたときにTrueを返すようになり、IntervalDtype.nameは、サブタイプに関係なく'interval'を返すようになります(GH 18980)。drop()、drop()、drop()、drop()で、重複のある軸に存在しない要素をドロップする場合、ValueErrorの代わりにKeyErrorが発生するようになりました(GH 19186)。Series.to_csv()は、DataFrame.to_csv()のcompression引数と同じように機能するcompression引数を受け入れるようになりました(GH 18958)。互換性のないインデックス型を持つ
IntervalIndexでの集合演算(ユニオン、差など)は、ValueErrorではなくTypeErrorを発生させるようになりました(GH 19329)。DateOffsetオブジェクトがより単純にレンダリングされるようになりました。例えば、<DateOffset: kwds={'days': 1}>ではなく<DateOffset: days=1>です(GH 19403)。Categorical.fillnaは、valueとmethodキーワード引数を検証するようになりました。Series.fillna()の動作と一致し、両方またはどちらも指定されていない場合にエラーを発生させます(GH 19682)。pd.to_datetime('today')は、pd.Timestamp('today')と一貫して、datetimeを返すようになりました。以前はpd.to_datetime('today')は.normalized()datetimeを返していました(GH 19935)。Series.str.replace()は、オプションのregexキーワードを受け入れるようになりました。これをFalseに設定すると、正規表現置換ではなくリテラル文字列置換が使用されます(GH 16808)。DatetimeIndex.strftime()とPeriodIndex.strftime()は、類似のアクセサと一貫性を持たせるために、numpy配列ではなくIndexを返すようになりました(GH 20127)。長さ1のリストからSeriesを構築する場合、より長いインデックスが指定されていても、このリストがブロードキャストされなくなりました(GH 19714、GH 20391)。
DataFrame.to_dict()でorient='index'を使用する場合、intとfloatの列のみを持つDataFrameの場合、int列がfloatにキャストされなくなりました(GH 18580)。Series.rolling().aggregate()、DataFrame.rolling().aggregate()、またはその拡張版に渡されるユーザー定義関数は、np.arrayではなく、常にSeriesが渡されるようになりました。.apply()にはrawキーワードのみがあり、詳細はこちらを参照してください。これは、pandas全体での.aggregate()のシグネチャと一貫しています(GH 20584)。RollingおよびExpandingタイプは、反復時に
NotImplementedErrorを発生させます(GH 11704)。
非推奨#
Series.from_arrayとSparseSeries.from_arrayは非推奨になりました。代わりに通常のコンストラクタSeries(..)とSparseSeries(..)を使用してください(GH 18213)。DataFrame.as_matrixは非推奨になりました。代わりにDataFrame.valuesを使用してください(GH 18458)。Series.asobject、DatetimeIndex.asobject、PeriodIndex.asobject、TimeDeltaIndex.asobjectは非推奨になりました。代わりに.astype(object)を使用してください(GH 18572)。キーのタプルによるグループ化は、
FutureWarningを発行し、非推奨になりました。将来的には、'by'に渡されたタプルは、タプルを複数のキーとして扱うのではなく、常に実際のタプルである単一のキーを参照するようになります。以前の動作を保持するには、タプルの代わりにリストを使用してください(GH 18314)。Series.validは非推奨になりました。代わりにSeries.dropna()を使用してください(GH 18800)。read_excel()はskip_footerパラメーターを非推奨にしました。代わりにskipfooterを使用してください(GH 18836)。ExcelFile.parse()は、read_excel()との一貫性のために、sheetnameをsheet_nameに置き換えることを非推奨にしました(GH 20920)。is_copy属性は非推奨であり、将来のバージョンで削除されます(GH 18801)。IntervalIndex.from_intervalsは、IntervalIndexコンストラクタを推奨して非推奨になりました(GH 19263)。DataFrame.from_itemsは非推奨になりました。代わりにDataFrame.from_dict()を使用するか、キーの順序を保持したい場合はDataFrame.from_dict(OrderedDict())を使用してください(GH 17320、GH 17312)。MultiIndexまたはFloatIndexを、一部の欠損キーを含むリストでインデックス付けすると、他の種類のインデックスと一貫して、FutureWarningが表示されるようになりました(GH 17758)。.apply()のbroadcastパラメーターは非推奨になり、result_type='broadcast'が推奨されます(GH 18577)。.apply()のreduceパラメーターは非推奨になり、result_type='reduce'が推奨されます(GH 18577)。factorize()のorderパラメーターは非推奨であり、将来のリリースで削除されます(GH 19727)。Timestamp.weekday_name、DatetimeIndex.weekday_name、Series.dt.weekday_nameは非推奨になり、代わりにTimestamp.day_name()、DatetimeIndex.day_name()、Series.dt.day_name()が推奨されます(GH 12806)。pandas.tseries.plotting.tsplotは非推奨になりました。代わりにSeries.plot()を使用してください(GH 18627)。Index.summary()は非推奨であり、将来のバージョンで削除されます(GH 18217)。NDFrame.get_ftype_counts()は非推奨であり、将来のバージョンで削除されます(GH 18243)。DataFrame.to_records()のconvert_datetime64パラメーターは非推奨になり、将来のバージョンで削除されます。このパラメーターの動機となったNumPyのバグは解決されました。このパラメーターのデフォルト値もTrueからNoneに変更されました(GH 18160)。Series.rolling().apply()、DataFrame.rolling().apply()、Series.expanding().apply()、およびDataFrame.expanding().apply()は、デフォルトでnp.arrayを渡すことを非推奨にしました。何を渡すかを明示するために、新しいrawパラメーターを渡す必要があります(GH 20584)。SeriesクラスとIndexクラスのdata、base、strides、flags、およびitemsizeプロパティは非推奨になり、将来のバージョンで削除されます(GH 20419)。DatetimeIndex.offsetは非推奨になりました。代わりにDatetimeIndex.freqを使用してください(GH 20716)。整数ndarrayと
Timedelta間の切り捨て除算は非推奨です。代わりにTimedelta.valueで除算してください(GH 19761)。PeriodIndex.freqの設定(正しく機能することが保証されていませんでした)は非推奨です。代わりにPeriodIndex.asfreq()を使用してください(GH 20678)。Index.get_duplicates()は非推奨であり、将来のバージョンで削除されます(GH 20239)。Categorical.takeにおける負のインデックスの以前のデフォルト動作は非推奨です。将来のバージョンでは、欠損値を意味するのではなく、右からの位置インデックスを意味するように変更されます。この将来の動作は、Series.take()と一貫しています(GH 20664)。DataFrame.dropna()のaxisパラメーターに複数の軸を渡すことは非推奨であり、将来のバージョンで削除されます(GH 20987)。
以前のバージョンの非推奨/変更の削除#
廃止された
Categorical(codes, categories)の使用(例えば、Categorical()の最初の2つの引数のdtypeが異なる場合に発行され、Categorical.from_codesの使用が推奨されていた)に対する警告は削除されました(GH 8074)。MultiIndexのlevelsおよびlabels属性は直接設定できなくなりました(GH 4039)。pd.tseries.util.pivot_annualは削除されました(v0.19から非推奨)。代わりにpivot_tableを使用してください(GH 18370)。pd.tseries.util.isleapyearは削除されました(v0.19から非推奨)。代わりにDatetimeライクオブジェクトの.is_leap_yearプロパティを使用してください(GH 18370)。pd.ordered_mergeは削除されました(v0.19から非推奨)。代わりにpd.merge_orderedを使用してください(GH 18459)。SparseListクラスは削除されました(GH 14007)。pandas.io.wbおよびpandas.io.dataスタブモジュールは削除されました(GH 13735)。Categorical.from_arrayは削除されました(GH 13854)。DataFrameおよびSeriesの
rolling/expanding/ewmメソッドからfreqおよびhowパラメーターが削除されました(v0.18から非推奨)。代わりに、メソッドを呼び出す前にリサンプルしてください(GH 18601およびGH 18668)。DatetimeIndex.to_datetime、Timestamp.to_datetime、PeriodIndex.to_datetime、およびIndex.to_datetimeは削除されました(GH 8254、GH 14096、GH 14113)。read_csv()はskip_footerパラメーターを削除しました(GH 13386)。read_csv()はas_recarrayパラメーターを削除しました(GH 13373)。read_csv()はbuffer_linesパラメーターを削除しました(GH 13360)。read_csv()はcompact_intsおよびuse_unsignedパラメーターを削除しました(GH 13323)。Timestampクラスは、offset属性を削除し、freqを採用しました(GH 13593)。Series、Categorical、およびIndexクラスはreshapeメソッドを削除しました(GH 13012)。pandas.tseries.frequencies.get_standard_freqは削除され、pandas.tseries.frequencies.to_offset(freq).rule_codeが推奨されます(GH 13874)。pandas.tseries.frequencies.to_offsetからfreqstrキーワードが削除され、freqが推奨されます(GH 13874)。Panel4DおよびPanelNDクラスは削除されました(GH 13776)。Panelクラスはto_longおよびtoLongメソッドを削除しました(GH 19077)。オプション
display.line_withおよびdisplay.heightは、それぞれdisplay.widthおよびdisplay.max_rowsに置き換えられ、削除されました(GH 4391、GH 19107)。Categoricalクラスのlabels属性は、Categorical.codesに置き換えられ、削除されました(GH 7768)。to_sql()メソッドからflavorパラメーターが削除されました(GH 13611)。モジュール
pandas.tools.hashingおよびpandas.util.hashingは削除されました(GH 16223)。トップレベル関数
pd.rolling_*、pd.expanding_*、pd.ewm*は削除されました(v0.18から非推奨)。代わりに、DataFrame/Seriesメソッドのrolling、expanding、ewmを使用してください(GH 18723)。is_datetime64_dtypeなどの関数に対するpandas.core.commonからのインポートは削除されました。これらはpandas.api.typesにあります(GH 13634、GH 19769)。Series.tz_localize()、DatetimeIndex.tz_localize()、およびDatetimeIndexのinfer_dstキーワードは削除されました。infer_dst=Trueはambiguous='infer'と同等であり、infer_dst=Falseはambiguous='raise'と同等です(GH 7963)。v0.18.0で
.resample()が即時実行から遅延実行(.groupby()のように)に変更された際、互換性(FutureWarning付き)が導入され、操作が引き続き機能するようにされていました。これは完全に削除され、Resamplerは互換性操作を転送しなくなります(GH 20554)。.replace()から長い間非推奨であったaxis=Noneパラメーターを削除しました(GH 20271)。
パフォーマンス改善#
SeriesまたはDataFrameのインデクサーは参照サイクルを作成しなくなりました(GH 17956)。to_datetime()にキーワード引数cacheが追加され、重複するdatetime引数の変換パフォーマンスが向上しました(GH 11665)。DateOffsetの算術演算パフォーマンスが向上しました(GH 18218)。TimedeltaオブジェクトのSeriesを日数、秒などに変換する速度が、基礎となるメソッドのベクトル化によって向上しました(GH 18092)。Series/dict入力を伴う.map()のパフォーマンスが向上しました(GH 15081)。Timedeltaのdays、seconds、microsecondsのオーバーライドされたプロパティは削除され、代わりにPython組み込みバージョンが利用されるようになりました(GH 18242)。Series構築は、特定の場合に入力データのコピー数を削減します(GH 17449)。Series.dt.date()およびDatetimeIndex.date()のパフォーマンスが向上しました(GH 18058)。Series.dt.time()およびDatetimeIndex.time()のパフォーマンスが向上しました(GH 18461)。IntervalIndex.symmetric_difference()のパフォーマンスが向上しました(GH 18475)。ビジネス月およびビジネス四半期の頻度を持つ
DatetimeIndexとSeriesの算術演算のパフォーマンスが向上しました(GH 18489)。Series()/DataFrame()のタブ補完が100値に制限され、パフォーマンスが向上しました(GH 18587)。bottleneckがインストールされていない場合、
axis=1を指定したDataFrame.median()のパフォーマンスが向上しました(GH 16468)。大きなインデックスの場合の
MultiIndex.get_loc()のパフォーマンスが向上しました。ただし、小さなインデックスの場合のパフォーマンスは低下します(GH 18519)。未使用レベルがない場合の
MultiIndex.remove_unused_levels()のパフォーマンスが向上しました。ただし、未使用レベルがある場合のパフォーマンスは低下します(GH 19289)。非一意なインデックスの場合の
Index.get_loc()のパフォーマンスが向上しました(GH 19478)。.cov()および.corr()演算におけるペアワイズの.rolling()および.expanding()のパフォーマンスが向上しました(GH 17917)。GroupBy.rank()のパフォーマンスが向上しました(GH 15779)。.min()および.max()における可変.rolling()のパフォーマンスが向上しました(GH 19521)。GroupBy.ffill()およびGroupBy.bfill()のパフォーマンスが向上しました(GH 11296)。GroupBy.any()およびGroupBy.all()のパフォーマンスが向上しました(GH 15435)。GroupBy.pct_change()のパフォーマンスが向上しました(GH 19165)。カテゴリカルdtypeの場合の
Series.isin()のパフォーマンスが向上しました(GH 20003)。特定のインデックス型を持つSeriesの場合の
getattr(Series, attr)のパフォーマンスが向上しました。これは、DatetimeIndexを持つ大きなSeriesの印刷速度が遅いという形で現れていました(GH 19764)。一部のオブジェクト列を持つ
GroupBy.nth()およびGroupBy.last()のパフォーマンス低下が修正されました(GH 19283)。Categorical.from_codes()のパフォーマンスが向上しました(GH 18501)。
ドキュメントの変更#
3月10日に開催されたpandas Documentation Sprintに参加してくださったすべての貢献者に感謝いたします。世界30か所以上から約500人の参加者がありました。これにより、多くのAPI docstringsが大幅に改善されたことに気づかれるでしょう。
あまりにも多くの同時貢献があったため、すべての改善をリリースノートに含めることはできませんが、このGitHub検索で、どれだけのdocstringsが改善されたかをおおよそ把握できるはずです。
スプリントを組織してくれたMarc Garciaに特に感謝いたします。詳細については、スプリントをまとめたNumFOCUSのブログ記事をお読みください。
バグ修正#
カテゴリカル#
警告
pandas 0.21でCategoricalDtypeにバグのクラスが導入され、同じカテゴリを持つが順序が異なる複数の順序なしCategorical配列を比較する際に、merge、concat、インデックス付けなどの操作の正確性に影響を与えました。これらの操作を行う前に、アップグレードまたはカテゴリを手動で揃えることを強くお勧めします。
同じカテゴリを持つが順序が異なる2つの順序なし
Categorical配列を比較する際に、Categorical.equalsが誤った結果を返すバグ(GH 16603)。カテゴリの順序が異なる順序なしカテゴリカルデータの場合に、
pandas.api.types.union_categoricals()が誤った結果を返すバグ。これはCategoricalデータを含むpandas.concat()に影響を与えました(GH 19096)。同じカテゴリを持つが順序が異なる順序なし
Categoricalで結合する際に、pandas.merge()が誤った結果を返すバグ(GH 19551)。targetがselfと同じカテゴリを持つが順序が異なる順序なしCategoricalである場合に、CategoricalIndex.get_indexer()が誤った結果を返すバグ(GH 19551)。カテゴリカルdtypeを持つ
Index.astype()で、結果のインデックスがすべての種類のインデックスに対してCategoricalIndexに変換されないバグ(GH 18630)。Series.astype()およびCategorical.astype()で、既存のカテゴリカルデータが更新されないバグ(GH 10696、GH 18593)。expand=Trueを指定したSeries.str.split()が、空の文字列に対して誤ってIndexErrorを発生させるバグ(GH 20002)。dtype=CategoricalDtype(...)を指定したIndexコンストラクタで、categoriesとorderedが保持されないバグ(GH 19032)。スカラーと
dtype=CategoricalDtype(...)を指定したSeriesコンストラクタで、categoriesとorderedが保持されないバグ(GH 19565)。Categorical.__iter__がPython型に変換されないバグ(GH 19909)。pandas.factorize()がuniquesに対して一意のコードを返すバグ。これは入力と同じdtypeを持つCategoricalを返すようになりました(GH 19721)。pandas.factorize()がuniquesの戻り値に欠損値の項目を含めるバグ(GH 19721)。カテゴリカルデータを持つ
Series.take()で、indices内の-1をSeriesの最後の要素ではなく欠損値マーカーとして解釈するバグ(GH 20664)。
日付時刻ライク#
Series.__sub__()が、非ナノ秒のnp.datetime64オブジェクトをSeriesから減算すると、誤った結果を返すバグ(GH 7996)。DatetimeIndex、TimedeltaIndexの加算と減算で、ゼロ次元の整数配列が誤った結果を返すバグ(GH 19012)。DatetimeIndexおよびTimedeltaIndexで、DateOffsetオブジェクトの配列ライクを加算または減算すると、エラーが発生するか(np.array、pd.Index)、または誤ってブロードキャストされる(pd.Series)バグ(GH 18849)。Series.__add__()が、dtypetimedelta64[ns]のSeriesをタイムゾーン対応のDatetimeIndexに加算すると、誤ってタイムゾーン情報を削除するバグ(GH 13905)。PeriodオブジェクトをdatetimeまたはTimestampオブジェクトに加算すると、正しくTypeErrorが発生するようになりました(GH 17983)。Timestampの配列と比較するとRecursionErrorが発生するTimestampのバグ (GH 15183)DatetimeIndexの repr が一日の終わりの高精度時刻値 (例: 23:59:59.999999999) を表示しないバグ (GH 19030)非 ns timedelta 単位への
.astype()で間違った dtype が保持されるバグ (GH 19176, GH 19223, GH 12425)単調な
PeriodIndexでSeries.truncate()がTypeErrorを発生させるバグ (GH 17717)periodsとfreqを使用するpct_change()が異なる長さの出力を返していたバグ (GH 7292)DatetimeIndexとNoneまたはdatetime.dateオブジェクトの比較で、==と!=の比較において、すべてFalseおよびすべてTrueではなくTypeErrorが発生するバグ (GH 19301)Timestampとto_datetime()で、境界をわずかに超えるタイムスタンプを表す文字列がOutOfBoundsDatetimeを発生させる代わりに誤って切り捨てられていたバグ (GH 19382)Timestamp.floor()およびDatetimeIndex.floor()で、遠い未来および過去のタイムスタンプが正しく丸められていなかったバグ (GH 19206)to_datetime()でerrors='coerce'およびutc=Trueを指定して範囲外の datetime を渡すと、NaTにパースされる代わりにOutOfBoundsDatetimeが発生していたバグ (GH 19612)DatetimeIndexとTimedeltaIndexの加算と減算で、返されるオブジェクトの名前が常に一貫して設定されていなかったバグ (GH 19744)DatetimeIndexとTimedeltaIndexの加算と減算で、numpy 配列との演算がTypeErrorを発生させていたバグ (GH 19847)DatetimeIndexとTimedeltaIndexでfreq属性の設定が完全にサポートされていなかったバグ (GH 20678)
Timedelta#
Timedelta.__mul__()でNaTを乗算するとTypeErrorが発生する代わりにNaTが返されていたバグ (GH 19819)dtype='timedelta64[ns]'のSeriesでTimedeltaIndexの加算または減算の結果がdtype='int64'にキャストされていたバグ (GH 17250)dtype='timedelta64[ns]'のSeriesでTimedeltaIndexの加算または減算が誤った名前のSeriesを返すことがあったバグ (GH 19043)Timedelta.__floordiv__()およびTimedelta.__rfloordiv__()で、多くの互換性のない numpy オブジェクトによる除算が誤って許可されていたバグ (GH 18846)スカラ timedelta 型オブジェクトを
TimedeltaIndexで除算すると、逆数演算が行われるバグ (GH 19125)TimedeltaIndexをSeriesで除算するとSeriesではなくTimedeltaIndexが返されるバグ (GH 19042)Timedelta.__add__()、Timedelta.__sub__()でnp.timedelta64オブジェクトを加算または減算すると、Timedeltaではなく別のnp.timedelta64が返されていたバグ (GH 19738)Timedelta.__floordiv__()、Timedelta.__rfloordiv__()でTickオブジェクトを操作すると、数値が返される代わりにTypeErrorが発生していたバグ (GH 19738)Period.asfreq()でdatetime(1, 1, 1)付近の期間が誤って変換される可能性があったバグ (GH 19643, GH 19834)Timedelta.total_seconds()で精度エラーが発生するバグ。例えばTimedelta('30S').total_seconds()==30.000000000000004(GH 19458)Timedelta.__rmod__()でnumpy.timedelta64を操作するとTimedeltaではなくtimedelta64オブジェクトが返されていたバグ (GH 19820)TimedeltaIndexをTimedeltaIndexで乗算すると、長さが一致しない場合にValueErrorが発生する代わりにTypeErrorが発生するようになりました (GH 19333)TimedeltaIndexをnp.timedelta64オブジェクトでインデックス化するとTypeErrorが発生していたバグ (GH 20393)
タイムゾーン#
タイムゾーンを持たない値とタイムゾーンを持つ値の両方を含む配列から
Seriesを作成すると、dtype がオブジェクトではなくタイムゾーンを持つSeriesになるバグ (GH 16406)タイムゾーンを持つ
DatetimeIndexとNaTの比較で、誤ってTypeErrorが発生していたバグ (GH 19276)タイムゾーンを持つ dtype 間の変換、およびタイムゾーンを持つ dtype からタイムゾーンを持たない dtype への変換における
DatetimeIndex.astype()のバグ (GH 18951)タイムゾーンを持つ datetime 型オブジェクトとタイムゾーンを持たない datetime 型オブジェクトを比較しようとすると
TypeErrorが発生しなかったDatetimeIndexの比較のバグ (GH 18162)datetime64[ns, tz]dtype を持つSeriesコンストラクタで、タイムゾーンを持たない datetime 文字列のローカライズのバグ (GH 174151)Timestamp.replace()が夏時間移行を適切に処理するようになりました (GH 18319)タイムゾーンを持つ
DatetimeIndexで、TimedeltaIndexまたはdtype='timedelta64[ns]'の配列との加算/減算が正しくなかったバグ (GH 17558)DatetimeIndex.insert()で、タイムゾーンを持つインデックスにNaTを挿入すると誤って例外が発生していたバグ (GH 16357)DataFrameコンストラクタで、タイムゾーンを持つ DatetimeIndex と指定された列名によって空のDataFrameが作成されるバグ (GH 19157)Timestamp.tz_localize()で、最小または最大の有効値に近いタイムスタンプをローカライズすると、オーバーフローして誤ったナノ秒値を持つタイムスタンプが返される可能性があったバグ (GH 12677)固定タイムゾーンオフセットでローカライズされた
DatetimeIndexを反復処理すると、ナノ秒精度がマイクロ秒に丸められるバグ (GH 19603)タイムゾーンを持つ値に対して
DataFrame.diff()がIndexErrorを発生させていたバグ (GH 18578)melt()がタイムゾーンを持つ dtype をタイムゾーンを持たない dtype に変換していたバグ (GH 15785)タイムゾーンを持つ値を持つ単一の列に対して
Dataframe.dropna()が呼び出された場合にDataframe.count()がValueErrorを発生させていたバグ (GH 13407)
オフセット#
WeekOfMonthおよびWeekで、加算と減算が正しくロールしていなかったバグ (GH 18510, GH 18672, GH 18864)WeekOfMonthおよびLastWeekOfMonthで、コンストラクタのデフォルトキーワード引数がValueErrorを発生させていたバグ (GH 19142)FY5253Quarter、LastWeekOfMonthで、ロールバックとロールフォワードの動作が加算と減算の動作と一貫していなかったバグ (GH 18854)FY5253で、年末の日付だが真夜中に正規化されていない日付に対してdatetimeの加算と減算が誤ってインクリメントされていたバグ (GH 18854)FY5253で、日付オフセットが算術演算で誤ってAssertionErrorを発生させる可能性があったバグ (GH 14774)
数値#
int または float のリストを持つ
Seriesコンストラクタで、dtype=str、dtype='str'またはdtype='U'を指定してもデータ要素が文字列に変換されなかったバグ (GH 16605)Indexの乗算および除算メソッドで、Seriesを操作するとSeriesオブジェクトではなくIndexオブジェクトが返されていたバグ (GH 19042)DataFrameコンストラクタで、非常に大きな正の数または非常に大きな負の数を含むデータがOverflowErrorを引き起こしていたバグ (GH 18584)Indexコンストラクタでdtype='uint64'を指定した場合、int 型の浮動小数点数がUInt64Indexに強制されなかったバグ (GH 18400)DataFrameのフレキシブルな算術演算 (例:df.add(other, fill_value=foo)) で、None以外のfill_valueを指定した場合、フレームまたはotherのいずれかの長さがゼロであるエッジケースでNotImplementedErrorが発生しなかったバグ (GH 19522)数値型 dtype の
Indexオブジェクトと timedelta 型のスカラーの乗算および除算で、TypeErrorが発生する代わりにTimedeltaIndexが返されるバグ (GH 19333)Series.pct_change()およびDataFrame.pct_change()でfill_methodがNoneでない場合に 0 ではなくNaNが返されていたバグ (GH 19873)
文字列#
Series.str.get()で、値が辞書であり、インデックスがキーにない場合にKeyErrorが発生していたバグ (GH 20671)
インデックス付け#
Index.drop()で、タプルと非タプルの両方のリストを渡した場合のバグ (GH 18304)DataFrame.drop()、Panel.drop()、Series.drop()、Index.drop()で、重複を含む軸から存在しない要素を削除する際にKeyErrorが発生しないバグ (GH 19186)datetime 型の
Indexのインデックス付けで、IndexErrorではなくValueErrorが発生していたバグ (GH 18386)。Index.to_series()がindexおよびnamekwargs を受け入れるようになりました (GH 18699)DatetimeIndex.to_series()がindexおよびnamekwargs を受け入れるようになりました (GH 18699)一意でない
Indexを持つSeriesから非スカラ値をインデックス化すると、値が平坦化されて返されるバグ (GH 17610)欠落しているキーのみを含むイテレータによるインデックス付けで、エラーが発生しなかったバグ (GH 20748)
インデックスが整数 dtype であり、目的のキーを含まない場合に、リストキーとスカラキーの間で
.ixの不整合が修正されました (GH 20753)2次元ブール ndarray で
DataFrameをインデックス化する際の__setitem__のバグ (GH 18582)str.extractallで、一致するものがなかった場合に適切なMultiIndexではなく空のIndexが返されていたバグ (GH 19034)IntervalIndexで、空のデータと純粋に NA のデータが構築方法によって一貫性のない方法で構築されていたバグ (GH 18421)IntervalIndex.symmetric_difference()で、非IntervalIndexとの対称差が例外を発生させなかったバグ (GH 18475)IntervalIndexで、空のIntervalIndexを返す集合演算の dtype が間違っていたバグ (GH 19101)DataFrame.drop_duplicates()で、DataFrameに存在しない列を渡してもKeyErrorが発生しないバグ (GH 19726)予期しないキーワード引数を無視する
Indexサブクラスコンストラクタのバグ (GH 19348)Indexとそれ自身の差を取る際のIndex.difference()のバグ (GH 20040)値の中央に NaN の行全体がある場合の
DataFrame.first_valid_index()とDataFrame.last_valid_index()のバグ (GH 20499)。IntervalIndexで、重複するまたは単調でないuint64データに対して一部のインデックス操作がサポートされていなかったバグ (GH 20636)Series.is_uniqueで、__ne__が定義されたオブジェクトを含む Series の場合に標準エラーに出力が表示されるバグ (GH 20661)単一要素のリストのようなもので代入すると、誤ってリストとして代入される
.loc代入のバグ (GH 19474)単調減少する
DatetimeIndexを持つSeries/DataFrameの部分文字列インデックス付けのバグ (GH 19362)重複する
Indexを持つDataFrameでインプレース操作を実行する際のバグ (GH 17105)単一の区間を含む
IntervalIndexで使用した場合のIntervalIndex.get_loc()およびIntervalIndex.get_indexer()のバグ (GH 17284, GH 20921)uint64インデクサを使用する.locのバグ (GH 20722)
MultiIndex#
MultiIndex.__contains__()で、タプル以外のキーが削除されていてもTrueを返していたバグ (GH 19027)MultiIndex.set_labels()で、level引数が 0 または [0, 1, …] のようなリストではない場合に新しいラベルのキャスト (および潜在的なクリッピング) を引き起こすバグ (GH 19057)MultiIndex.get_level_values()で、欠損値を持つ int 型のレベルで無効なインデックスを返していたバグ (GH 17924)空の
MultiIndexで呼び出された場合のMultiIndex.unique()のバグ (GH 20568)MultiIndex.unique()がレベル名を保持しなかったバグ (GH 20570)MultiIndex.remove_unused_levels()が NaN 値を埋めていたバグ (GH 18417)MultiIndex.from_tuples()が python3 で zip されたタプルを受け入れなかったバグ (GH 18434)MultiIndex.get_loc()が float と int の間で値を自動的にキャストしなかったバグ (GH 18818, GH 15994)MultiIndex.get_loc()がブール値を整数ラベルにキャストしていたバグ (GH 19086)MultiIndex.get_loc()がNaNを含むキーを検索できなかったバグ (GH 18485)大きな
MultiIndexのMultiIndex.get_loc()で、レベルが異なる dtype を持っている場合に失敗するバグ (GH 18520)入れ子になったインデクサが numpy 配列のみを持つ場合に正しく処理されなかったインデックス付けのバグ (GH 19686)
IO#
read_html()は、解析失敗後、新しいパーサーで解析を試みる前に、シーク可能な IO オブジェクトを巻き戻すようになりました。パーサーがエラーを発生させ、オブジェクトがシーク不可能である場合、別のパーサーの使用を提案する情報的なエラーが発生します (GH 17975)DataFrame.to_html()は、先頭の<table>タグに id を追加するオプションを持つようになりました (GH 8496)Python 2 で存在しないファイルが渡された場合の
read_msgpack()のバグ (GH 15296)read_csv()で、重複する列を持つMultiIndexが適切に処理されなかったバグ (GH 18062)read_csv()で、辞書型na_valuesとkeep_default_na=Falseを使用した場合に欠損値が正しく処理されなかったバグ (GH 19227)32ビット、ビッグエンディアンアーキテクチャでヒープ破損を引き起こす
read_csv()のバグ (GH 20785)read_sas()で、0 変数のファイルが誤ってAttributeErrorを発生させていたバグ。現在はEmptyDataErrorを発生させます (GH 18184)DataFrame.to_latex()で、目に見えないプレースホルダーとして機能する中括弧のペアがエスケープされていたバグ (GH 18667)DataFrame.to_latex()で、MultiIndexにNaNがあるとIndexErrorまたは間違った出力が発生するバグ (GH 14249)DataFrame.to_latex()で、文字列以外のインデックスレベル名がAttributeErrorを引き起こすバグ (GH 19981)DataFrame.to_latex()で、インデックス名とindex_names=Falseオプションの組み合わせが間違った出力を引き起こすバグ (GH 18326)DataFrame.to_latex()で、空文字列を名前とするMultiIndexが間違った出力を引き起こすバグ (GH 18669)DataFrame.to_latex()で、欠落したスペース文字が間違ったエスケープを引き起こし、場合によっては無効な LaTeX を生成するバグ (GH 20859)read_json()で、大きな数値がOverflowErrorを引き起こしていたバグ (GH 18842)DataFrame.to_parquet()で、書き込み先が S3 の場合に例外が発生していたバグ (GH 19134)すべての Excel ファイルタイプで
DataFrame.to_excel()でIntervalがサポートされるようになりました (GH 19242)すべての Excel ファイルタイプで
DataFrame.to_excel()でTimedeltaがサポートされるようになりました (GH 19242, GH 9155, GH 19900)非常に古いファイルで呼び出された場合に
pandas.io.stata.StataReader.value_labels()がAttributeErrorを発生させていたバグ。現在は空の dict を返します (GH 19417)バージョン 0.20 より前に作成された
TimedeltaIndexまたはFloat64Indexを持つオブジェクトをアンピクルする際のread_pickle()のバグ (GH 19939)pandas.io.json.json_normalize()で、いずれかのサブレコードの値が NoneType である場合にサブレコードが正しく正規化されないバグ (GH 20030)read_csv()のusecolsパラメータで、文字列を渡した場合にエラーが正しく発生しないバグ (GH 20529)ソフトリンクのあるファイルを読み込む際に
HDFStore.keys()が例外を発生させるバグ (GH 20523)HDFStore.select_column()で、有効なストアではないキーがKeyErrorではなくAttributeErrorを発生させていたバグ (GH 17912)
プロット#
プロットしようとしたが matplotlib がインストールされていない場合のより良いエラーメッセージ (GH 19810)。
DataFrame.plot()は、xまたはy引数が不適切に形成されている場合にValueErrorを発生させるようになりました (GH 18671)DataFrame.plot()で、xおよびy引数を位置として指定した場合に、線グラフ、棒グラフ、面グラフで参照される列が誤っていたバグ (GH 20056)datetime.time()と小数秒で目盛りラベルをフォーマットする際のバグ (GH 18478)。Series.plot.kde()は、docstring で引数indとbw_methodを公開しました (GH 18461)。引数indは整数 (サンプル点数) にもできるようになりました。DataFrame.plot()は、y引数に複数の列をサポートするようになりました (GH 19699)
GroupBy/resample/rolling#
単一の列でグループ化し、
listやtupleのようなクラスで集約する際のバグ (GH 18079)DataFrame.groupby()で、インデックスにないタプルキーで呼び出された場合にエラーを発生させなかった回帰が修正されました (GH 18798)DataFrame.resample()で、label、closed、conventionのサポートされていない (またはタイプミスされた) オプションを黙って無視していたバグ (GH 19303)DataFrame.groupby()で、タプルがキーではなくキーのリストとして解釈されていたバグ (GH 17979, GH 18249)DataFrame.groupby()で、first/last/min/maxによる集約がタイムスタンプの精度を失わせていたバグ (GH 19526)DataFrame.transform()で、特定の集約関数がグループ化されたデータの dtype に一致するように誤ってキャストされていたバグ (GH 19200)DataFrame.groupby()でon=kwarg を渡し、その後に.apply()を使用する際のバグ (GH 17813)DataFrame.resample().aggregateで、存在しない列を集約する際にKeyErrorが発生しなかったバグ (GH 16766, GH 19566)skipnaが渡された場合のDataFrameGroupBy.cumsum()およびDataFrameGroupBy.cumprod()のバグ (GH 19806)DataFrame.resample()がタイムゾーン情報を削除していたバグ (GH 13238)DataFrame.groupby()で、np.allおよびnp.anyを使用する変換がValueErrorを発生させていたバグ (GH 20653)DataFrame.resample()で、ffill、bfill、pad、backfill、fillna、interpolate、およびasfreqがloffsetを無視していたバグ (GH 20744)DataFrame.groupby()で、混合データ型を持つ関数を適用し、ユーザーが指定した関数がグループ化列で失敗する可能性があったバグ (GH 20949)DataFrameGroupBy.rolling().apply()で、関連するDataFrameGroupByオブジェクトに対して実行された操作が、結果へのグループ化されたアイテムの包含に影響を与える可能性があったバグ (GH 14013)
スパース#
再整形#
DataFrame.merge()で、CategoricalIndexを名前で参照し、bykwarg がKeyErrorを発生させていたバグ (GH 20777)DataFrame.stack()が Python 3 で混合型のレベルをソートしようとして失敗するバグ (GH 18310)columnsが未使用レベルのMultiIndexの場合、int を float にキャストするDataFrame.unstack()のバグ (GH 17845)indexがアンスタックされたレベルで未使用ラベルを持つMultiIndexの場合、エラーが発生するDataFrame.unstack()のバグ (GH 18562)len(index) > len(data) = 1 の
Seriesの構築を無効にしました。以前はデータ項目をブロードキャストしていましたが、現在はValueErrorが発生します (GH 18819)対応するキーが渡されたインデックスに含まれていない場合に、スカラー値を含む
dictからDataFrameを構築する際のエラーを抑制しました (GH 18600)軸、データなし、
dtype=intで初期化されたDataFrameの dtype を修正しました (objectからfloat64に変更) (GH 19646)NaTを含むSeriesがSeriesをインプレースで変更するSeries.rank()のバグ (GH 18521)aggfunc引数が文字列型の場合に失敗するDataFrame.pivot_table()のバグ。動作はaggやapplyなどの他のメソッドと整合性が取れるようになりました (GH 18713)Indexオブジェクトをベクトルとして使用してマージすると例外が発生するDataFrame.merge()のバグ (GH 19038)サブクラスを返していなかった
DataFrame.stack(),DataFrame.unstack(),Series.unstack()のバグ (GH 15563)タイムゾーン比較のバグで、
.concat()でインデックスが UTC に変換される形で現れていました (GH 18523)スパースシリーズと密シリーズを連結する際に
SparseDataFrameのみを返すconcat()のバグ。DataFrameであるべきです。 (GH 18914, GH 18686, および GH 16874)共通のマージキーがない場合の
DataFrame.merge()のエラーメッセージを改善しました (GH 19427)複数の DataFrame で呼び出され、一部に一意でないインデックスがある場合に、
leftjoin の代わりにouterjoin を行うDataFrame.join()のバグ (GH 19624)Series.rename()がaxisを kwarg として受け入れるようになりました (GH 18589)SeriesとIndexの比較で、Indexの名前属性を無視して、誤った名前を持つSeriesが返されるというバグ (GH 19582)NaTが存在する datetime および timedelta データでValueErrorが発生するqcut()のバグ (GH 19768)ISO8601 に準拠していない文字列を datetime として推論する
DataFrame.iterrows()のバグ (GH 19671)Categoricalを伴うSeriesコンストラクターで、異なる長さのインデックスが与えられた場合にValueErrorが発生しないバグ (GH 19342)カテゴリカルまたは dtype の辞書に変換する際に、列のメタデータが失われる
DataFrame.astype()のバグ (GH 19920)dtype=strを伴うSeriesコンストラクターのバグで、以前は一部のケースで発生していました (GH 19853)重複する列名が誤った動作を引き起こす
get_dummies()およびselect_dtypes()のバグ (GH 20848)TZ対応のデータフレームと全NaTデータフレームを連結する際にエラーが発生する
concat()のバグ (GH 12396)
その他#
numexprを使用したクエリで Python のキーワードを識別子として使用しようとした際のエラーメッセージを改善しました (GH 18221)pandas.get_option()にアクセスする際のバグで、一部のケースで存在しないオプションキーを探す際にOptionErrorではなくKeyErrorを発生させていました (GH 19789)異なるユニコードデータを持つ Series または DataFrame の
testing.assert_series_equal()およびtesting.assert_frame_equal()のバグ (GH 20503)
貢献者#
このリリースには合計328名がパッチを貢献しました。名前に「+」が付いている方は、初めてパッチを貢献された方です。
Aaron Critchley
AbdealiJK +
Adam Hooper +
アルバート・ビラノバ・デル・モラル
Alejandro Giacometti +
Alejandro Hohmann +
Alex Rychyk
Alexander Buchkovsky
Alexander Lenail +
Alexander Michael Schade
Aly Sivji +
Andreas Költringer +
Andrew
Andrew Bui +
András Novoszáth +
Andy Craze +
Andy R. Terrel
Anh Le +
Anil Kumar Pallekonda +
Antoine Pitrou +
Antonio Linde +
Antonio Molina +
Antonio Quinonez +
Armin Varshokar +
Artem Bogachev +
Avi Sen +
Azeez Oluwafemi +
Ben Auffarth +
Bernhard Thiel +
Bhavesh Poddar +
BielStela +
Blair +
Bob Haffner
Brett Naul +
Brock Mendel
Bryce Guinta +
Carlos Eduardo Moreira dos Santos +
Carlos García Márquez +
Carol Willing
Cheuk Ting Ho +
Chitrank Dixit +
Chris
Chris Burr +
Chris Catalfo +
Chris Mazzullo
Christian Chwala +
Cihan Ceyhan +
Clemens Brunner
Colin +
Cornelius Riemenschneider
Crystal Gong +
DaanVanHauwermeiren
Dan Dixey +
Daniel Frank +
Daniel Garrido +
Daniel Sakuma +
DataOmbudsman +
Dave Hirschfeld
Dave Lewis +
David Adrián Cañones Castellano +
David Arcos +
David C Hall +
David Fischer
David Hoese +
David Lutz +
David Polo +
David Stansby
Dennis Kamau +
Dillon Niederhut
Dimitri +
Dr. Irv
Dror Atariah
Eric Chea +
Eric Kisslinger
Eric O. LEBIGOT (EOL) +
FAN-GOD +
Fabian Retkowski +
Fer Sar +
Gabriel de Maeztu +
Gianpaolo Macario +
Giftlin Rajaiah
Gilberto Olimpio +
Gina +
Gjelt +
Graham Inggs +
Grant Roch
Grant Smith +
Grzegorz Konefał +
ギルヘルム・ベルトラミーニ
HagaiHargil +
Hamish Pitkeathly +
Hammad Mashkoor +
Hannah Ferchland +
ハンス
Haochen Wu +
Hissashi Rocha +
Iain Barr +
Ibrahim Sharaf ElDen +
Ignasi Fosch +
Igor Conrado Alves de Lima +
Igor Shelvinskyi +
Imanflow +
Ingolf Becker
Israel Saeta Pérez
Iva Koevska +
Jakub Nowacki +
Jan F-F +
Jan Koch +
Jan Werkmann
Janelle Zoutkamp +
Jason Bandlow +
Jaume Bonet +
Jay Alammar +
ジェフ・リーバック
JennaVergeynst
Jimmy Woo +
Jing Qiang Goh +
Joachim Wagner +
Joan Martin Miralles +
Joel Nothman
Joeun Park +
John Cant +
Johnny Metz +
Jon Mease
Jonas Schulze +
Jongwony +
Jordi Contestí +
Joris Van den Bossche
José F. R. Fonseca +
Jovixe +
Julio Martinez +
Jörg Döpfert
KOBAYASHI Ittoku +
Kate Surta +
Kenneth +
Kevin Kuhl
ケビン・シェパード
Krzysztof Chomski
Ksenia +
Ksenia Bobrova +
Kunal Gosar +
Kurtis Kerstein +
Kyle Barron +
Laksh Arora +
Laurens Geffert +
Leif Walsh
Liam Marshall +
Liam3851 +
Licht Takeuchi
Liudmila +
Ludovico Russo +
Mabel Villalba +
Manan Pal Singh +
Manraj Singh
Marc +
Marc Garcia
Marco Hemken +
Maria del Mar Bibiloni +
Mario Corchero +
Mark Woodbridge +
Martin Journois +
Mason Gallo +
Matias Heikkilä +
Matt Braymer-Hayes
Matt Kirk +
Matt Maybeno +
Matthew Kirk +
Matthew Rocklin +
Matthew Roeschke
Matthias Bussonnier +
Max Mikhaylov +
Maxim Veksler +
Maximilian Roos
Maximiliano Greco +
Michael Penkov
Michael Röttger +
Michael Selik +
Michael Waskom
Mie~~~
Mike Kutzma +
Ming Li +
Mitar +
Mitch Negus +
Montana Low +
Moritz Münst +
モルタダ・メヒヤル
Myles Braithwaite +
Nate Yoder
Nicholas Ursa +
Nick Chmura
Nikos Karagiannakis +
Nipun Sadvilkar +
Nis Martensen +
Noah +
Noémi Éltető +
Olivier Bilodeau +
Ondrej Kokes +
Onno Eberhard +
Paul Ganssle +
Paul Mannino +
Paul Reidy
Paulo Roberto de Oliveira Castro +
Pepe Flores +
Peter Hoffmann
Phil Ngo +
ピエトロ・バティストン
Pranav Suri +
Priyanka Ojha +
Pulkit Maloo +
README Bot +
Ray Bell +
Riccardo Magliocchetti +
Ridhwan Luthra +
Robert Meyer
Robin
Robin Kiplang’at +
Rohan Pandit +
Rok Mihevc +
Rouz Azari
Ryszard T. Kaleta +
Sam Cohan
Sam Foo
Samir Musali +
Samuel Sinayoko +
Sangwoong Yoon
SarahJessica +
Sharad Vijalapuram +
Shubham Chaudhary +
SiYoungOh +
Sietse Brouwer
Simone Basso +
Stefania Delprete +
Stefano Cianciulli +
Stephen Childs +
StephenVoland +
Stijn Van Hoey +
スヴェン
Talitha Pumar +
Tarbo Fukazawa +
Ted Petrou +
トーマス・A・キャスウェル
Tim Hoffmann +
Tim Swast
Tom Augspurger
Tommy +
Tulio Casagrande +
Tushar Gupta +
Tushar Mittal +
Upkar Lidder +
Victor Villas +
Vince W +
Vinícius Figueiredo +
Vipin Kumar +
WBare
Wenhuan +
ウェス・ターナー
ウィリアム・エイド
Wilson Lin +
Xbar
ヤロスラフ・ハルチェンコ
Yee Mey
Yeongseon Choe +
Yian +
Yimeng Zhang
ZhuBaohe +
Zihao Zhao +
adatasetaday +
akielbowicz +
akosel +
alinde1 +
amuta +
bolkedebruin
cbertinato
cgohlke
charlie0389 +
クリス・B1
csfarkas +
dajcs +
deflatSOCO +
derestle-htwg
discort
dmanikowski-reef +
donK23 +
elrubio +
fivemok +
fjdiod
fjetter +
froessler +
gabrielclow
ジーエフヤング
ghasemnaddaf
h-vetinari +
himanshu awasthi +
ignamv +
jayfoad +
jazzmuesli +
jbrockmendel
jen w +
jjames34 +
joaoavf +
joders +
jschendel
juan huguet +
l736x +
luzpaz +
mdeboc +
miguelmorin +
miker985
miquelcamprodon +
orereta +
ottiP +
peterpanmj +
rafarui +
raph-m +
readyready15728 +
rmihael +
samghelms +
scriptomation +
sfoo +
stefansimik +
stonebig
tmnhat2001 +
tomneep +
topper-123
tv3141 +
verakai +
xpvpc +
zhanghui +